Download as PDF, PPTX






![Full Code
require 'csv'!
require 'princely'!
require 'zip/zip’!
!
DATA_FILE = ARGV[0]!
DATA_FILE_BASE_NAME = File.basename(DATA_FILE, ".csv”)!
!
# create a pdf document from a csv line!
def create_pdf(invoice_nr, name, street, zip, city)!
template = File.new('../resources/invoice.html').read!
html = eval("<<WTFMFn#{template}nWTFMF")!
p = Princely.new!
p.add_style_sheets('../resources/invoice.css')!
p.pdf_from_string(html)!
end!
!
# zip files from hash !
def create_zip(files_h)!
zipfile_name = "../out/#{DATA_FILE_BASE_NAME}.#{Time.now.to_s}.zip"!
Zip::ZipOutputStream.open(zipfile_name) do |zos|!
files_h.each do |name, content|!
zos.put_next_entry "#{name}.pdf"!
zos.puts content!
end!
end!
zipfile_name!
end!
!
# load data from csv!
docs = CSV.read(DATA_FILE) # array of arrays!
!
# create a pdf for each line in the csv !
# and put it in a hash!
files_h = docs.inject({}) do |files_h, doc|!
files_h[doc[0]] = create_pdf(*doc)!
files_h!
end!
!
# zip all pfd's from the hash !
create_zip files_h!
!](https://image.slidesharecdn.com/rubyonredisoct2013-131015045112-phpapp02/75/Ruby-on-Redis-7-2048.jpg)






![Hello Redis
‣ redis-cli
•
•
•
•
set name “pascal” =
“pascal”
incr counter = 1
incr counter = 2
hset pascal name
“pascal”
•
hset pascal address
“merelbeke”
•
•
sadd persons pascal
smembers persons =
[pascal]
•
•
•
•
•
•
•
keys *
type pascal = hash
lpush todo “read” = 1
lpush todo “eat” = 2
lpop todo = “eat”
rpoplpush todo done =
“read”
lrange done 0 -1 =
“read”](https://image.slidesharecdn.com/rubyonredisoct2013-131015045112-phpapp02/75/Ruby-on-Redis-17-2048.jpg)
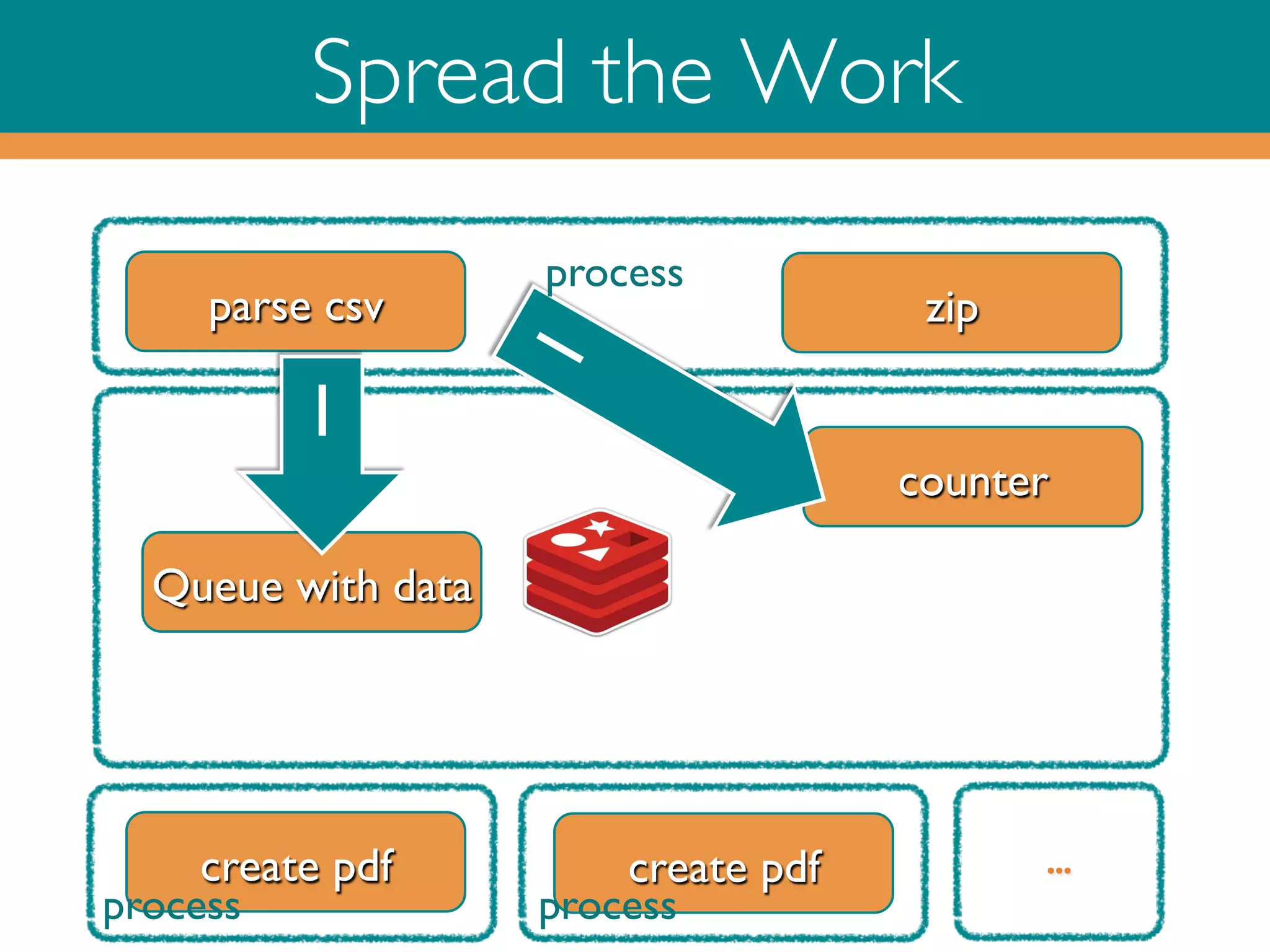

![Ruby on Redis
‣
Read PDF input data from Queue and do the counter bookkeeping
and put each created PDF in a Redis hash and signal if ready
while (true)!
_, msg = r.brpop 'pdf:queue’!
!doc = YAML::load(msg)!
#name of hash, key=docname, value=pdf!
r.hset(‘pdf:pdfs’, doc[0], create_pdf(*doc))
!
ctr = r.decr ‘ctr’
!
r.rpush ready, done if ctr == 0!
end!](https://image.slidesharecdn.com/rubyonredisoct2013-131015045112-phpapp02/75/Ruby-on-Redis-22-2048.jpg)

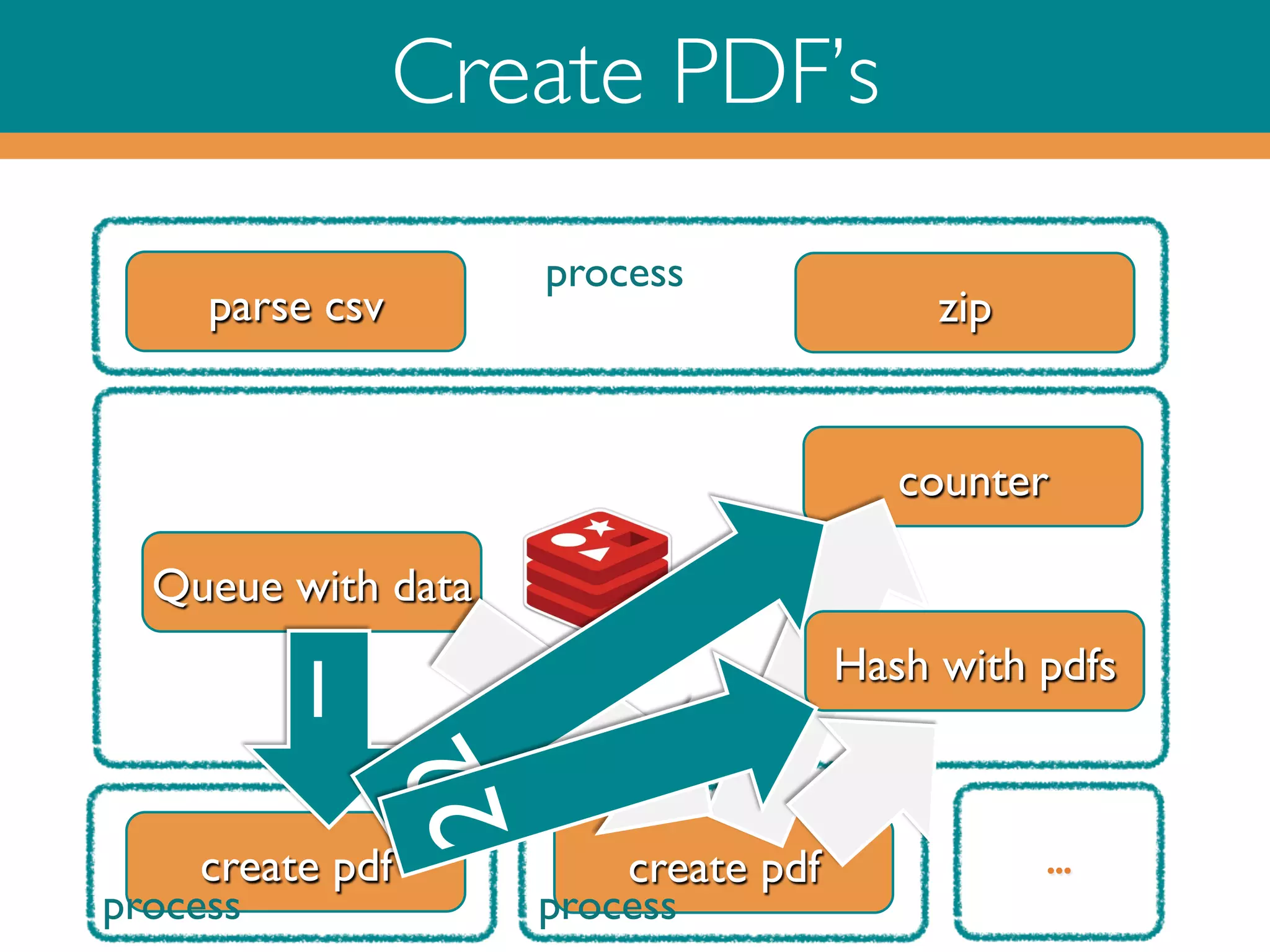
![Ruby on Redis
‣
Put PDF Create Input data on a Queue and do the counter
bookkeeping
# unique id for this input file!
UUID = SecureRandom.uuid!
docs.each do |doc|!
data = YAML::dump([UUID, doc])!
!r.lpush 'pdf:queue’, data!
r.incr ctr:#{UUID}” # bookkeeping!
end!](https://image.slidesharecdn.com/rubyonredisoct2013-131015045112-phpapp02/75/Ruby-on-Redis-26-2048.jpg)
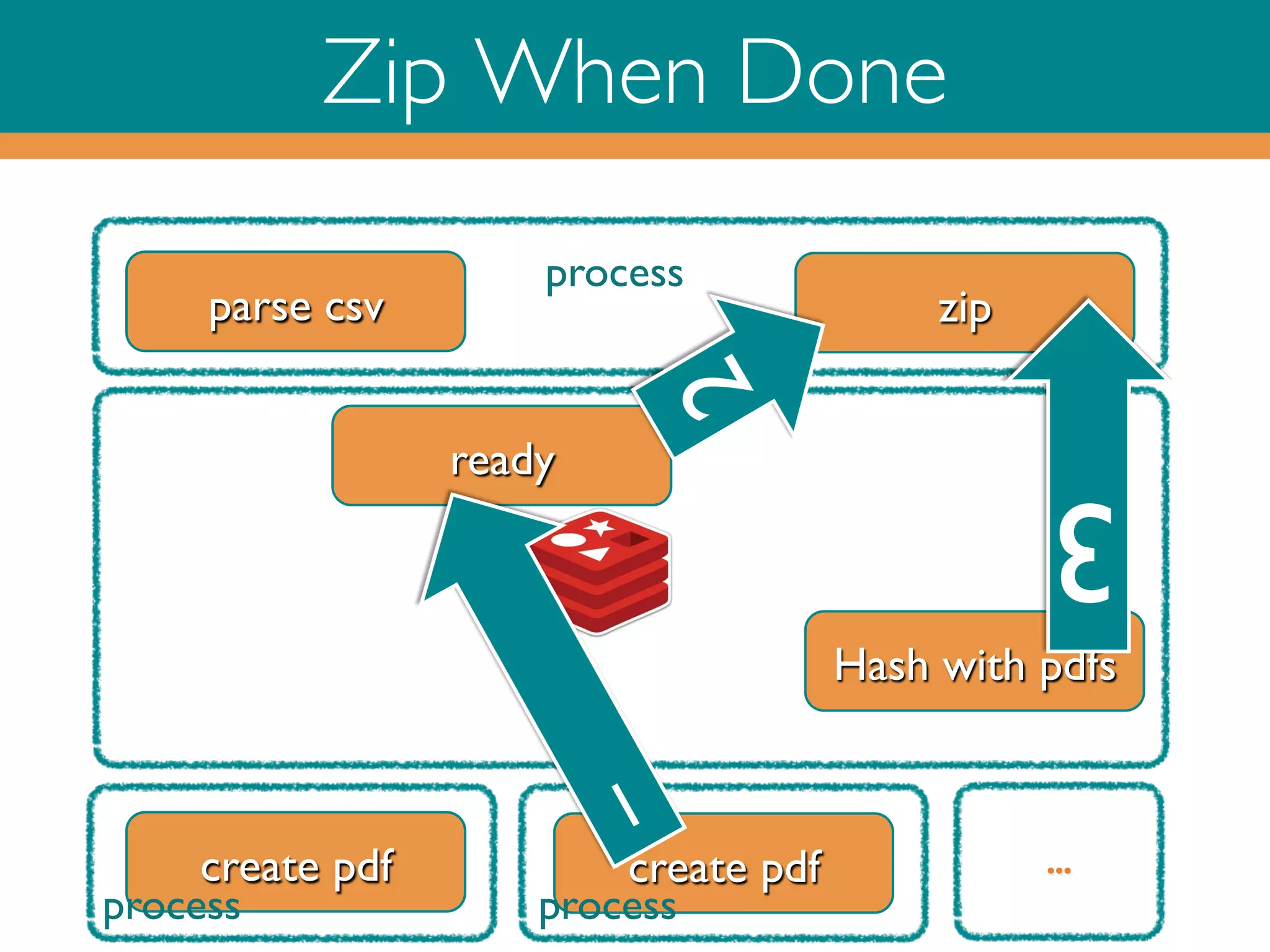
![Ruby on Redis
‣
Read PDF input data from Queue and do the counter bookkeeping and
put each created PDF in a Redis hash
while (true)!
_, msg = r.brpop 'pdf:queue’!
uuid, doc = YAML::load(msg)!
r.hset(uuid, doc[0], create_pdf(*doc))!
ctr = r.decr ctr:#{uuid}
!
r.rpush ready:#{uuid}, done if ctr == 0
end!
!](https://image.slidesharecdn.com/rubyonredisoct2013-131015045112-phpapp02/75/Ruby-on-Redis-27-2048.jpg)

![Full Code
require 'csv'!
require 'princely'!
require 'zip/zip’!
!
DATA_FILE = ARGV[0]!
DATA_FILE_BASE_NAME = File.basename(DATA_FILE, .csv”)!
!
# create a pdf document from a csv line!
def create_pdf(invoice_nr, name, street, zip, city)!
template = File.new('../resources/invoice.html').read!
html = eval(WTFMFn#{template}nWTFMF)!
p = Princely.new!
p.add_style_sheets('../resources/invoice.css')!
p.pdf_from_string(html)!
end!
!
# zip files from hash !
def create_zip(files_h)!
zipfile_name = ../out/#{DATA_FILE_BASE_NAME}.#{Time.now.to_s}.zip!
Zip::ZipOutputStream.open(zipfile_name) do |zos|!
files_h.each do |name, content|!
zos.put_next_entry #{name}.pdf!
zos.puts content!
end!
end!
zipfile_name!
end!
!
# load data from csv!
docs = CSV.read(DATA_FILE) # array of arrays!
!
# create a pdf for each line in the csv !
# and put it in a hash!
files_h = docs.inject({}) do |files_h, doc|!
files_h[doc[0]] = create_pdf(*doc)!
files_h!
end!
!
# zip all pfd's from the hash !
create_zip files_h!
!
LINEAR
require 'csv’!
require 'zip/zip'!
require 'redis'!
require 'yaml'!
require 'securerandom'!
!
# zip files from hash !
def create_zip(files_h)!
zipfile_name = ../out/#{DATA_FILE_BASE_NAME}.#{Time.now.to_s}.zip!
Zip::ZipOutputStream.open(zipfile_name) do |zos|!
files_h.each do |name, content|!
zos.put_next_entry #{name}.pdf!
zos.puts content!
end!
end!
zipfile_name!
end!
!
DATA_FILE = ARGV[0]!
DATA_FILE_BASE_NAME = File.basename(DATA_FILE, .csv)!
UUID = SecureRandom.uuid!
!
r = Redis.new!
my_counter = ctr:#{UUID}!
!
# load data from csv!
docs = CSV.read(DATA_FILE) # array of arrays!
!
docs.each do |doc| # distribute!!
r.lpush 'pdf:queue' , YAML::dump([UUID, doc])!
r.incr my_counter!
end!
!
r.brpop ready:#{UUID} #collect!!
create_zip(r.hgetall(UUID)) !
!
# clean up!
r.del my_counter!
r.del UUID !
puts All done!”!
MAIN
require 'redis'!
require 'princely'!
require 'yaml’!
!
# create a pdf document from a csv line!
def create_pdf(invoice_nr, name, street, zip, city)!
template = File.new('../resources/invoice.html').read!
html = eval(WTFMFn#{template}nWTFMF)!
p = Princely.new!
p.add_style_sheets('../resources/invoice.css')!
p.pdf_from_string(html)!
end!
!
r = Redis.new!
while (true)!
_, msg = r.brpop 'pdf:queue'!
uuid, doc = YAML::load(msg)!
r.hset(uuid , doc[0] , create_pdf(*doc))!
ctr = r.decr ctr:#{uuid} !
r.rpush ready:#{uuid}, done if ctr == 0!
end!
WORKER
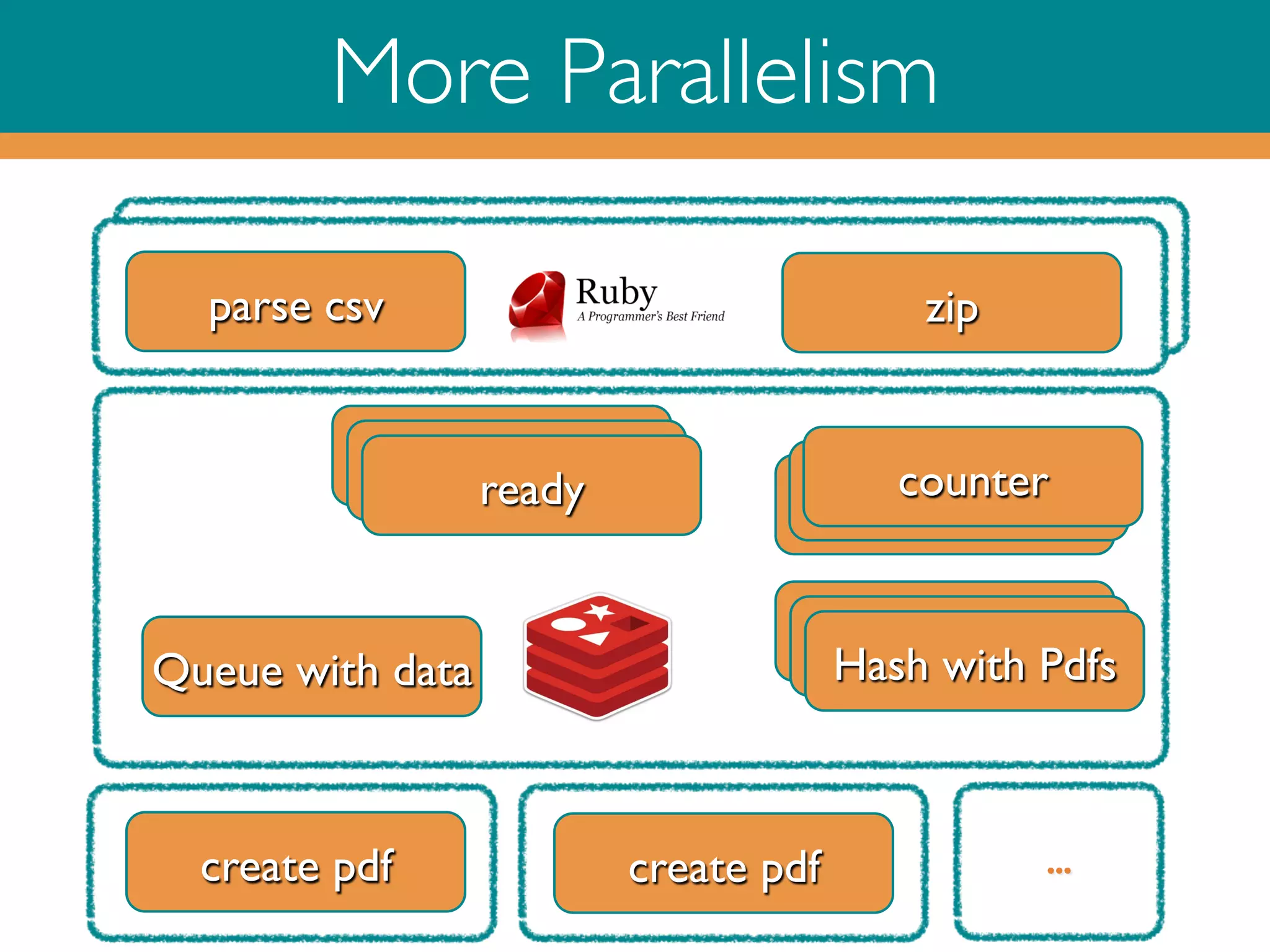
Key functions (create pdf and create zip)
remain unchanged.
Distribution code highlighted](https://image.slidesharecdn.com/rubyonredisoct2013-131015045112-phpapp02/75/Ruby-on-Redis-29-2048.jpg)



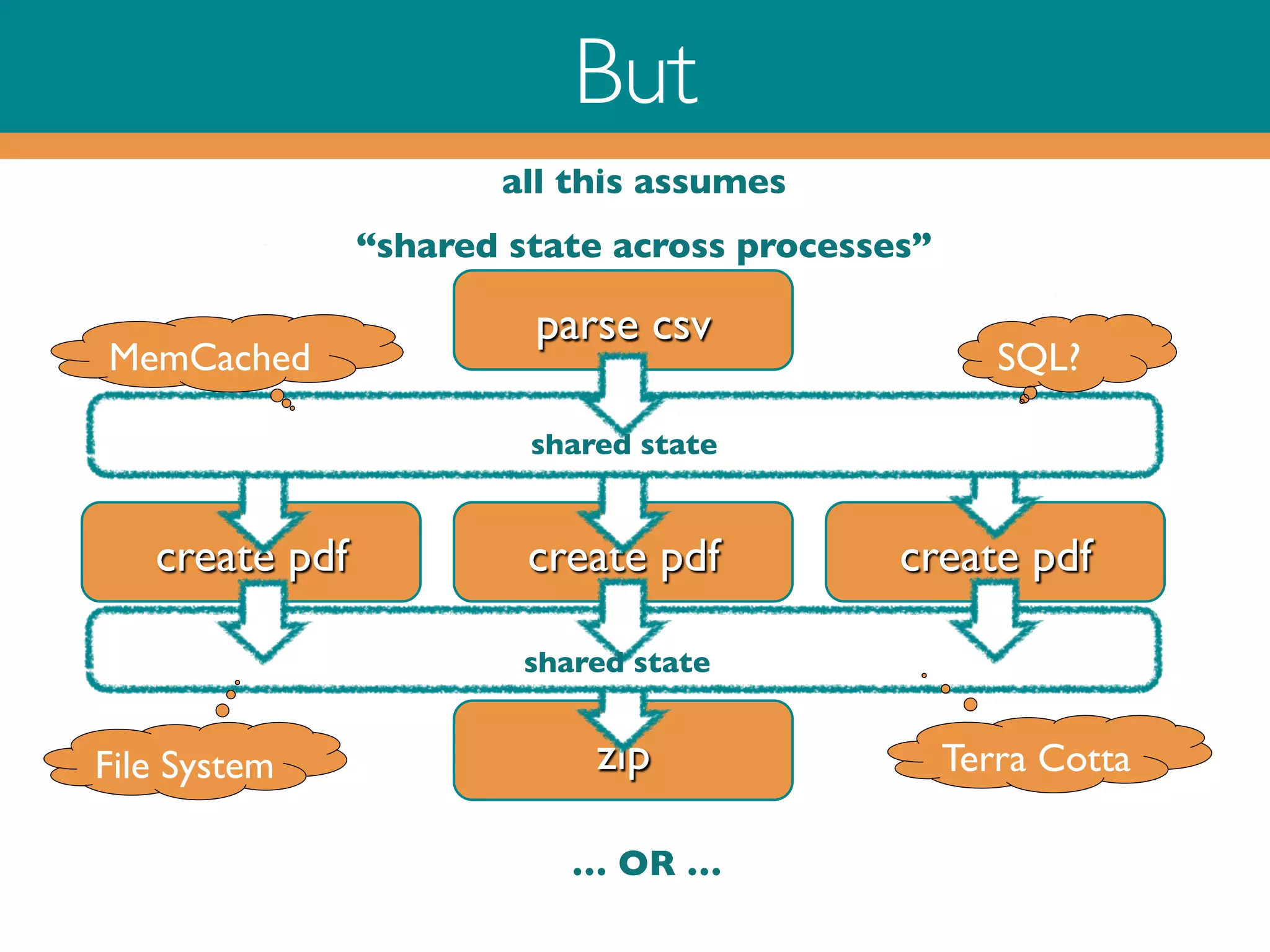
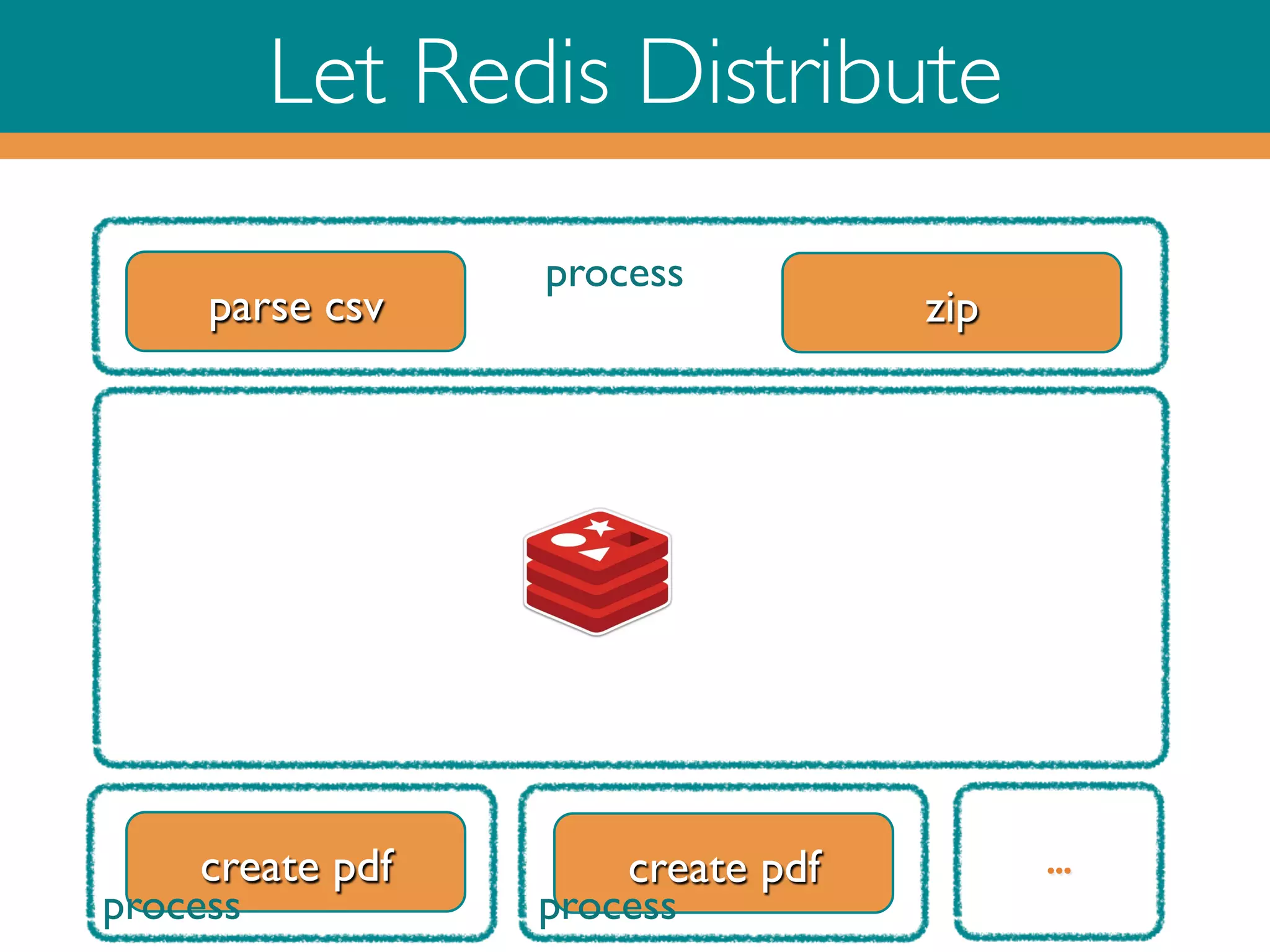
This document outlines a process for creating and zipping PDF files based on CSV data using Ruby and Redis. It discusses both linear and parallel approaches to efficiency, highlighting challenges such as thread safety and data management across processes. The implementation details cover CSV parsing, PDF generation, and zipping in addition to queue management via Redis for task distribution and result collection.

























































