Download as ODP, PPTX
![Всеволод Дёмкин [email_address] Новые нереляционные системы хранения данных](https://image.slidesharecdn.com/nosql-100401143146-phpapp02/85/slide-1-320.jpg)
![Всеволод Дёмкин [email_address] Новые нереляционные системы хранения данных](https://image.slidesharecdn.com/nosql-100401143146-phpapp02/75/slide-1-2048.jpg)


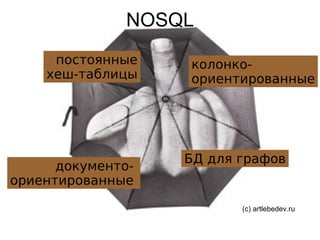


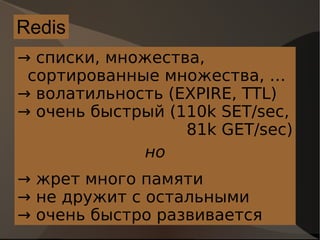








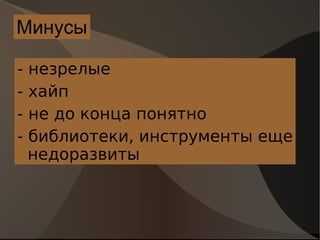


Документ обсуждает современные нереляционные системы хранения данных, их особенности и преимущества, такие как масштабируемость и производительность. Рассматриваются различные типы баз данных, включая колонко-ориентированные и документо-ориентированные, а также их применение в условиях высокой нагрузки. Подчеркиваются плюсы и минусы этих технологий, а также предоставляются ссылки на источники для дальнейшего изучения.



























































