Download to read offline






































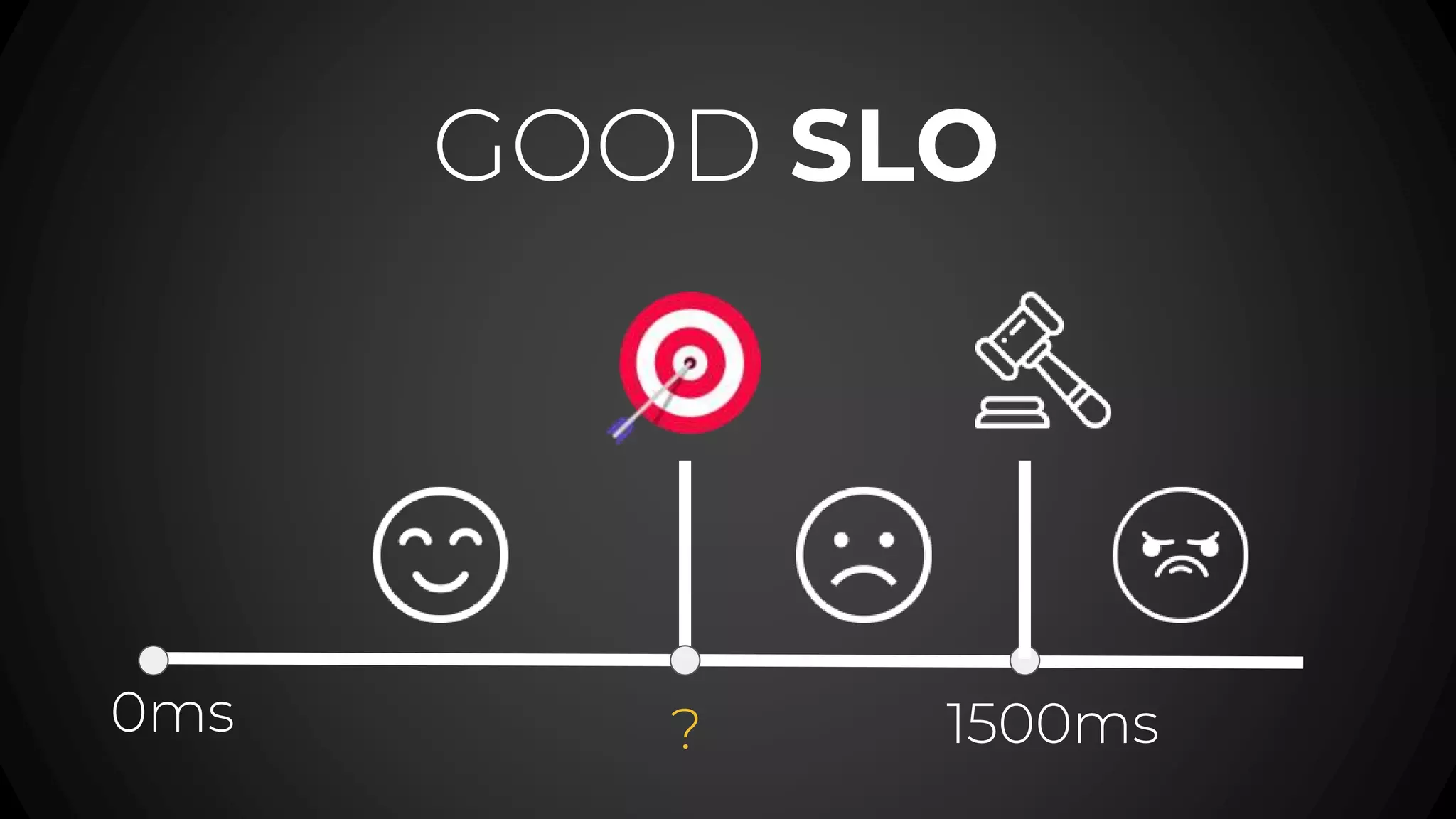
















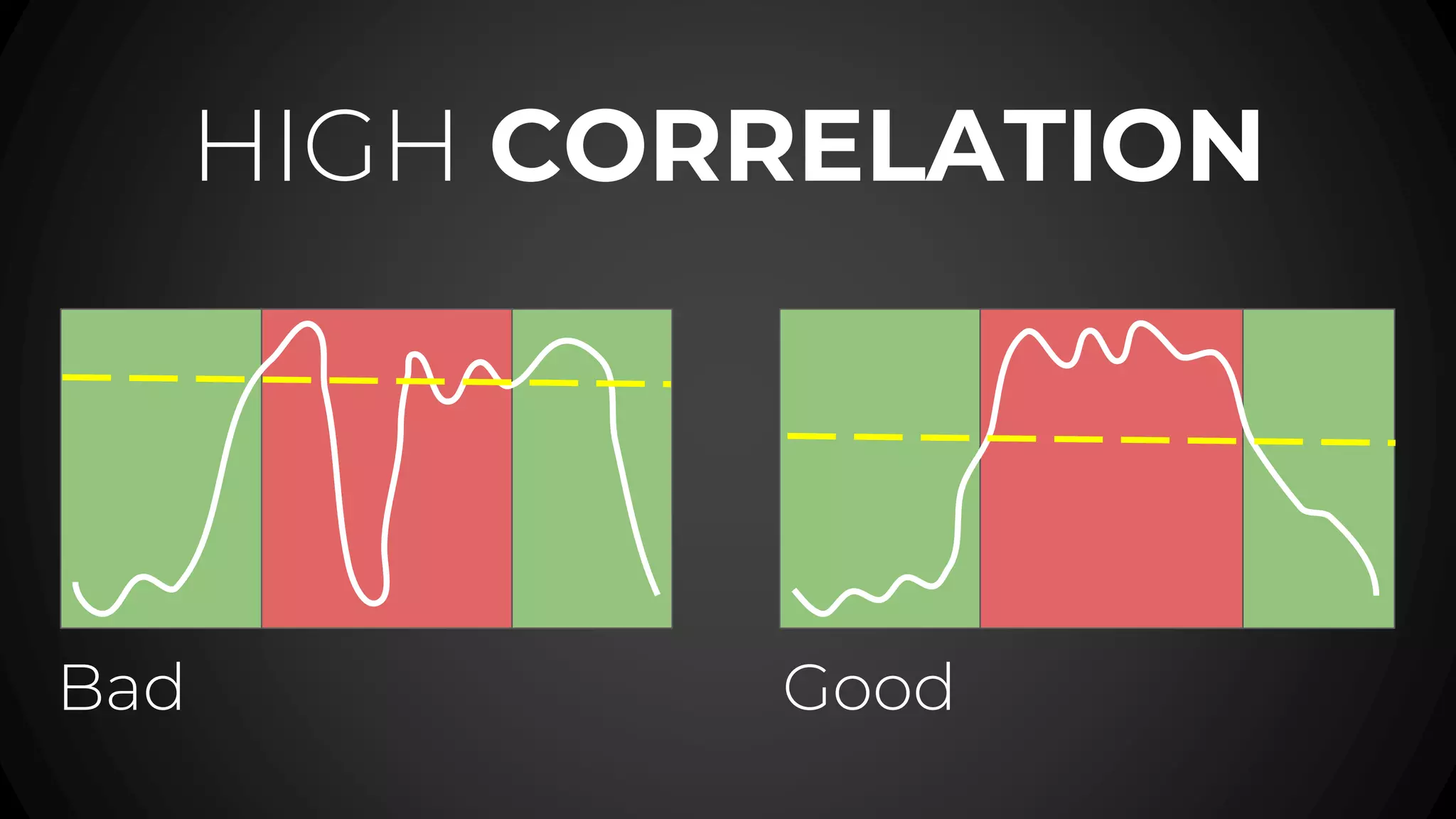



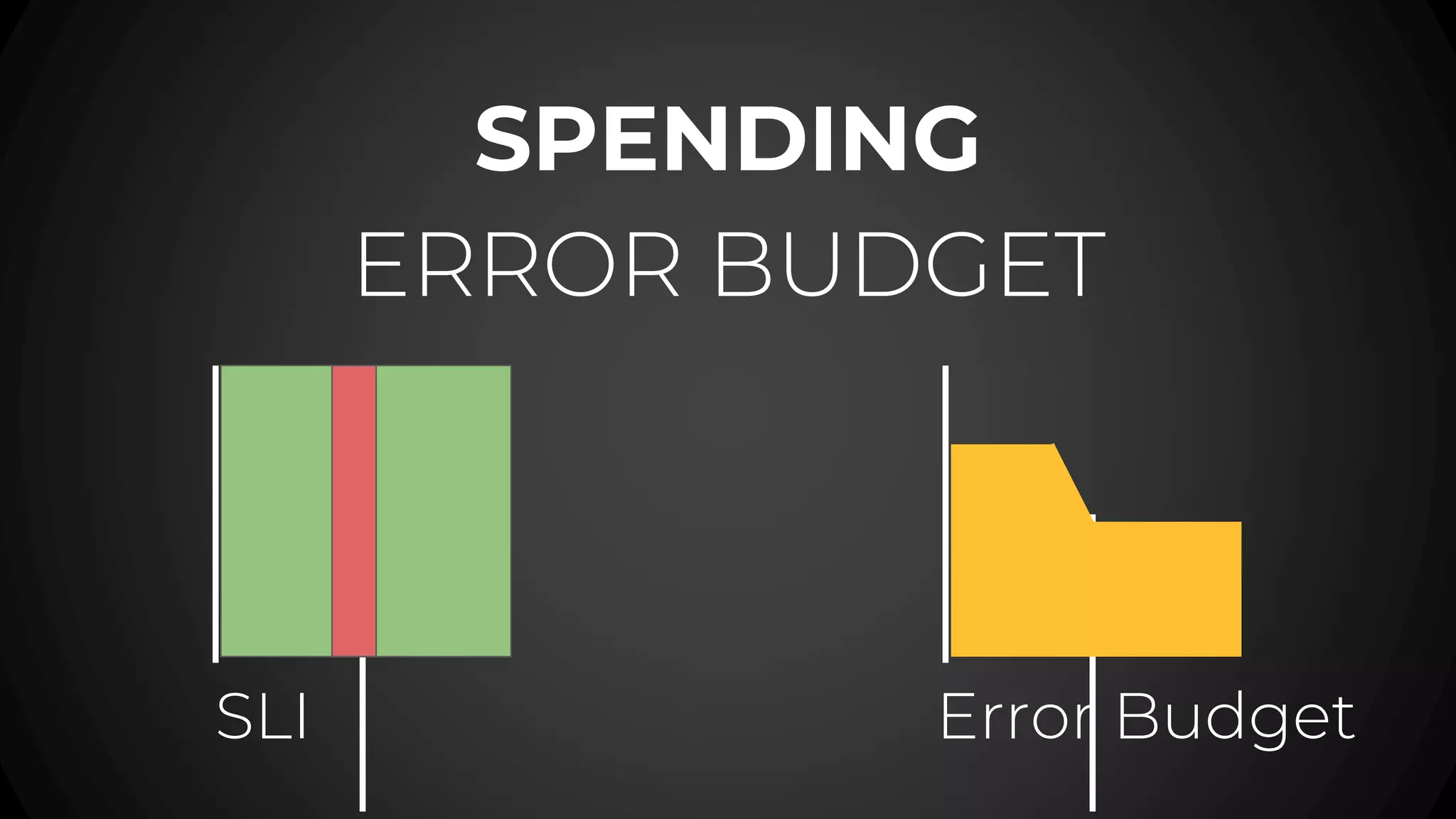
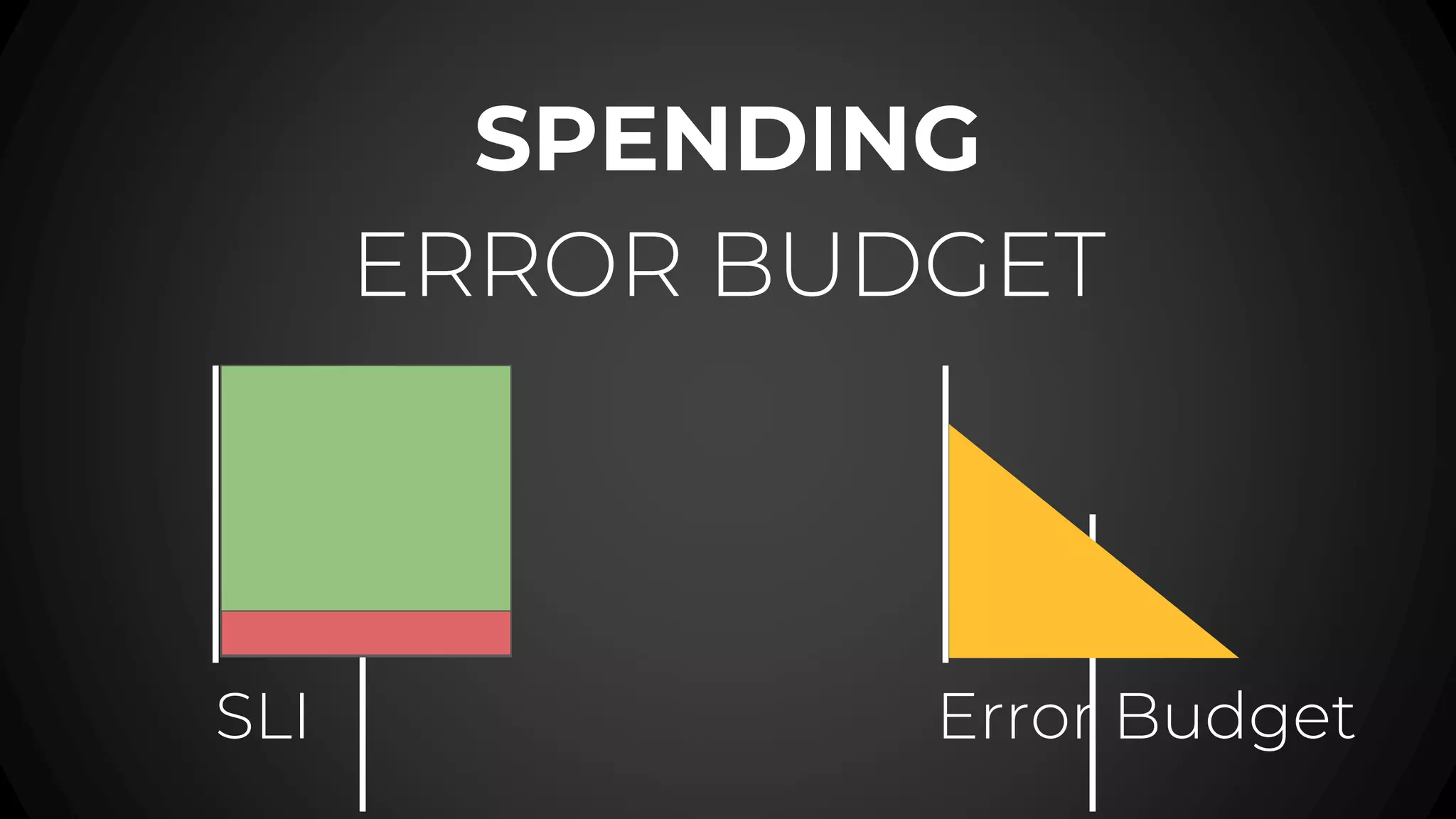







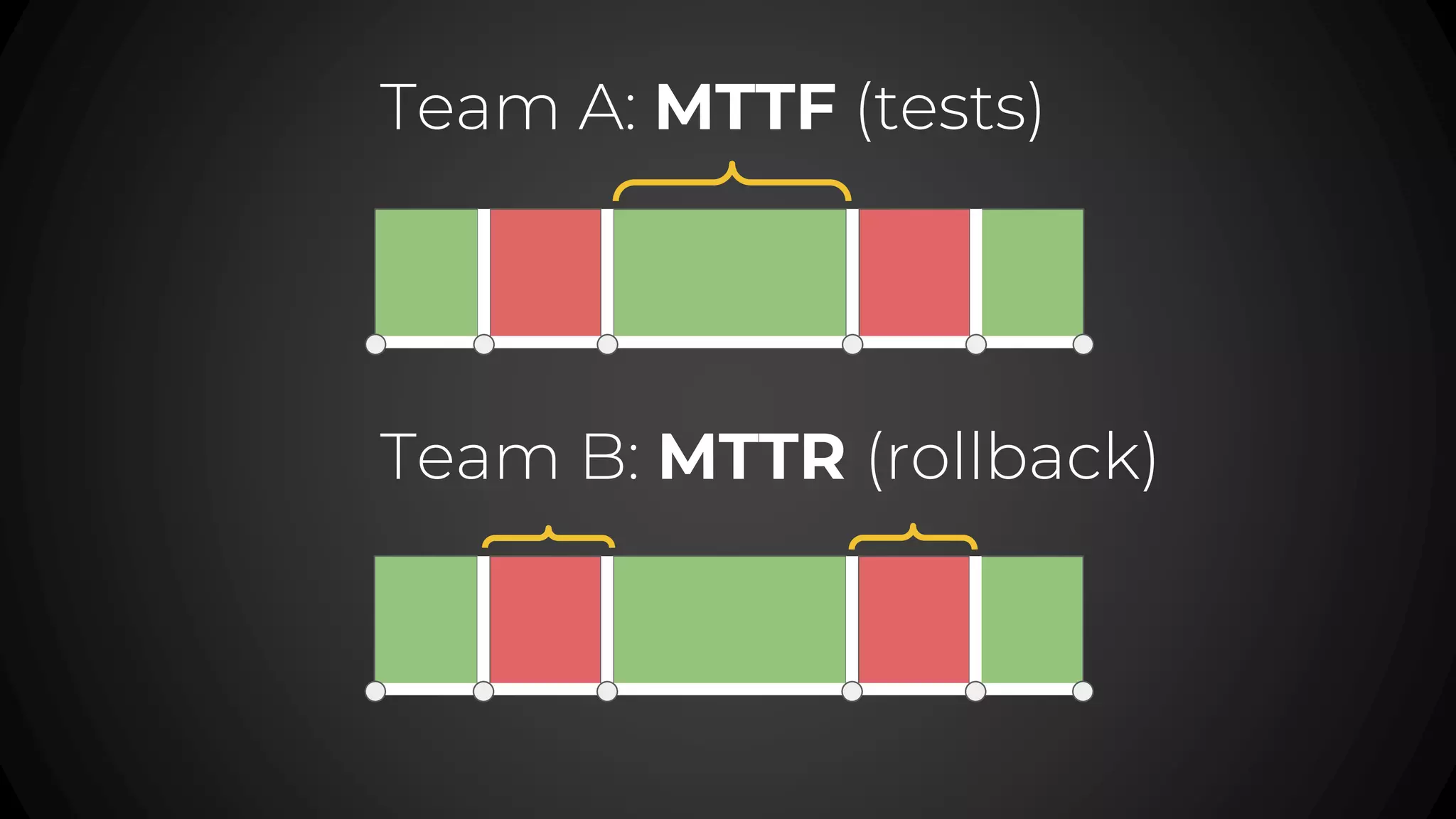
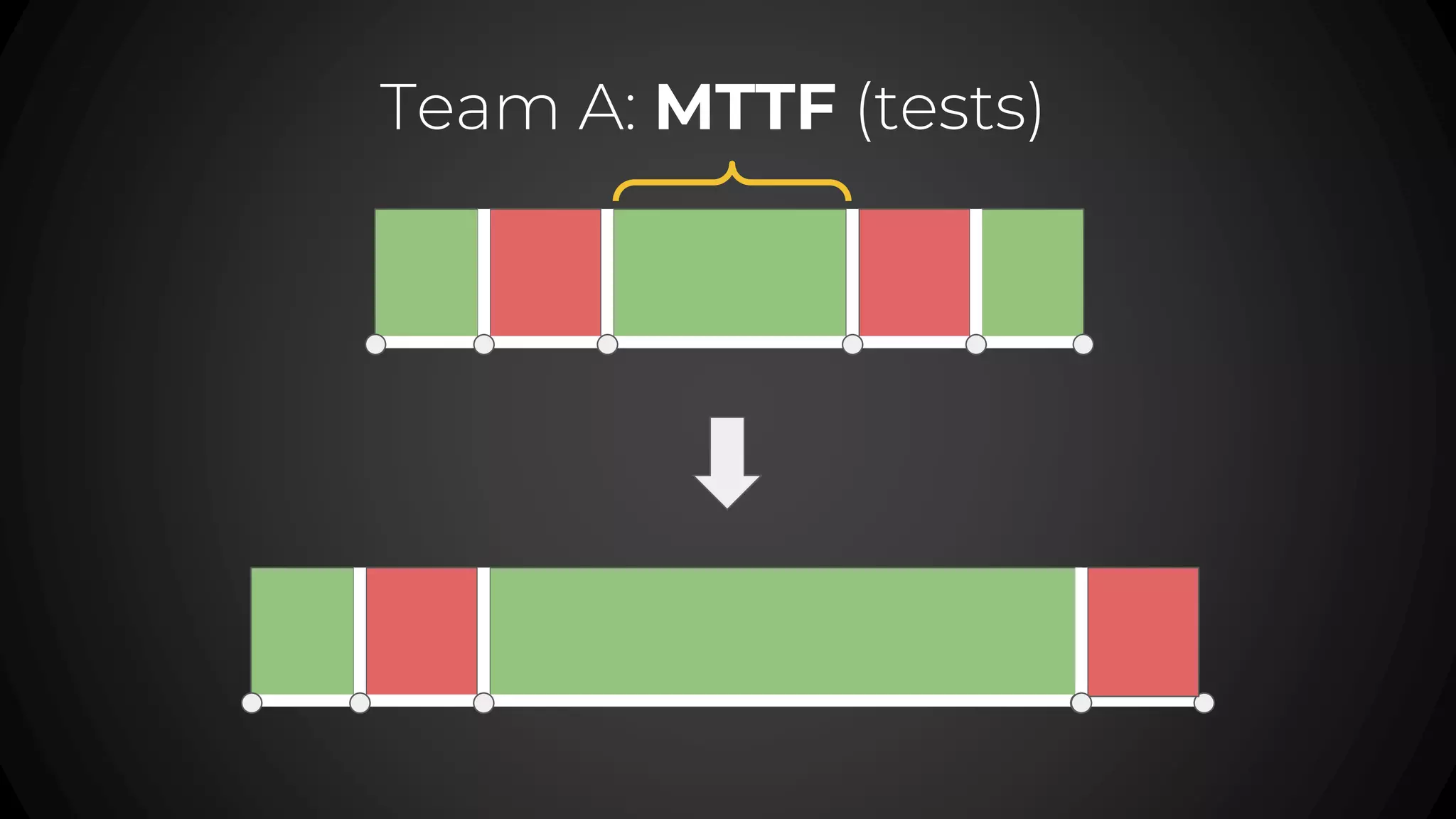









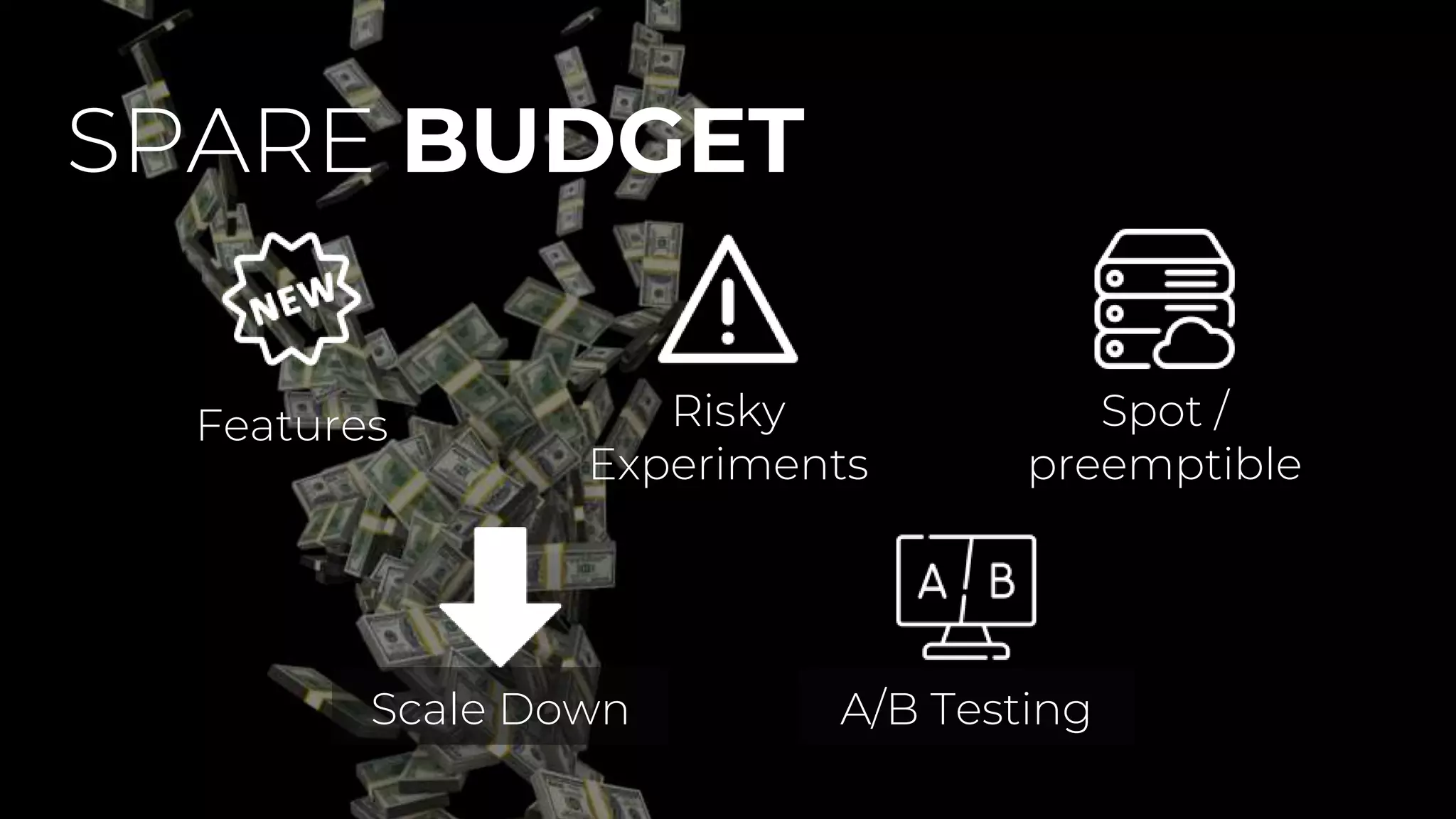




















The document discusses service level objectives (SLOs) and agreements (SLAs) focusing on system reliability and its impact on costs, velocity, and architecture. It emphasizes the importance of measurable data for improving reliability and lists various metrics and practices for achieving good SLOs, such as error budgets. Additionally, it highlights the trade-offs involved in budget management for maintaining high reliability standards.










































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












