Download as PDF, PPTX














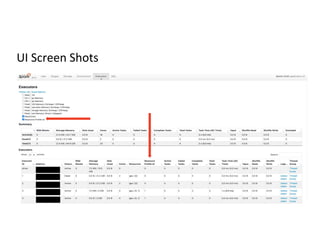





![Spark SQL & Dataframe Compilation Flow
DataFrame
Logical Plan
Physical Plan
bar.groupBy(
col(”product_id”),
col(“ds”))
.agg(
maxcol(“price”)) -
min(col(“p(rice”)).alias(“range”))
SELECT product_id, ds,
max(price) – min(price) AS
range FROM bar GROUP BY
product_id, ds
QUERY
GPU
PHYSICAL
PLAN
GPU Physical Plan
RAPIDS SQL
Plugin
RDD[InternalRow]
RDD[ColumnarBatch]](https://image.slidesharecdn.com/317thomasgraves-210616155355/85/Stage-Level-Scheduling-Improving-Big-Data-and-AI-Integration-27-320.jpg)











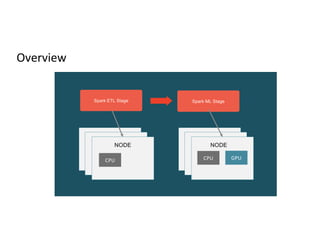
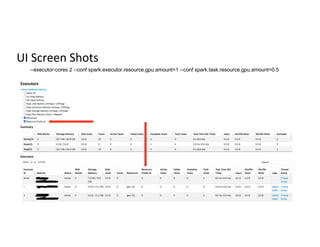
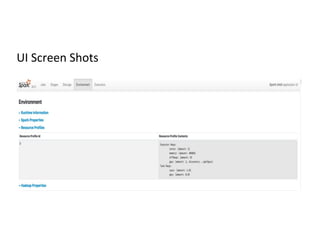
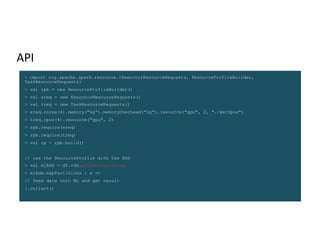
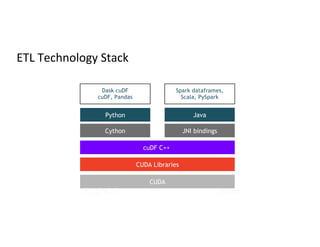
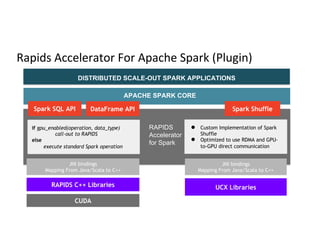
The document discusses stage-level scheduling and resource allocation in Apache Spark to enhance big data and AI integration. It outlines various resource requirements such as executors, memory, and accelerators, while presenting benefits like improved hardware utilization and simplified application pipelines. Additionally, it introduces the RAPIDS Accelerator for Spark and distributed deep learning with Horovod, emphasizing performance optimizations and future enhancements.























































































