Downloaded 54 times









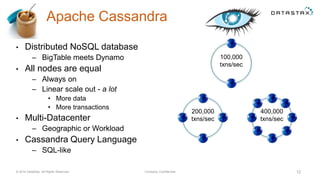
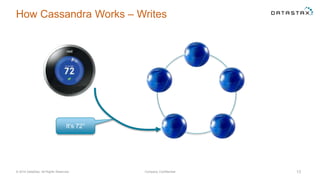

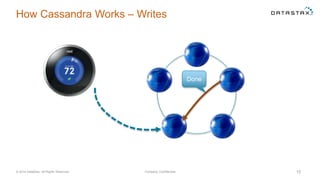
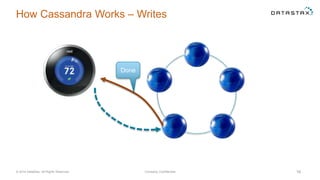

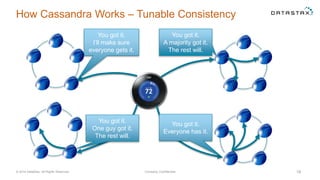
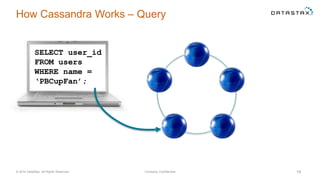
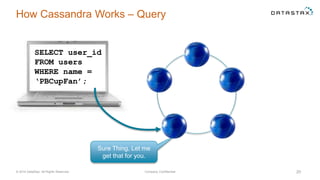
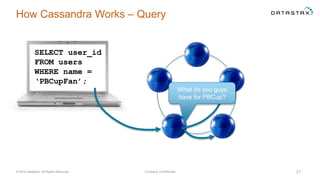
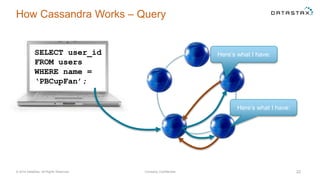
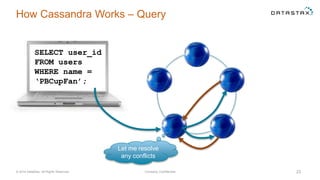
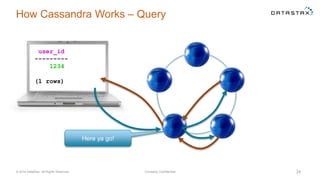
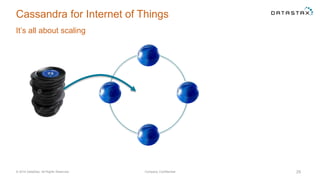
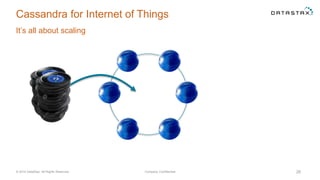



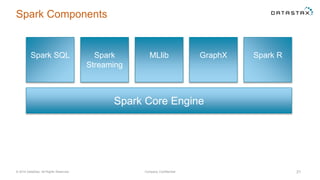
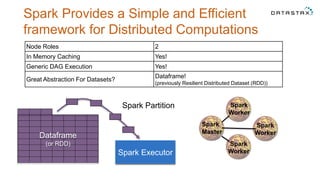
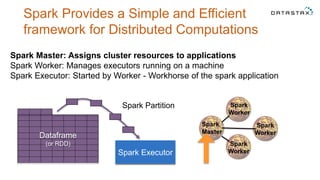
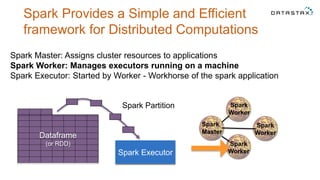
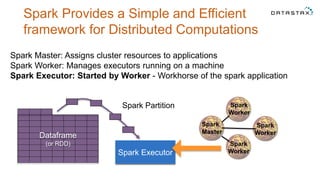



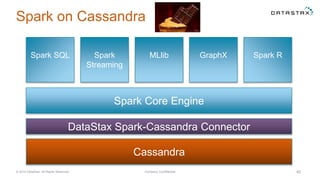
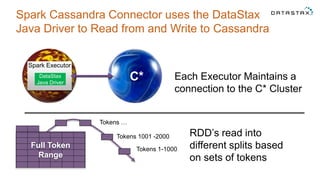
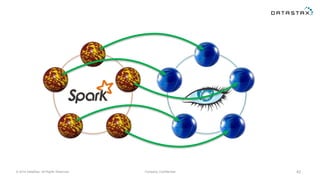
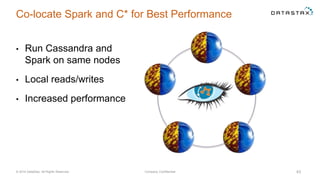



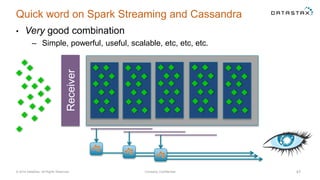

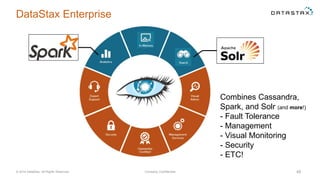





The document discusses a webinar on using Apache Cassandra and Spark for big data analytics, addressing technical difficulties during the presentation. It highlights Cassandra's capabilities as a distributed NoSQL database and outlines its advantages for Internet of Things applications due to its scalability and continuous availability. Additionally, it covers Apache Spark's distributed computing framework and integration with Cassandra for enhanced data analytics, including specific SQL functionalities that Cassandra alone cannot perform.








































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























































