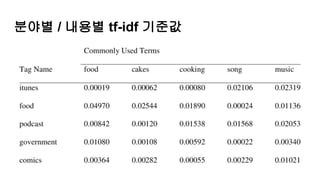
문제 제기해보기
파이썬 책을분석한 결과
for, if, import, return
토큰 갯수가 많이 등장한 경우,
이들 단어의 실제 중요도는?
11.
문제의 답
case1) 그Token 은 원래 많이 등장해서
변별력이 없어..
case 2) 그 Token 은 거의 등장하지 않는
단어인데, 여기선 많아 특이하네?
15.
1. Token 의중요도를 실수로 계산 (값이 클수록 중요)
2. TF는 해당 문서만 있으면 바로 연산이 가능하지만
3. IDF는 모집단의 Token 별 통계 데이터가 필요
상대빈도분석 - Term Frequency
Inverse Document Frequency
출처 : https://www.bloter.net/archives/264262
17.
1. 문서의 내용을쉽게 벡터로 표현하는 고전적 방식
2. Term Frequency : 해당 문서내 Token 발생빈도
>> (특정 Token 출현 수) / (문서 전체 Token 갯수)
3. Inverse Document Frequency : 전체문서 빈도 역
>> log (전체 문서 Token 수 / 특정 Token 수)
상대빈도분석 - Term Frequency
Inverse Document Frequency
18.
tf-idf 벡터
출처 :https://www.youtube.com/watch?v=bPYJi1E9xeM
19.
Jupyter Notebook 실습
>>02-4.Tf-idf_sklearn.ipynb
1. scikit-learn 모듈을 활용
2. konlpy, nltk 와 같이
scikit-learn의 자료를 활용