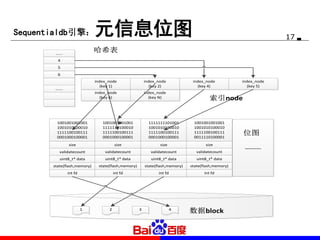
本文介绍了 seqdb 存储引擎的设计与性能,针对不同业务需求提出了改进方案及架构部署情况。该引擎能够支持高并发读取和写入,满足 SLA 要求,并在实际应用中展示了良好的性能。文中还提到索引管理、垃圾回收机制和在线部署经验。






























































![内存数据库[1]](https://cdn.slidesharecdn.com/ss_thumbnails/1-120520044455-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




