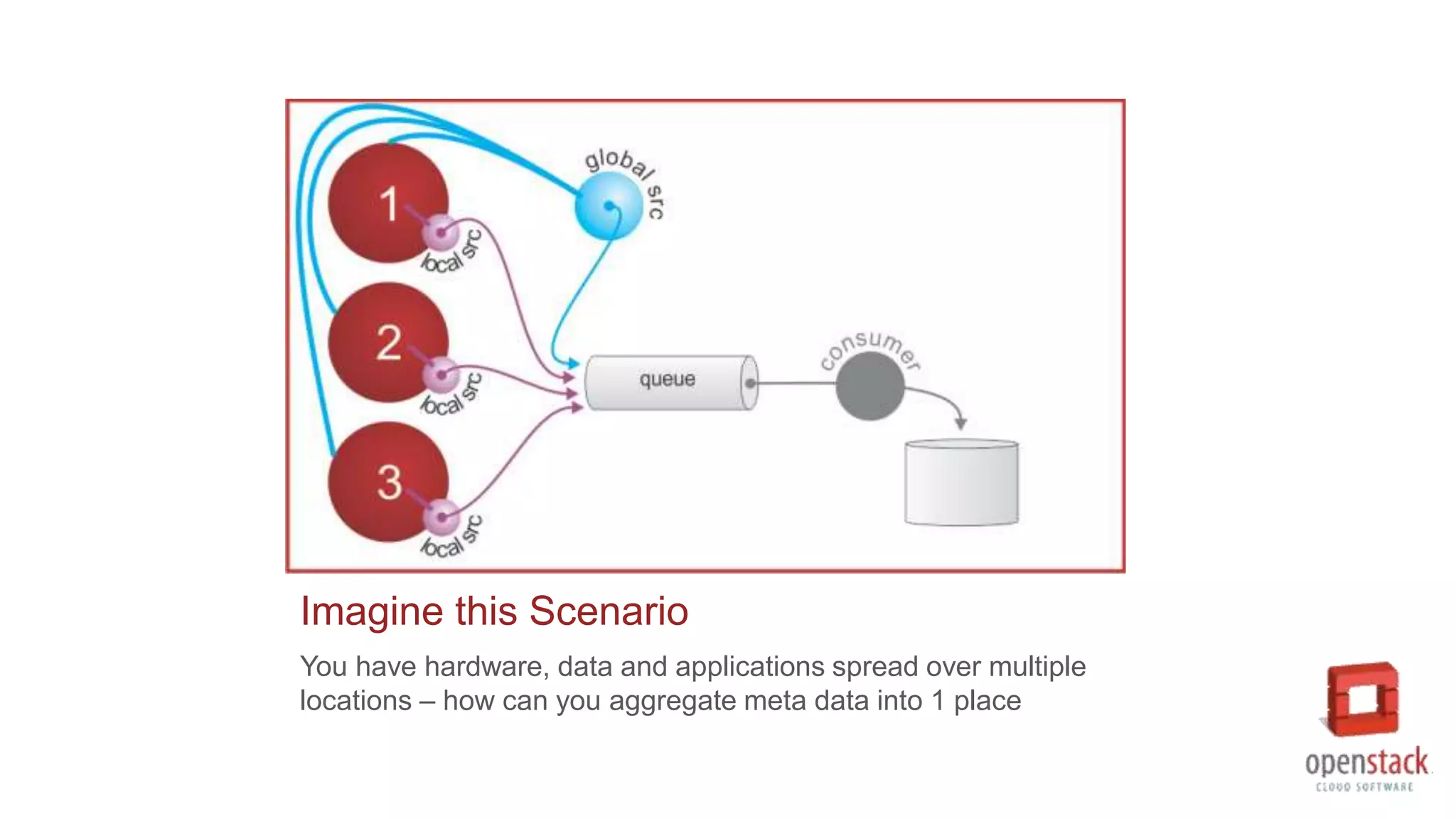
The document details challenges and strategies for data collection and management in OpenStack environments, focusing on Configuration Management Database (CMDB) frameworks. It discusses different approaches such as ETL (Extract, Transform, Load) and federation for data aggregation from various sources, providing specific payload structures and message formats for data processing. Additionally, it outlines an implementation philosophy that accommodates both snapshot and live updates to maintain data accuracy and history while considering resource efficiency.













![Philosophy employed
• Operating at large scale expect to have issues
– Small % error X a big number = some degree of loss
• Tolerant of loss
• Considerate of resources
• Wanted history
– Need easy access to the very latest
• Need a flexible [document] schema – this is JSON
– Provider/Agent is the owner of the schema for its data
– Need a way to converge; communities of practice](https://image.slidesharecdn.com/publicprivatehybrid-151102212430-lva1-app6892/75/Public-private-hybrid-cmdb-challenge-15-2048.jpg)


































































































