Software defect prediction: do different classifiers find the same defects?
Bowes, D., Hall, T. & Petrić, J. Software defect prediction: do different classifiers find the same defects?. Software Qual J 26, 525–552 (2018). https://doi.org/10.1007/s11219-016-9353-3
Software defect prediction: do different classifiers find the same defects?
1.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects?
Software defect prediction: do different
classifiers find the same defects?
2020.03.12
최정환
1Jeongwhan Choi
2.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 2
Contents
• Introduction
• Background
• Methodology
• Results
• Discussion
• Conclusion
• My evaluation
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
3.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 3
Introduction
Jeongwhan Choi
Bowes, D., Hall, T. & Petrić, J. Software defect prediction: do different classifiers find the same defects?.
Software Qual J 26, 525–552 (2018). https://doi.org/10.1007/s11219-016-9353-3
Configuration
Bug Report
현재 연구
왜?
… SDP하고도 밀접하다고 생각
… 이 논문의 아이디어 적용 가능
… metrics 뿐만 아니라 같은 것을 예측하는지 분석
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
4.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 4
Introduction
• Object: SDP 잘 수행하는 classifier 식별
• Within-project에 초점
• 특정 defect의 관점에서 여러 classifier의 차이
• Prediction “flipping”의 영향을 분석
• 예측의 consistency는 classifier마다 다를 수 있음
• 예측 성능을 왜곡시킬 수 있는 “flipping” 효과를 피하기 위해 실험
충분히 여러 번 반복해야한다는 것을 보임
Jeongwhan Choi
Prediction
“flipping”
Prediction
Consistency
특정 defect의 관점
영향 분석 차이 분석
각 classfier 간에
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
5.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 5
Background
• WPDP(Within-Project Defect Prediction)
• 보통 Cross validation 사용하여 실험
• 안정적이고 일반화된 결과를 얻기 위해
• 보통 Recall, Precision 이용해서 전체 성능 수치에 초점
• Classifier에 의해 특정 결함이 누락되는지 여부를 알 수 없어서
à 제한적!
Jeongwhan Choi
단점: 안정적이지 않음
à classifier의 “flipping” 가능성
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
6.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 6
Background
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
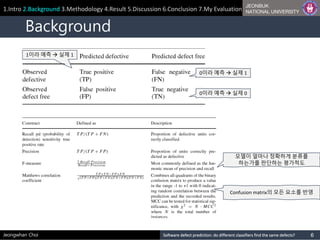
1이라 예측 à 실제 1
0이라 예측 à 실제 0
0이라 예측 à 실제 1
모델이 얼마나 정확하게 분류를
하는가를 판단하는 평가척도
Confusion matrix의 모든 요소를 반영
7.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 7
Classifiers
• 각기 다른 수학적 속성이 있기 때문에 아래 네가지 classifier를 사용
• Naïve Bayes
• 종속변수의 다른 범주와 연관된 종속 변수의 조합된 확률을 기반으로 모델
생성
• RPart
• Classification과 Regression Trees(CaRT)를 생성하는 기법
• 다른 독립 변수를 이용해 데이터를 분할해 달성할 수 있는 training data subse의
Information Entropy를 기반으로 Decision Tree 구출
• SVM
• Training data를 두 class로 분리 할 수 있는 hyper-plane 생성해 모델 구축
• Random Forest
• Ensemble 기법으로 많은 CaRT를 생성함으로써 구축
• 각각은 featur의 subset을 가진 training data의 샘플을 가지고 있음
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
순전히 확률론적, 각 독립변수가 결정에 기여
독립 변수의 subset만 사용하여 최종 tree 생성
가장 적은 FN&FP로 데이터를 분리하는 공식을 찾아 클리스 분리
최종 결정은 각 tree의 결정을 결합하고 modal 값을 계산해 결정
8.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 8
Datasets
Jeongwhan Choi
- 12 개의 NASA dataset
- 3개의 opensource dataset
- 3개의 commercial dataset
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
Summary statistics for datasets before and after cleaning
9.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 9
Experiment Set-up
• Stratified CV 사용하지 않음
• Data balance의 혼란스러운 요소 줄이기 위해
• 이는 사용된 classifier에 따라 실험에 영향 미침
• 실험은 classifier들간의 실제 data 기반으로 한 개별 예측의
분산에 초점
• F-measure & MCC 사용
• 각 classifier에 의해 예측된 결함을 각 모듈에 labelling하도록 설정
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
10.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 10
NASA dataset
Jeongwhan Choi
• Our results compared to results published by other studies
• 먼저, NASA dataset으로 model들이 적절히 예측하는지 확인
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
일부 dataset은 예측 어려움
11.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 11
MCC for all datasets
Jeongwhan Choi
• MCC performance for all datasets by classifier
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
RF 제외하고
Average 유사RPart, NB는 Commercial
dataset에서 잘 수행되지 않음
SVM: OSS
dataset에서 성능
안좋음
이러한 전체 performance 수치는 개별 dataset에서 사용될때 classifier별로 다양한 performance 범위를 숨김
12.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 12
MCC for KC4, KN, and Ivy
• Performance measures for KC4, KN and Ivy
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
NB는 Ivy, KC4에서 상대적으로
잘 예측
SVM은 KN dataset에서 최고
성능
13.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 13
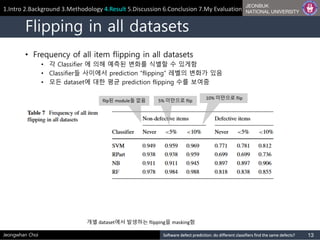
Flipping in all datasets
• Frequency of all item flipping in all datasets
• 각 Classifier 에 의해 예측된 변화를 식별할 수 있게함
• Classifier들 사이에서 prediction “flipping” 레벨의 변화가 있음
• 모든 dataset에 대한 평균 prediction flipping 수를 보여줌
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
개별 dataset에서 발생하는 flipping을 masking함
5% 미만으로 flip
10% 미만으로 flip
flip된 module들 없음
14.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 14
Flipping – dataset categories
• Frequency of all items flipping across different dataset categories
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
Defective items의 71.7%가
flipped되지 않음
Defective items의 74.6%가 5%
미만으로 flipped
15.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 15
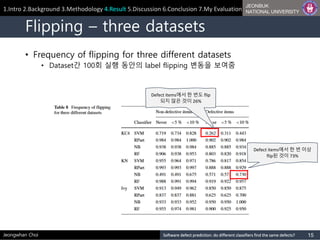
Flipping – three datasets
• Frequency of flipping for three different datasets
• Dataset간 100회 실행 동안의 label flipping 변동을 보여줌
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
Defect items에서 한 번도 flip
되지 않은 것이 26%
Defect items에서 한 번 이상
flip된 것이 73%
16.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 16
Violin plot
• Violin plot of frequency of flipping for KC4 dataset
• KC4의 다른 classifier에 대한 flipping을 보여주는 violin plot
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
X-axis: flip하는 모듈의 비율
Y-axis: module이 flipping될 확률
넓은 violin: 높은 비율의 module
Violin의 중앙 부분은 flipping될
확률 50%
SVM: 불안정(중앙 부분 넓음)
NB: 큰 안정성(대부분
module이 끝에 위치)
RPart: Defective 클래스에서
안정적
17.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 17
Set diagram (1)
• Sensitivity analysis for all NASA datasets using different classifiers
• 각 개별 classifier의 성능은 각 사분면에 해당하는 예측 수로 표시
• 각 classifier에서 결함 유무로 예측된 실제 module의 유사성과 변화를 보여줌
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
SVM: 125(8.0%) 결함 모듈을
올바르게 찾음
1569개 중 96개의 결함
모듈(6.1%)이 모든 classifier에
의해 결함으로 올바르게 예측
NB: 280(0.7%) 결함 모듈을
올바르게 찾음
모든 classifier: 모두 37,953
개의 TN의 NASA 모듈 중
35,364(93.1%)에 agree
SVM: 100개의 비결함 모듈을
정확하게 예측
비결함
모듈은 특정
classifier에
의해 위치
Classifier 전체의 모듈 예측 패턴은 dataset마다 다름
18.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 18
Set diagram (2)
• Sensitivity analysis for all open source datasets using different
classifiers
• 283개 중 55개(10.4%)의 고유한 결함이 NB 또는 SVM으로 식별
• Sensitivity analysis for all commercial datasets using different classifiers
• 1,027개 중 357개가 고유한 결함(34.8%)
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
19.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 19
Set diagram (3)
• Sensitivity analysis for KC4 using different classifiers
• NB는 다른 dataset에 대한 예측보다 optimistic 예측이 더 적음(125개 중 17개)
• Sensitivity analysis for KN using different classifiers
• RPart는 비결함 항목보다 결함 항목을 예측할 때 더 보수적
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
RPart: 17(15.3%)의
고유한 결함 찾음
20.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 20
Discussion
• 실험 결과로부터 classifier에 의한 예측에 불확실성이 있음
• Prediction “flipping”이 Cross Validation 실행 동안 있음을 보임
• 일반적인 연구는 평균 최종 예측 수치만을 발표하기에 이러한 불확실성
수준은 관찰할 수 없음
• 예측 불확실성의 이유에 대한 부분은 향후 연구가 필요
• 다른 classifier에 의해 실제로는 매우 다른 defect들이 예측됨
• Ensemble 사용을 제안
• 단, “majority” 투표 방법보다는 Stacking 방식
• 개별 classifier가 예측하는 고유한 defect들을 누락할 수 있기에
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
21.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 21
Threats to validity
• Data Imbalance
• 데이터 불균형을 해결하는 기술은 구현하지 않음 (e.g. SMOTE)
• 데이터 불균형이 모든 classifier에 동일하게 영향을 주지 않기에
• 부분 feature 축소만 구현
• 단지 4개의 classifier만을 분석한다는 점에서 제한적
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
22.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 22
Conclusion
• Cross validation을 100 번 반복
à 같은 모델에 의해 결함 유무에 대한 많은 불일치를 발견
• 유사한 성능 수치의 SDP model들의 경우, 다른 classifier는 다른
defect를 예측 à 이는 SDP에 중요한 영향을 미침
• classifier 하나만 사용하는 경우 결함을 포괄적으로 감지하지 못할 수
있음
• Ensemble의 ‘majority’ voting 방법은 단일 classifier가 올바르게 예측하는
결함의 상당 부분을 놓칠 수 있음
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
23.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 23
My Evaluation
• What problems does the paper address?
• 성능 수치로만 model 비교하는데, 이들이 같은
• What are the main conclusions of the paper?
• 여러 모델 사용해라~ Ensemble! 단, majority voting 말고
• What evidence supports the conclusion?
• Confusion Matrix를 set diagram으로 표현 후 분석 / “flipping” 레벨 분석
• Do the data support the conclusions?
• 많이 사용된 NASA, OSS, Commercial dataset 사용 / 몇몇 프로젝트 데이터는 작음
• What is the quality of the evidence?
• 나쁘지 않지만, 각 classifier 예측하는 defect들이 어떤 유사성이 있는지는 모름
• Why are the conclusions important?
• 일반적인 연구의 성능 평가에서는 이런 분석을 찾아볼 수 없음
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
24.
JEONBUK
NATIONAL UNIVERSITY
Software defectprediction: do different classifiers find the same defects? 24
My Evaluation
• 내 연구에 어떻게 적용할 수 있는지?
• 현재 6개의 프로젝트를 데이터셋으로 사용
• 이 방법을 적용하여, 각 classifier들의 성능을 비교할 때, 같은 Bug Report를
어떻게 예측하는지 분석할 수 있음
• 뿐만 아니라, 다른 연구에서도 model들의 예측 성능 비교할 때,
적용하여 평가/분석 가능
Jeongwhan Choi
1.Intro 2.Background 3.Methodology 4.Result 5.Discussion 6.Conclusion 7.My Evaluation
































![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[125] 머신러닝으로 쏟아지는 유저 cs 답변하기](https://cdn.slidesharecdn.com/ss_thumbnails/25cs-171016061055-thumbnail.jpg?width=640&height=640&fit=bounds)






![[KAIA2021] Graph-based Collaborative Filtering and Neural ODEs](https://cdn.slidesharecdn.com/ss_thumbnails/a7js83agtzaovjxyprgq-kaia2021tutorial-lt-ocf-221019003243-c00be3eb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Yonsei AI Workshop 2022] Graph Neural Controlled Differential Equations for ...](https://cdn.slidesharecdn.com/ss_thumbnails/dhcx9l1rc2acdkwbnqyx-aaai22-workshop-221019003243-979010ab-thumbnail.jpg?width=640&height=640&fit=bounds)


