











![General-Purpose Utils
(json:encode-json #{
"success" t
"sentence" text
"match"
(when-it (2nd (funcall fn (get-model text)))
(strcat
"{"
(strjoin ","
(mapcar #`(fmt ""~A":[~A,~A]"
(car %) (cadr %)
(cddr %))
(ht->alist it)))
"}"))
} stream)](https://image.slidesharecdn.com/cl-nlp-130701153558-phpapp02/85/CL-NLP-14-320.jpg)



![Basic Cell
(defclass regex-word-tokenizer (tokenizer)
((regex :accessor tokenizer-regex
:initarg :regex
:initform
(re:create-scanner
"w+|[!"#$%&'*+,./:;<=>?@^`~…()
{}[|] «»“”‘’¶-]"⟨⟩ ‒–—― )
:documentation
"A simpler variant would be [^s]+ —
it doesn't split punctuation, yet
sometimes it's desirable."))
(:documentation
"Regex-based word tokenizer."))](https://image.slidesharecdn.com/cl-nlp-130701153558-phpapp02/85/CL-NLP-18-320.jpg)




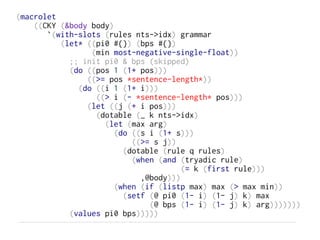


The document introduces cl-nlp, a natural language processing library for Common Lisp, outlining its motivation, high-level design, and essential functions. It discusses various components such as tokenization, parsing, and the creation of NLP pipelines, along with technical design choices and examples of usage. The document is aimed at leveraging Lisp for effective NLP applications and details future steps for development.




















































































