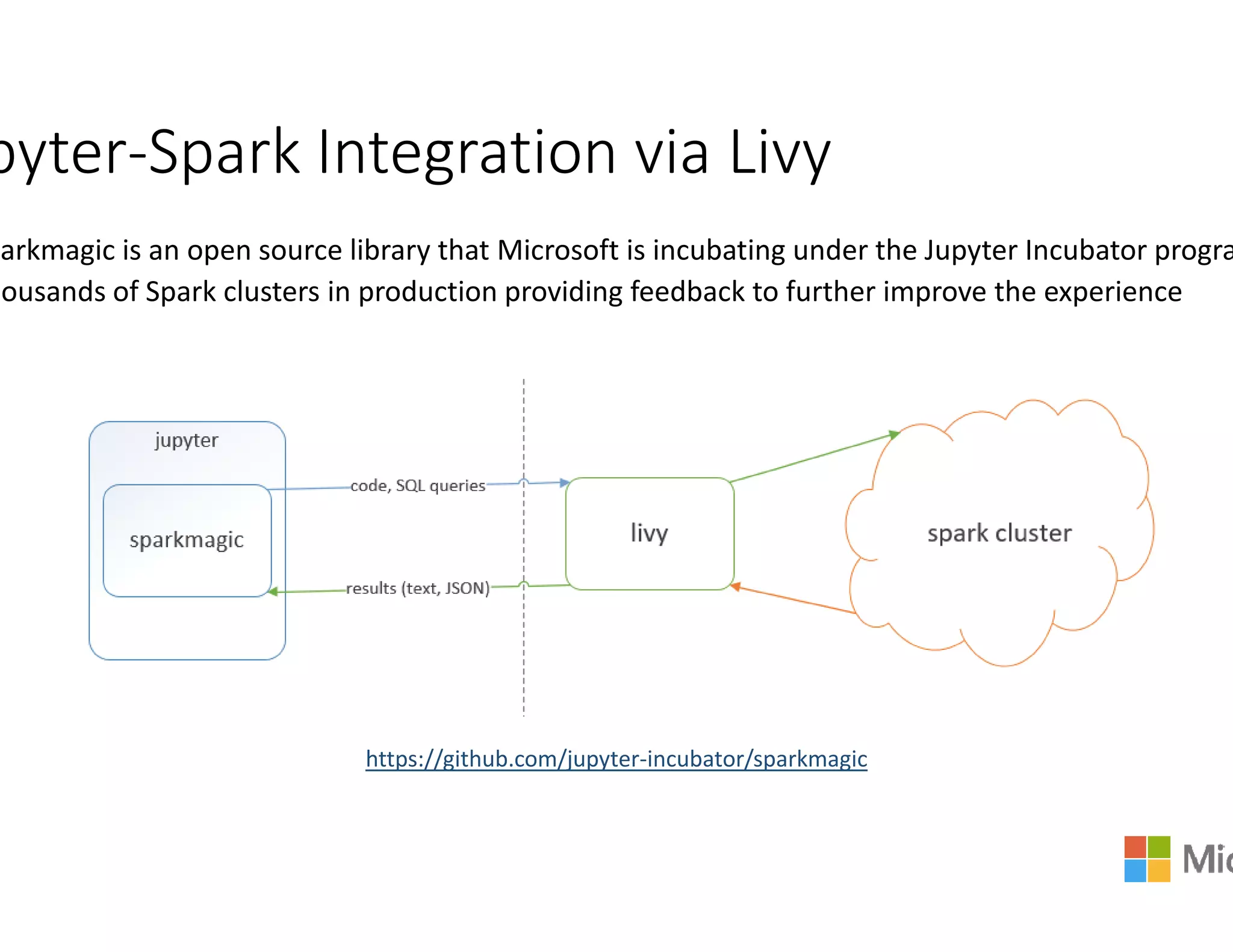
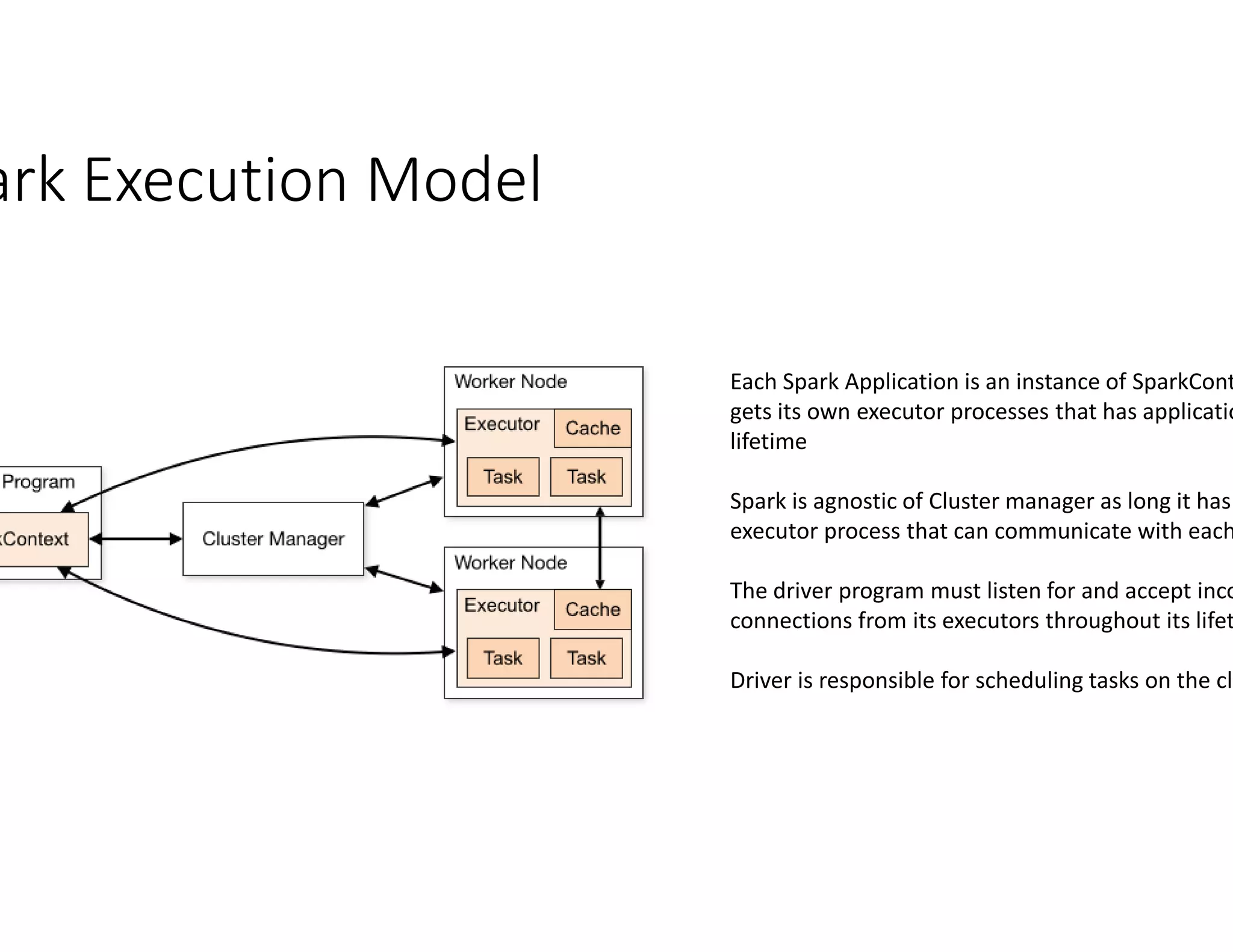
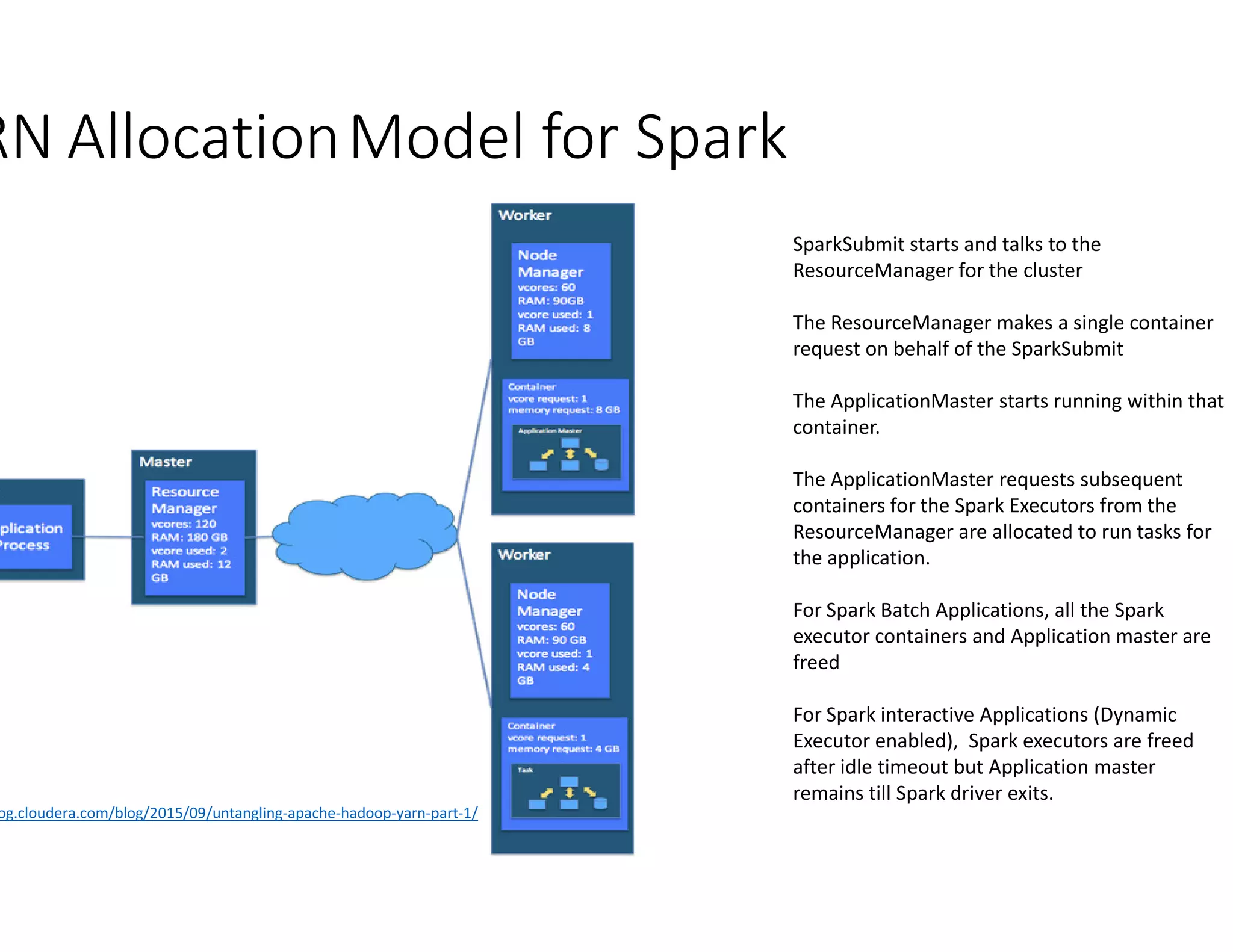
The document discusses the integration of Apache Spark with YARN (Yet Another Resource Negotiator) for managing multi-tenant clusters and optimizing resource allocation. It emphasizes Azure's managed Spark service that supports various ETL solutions, real-time visualization, and dynamic resource management to maximize cluster utilization. Moreover, it covers Spark's execution model, resource management policies, and configuration settings to improve performance and efficiency in cloud environments.


























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















