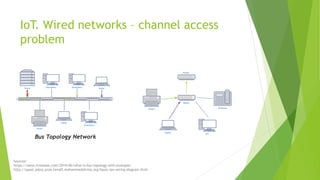
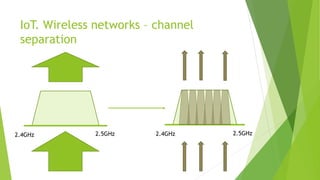
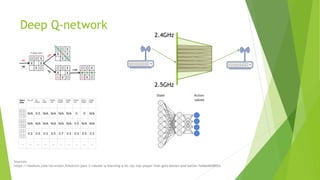
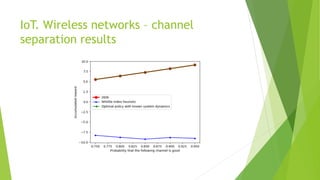
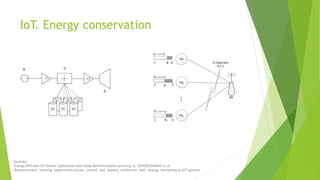
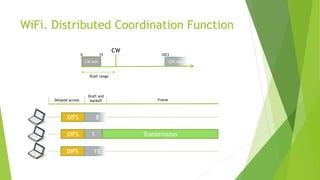
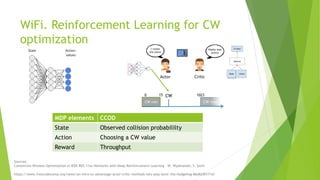
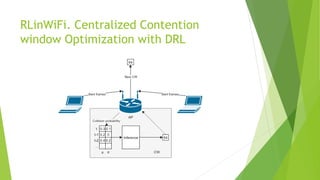
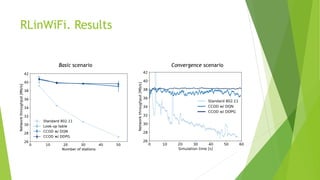
The document discusses the optimization of network throughput in IoT using deep reinforcement learning (DRL), highlighting key concepts such as Markov Decision Processes (MDP) and channel selection strategies. It covers various aspects of wireless communication including energy harvesting and medium access control optimization through techniques like contention window adjustment. The findings suggest promising results in improving wireless network performance through the application of DRL methods.