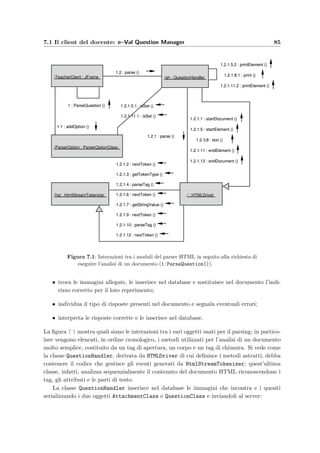
Il documento presenta una tesi di laurea sul progetto e-val, che si concentra sulle procedure di autovalutazione e valutazione dell'apprendimento in tecnologia web. Viene descritta in dettaglio l'architettura del sistema, comprese le tecnologie lato server e lato client, e viene fornita un'analisi della progettazione dell'applicazione e del database. Il documento include anche manuali per amministratori e docenti, evidenziando i requisiti di sistema e le procedure di installazione.





![INDICE iii
III Manuali e-Val 99
9 Manuale dell’amministratore 103
9.1 Requisiti di sistema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
9.2 Installazione dell’applicazione . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
9.2.1 Creazione del database . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
9.2.2 Il file eVal.war . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
9.2.3 Le applicazioni Java Swing e–Val Question Manager e e–Val Student . 105
9.2.4 Gli utenti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
9.3 I files di configurazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
9.3.1 Il file web.xml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
9.3.2 TeacherConfiguration.xml . . . . . . . . . . . . . . . . . . . . . . . 109
9.3.3 StudentConfiguration.xml . . . . . . . . . . . . . . . . . . . . . . . 109
9.4 I files di log . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
9.5 I servizi di amministrazione accessibili dal Web . . . . . . . . . . . . . . . . . 110
9.5.1 Cancellazione di un corso [Administration] . . . . . . . . . . . . . . . . 111
9.5.2 Creazione di un nuovo corso [NewCourse] . . . . . . . . . . . . . . . . 112
9.6 Incrementare le prestazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
10 Manuale del docente 113
10.1 Accesso dal Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
10.1.1 Pagina di benvenuto [Welcome] . . . . . . . . . . . . . . . . . . . . . . 114
10.1.2 Testata principale [Header] . . . . . . . . . . . . . . . . . . . . . . . . 115
10.1.3 Menu principale [Menu] . . . . . . . . . . . . . . . . . . . . . . . . . . 115
10.1.4 Modifica dei dati del corso [ModifyCourse] . . . . . . . . . . . . . . . . 116
10.1.5 Creazione di un nuovo esame [NewExam] . . . . . . . . . . . . . . . . 116
10.1.6 Modifica di un esame ancora da sostenere [ModifyExam] . . . . . . . . 117
10.1.7 Stampa della tabella d’esame [PrintExamStudentList] . . . . . . . . . 119
10.1.8 Esame svolto o in corso di svolgimento [ShowExamDone] . . . . . . . 119
10.1.9 Stampa della lista dei risultati [PrintExamResult] . . . . . . . . . . . 121
10.1.10Compito svolto o in corso di svolgimento dello studente [ShowExam-
Student] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
10.1.11Compito assegnato ad uno studente [PrintStudentTest] . . . . . . . . . 123
10.1.12Visualizzazione di un quesito [ShowQuestion] . . . . . . . . . . . . . . 124
10.1.13Rapporto su un compito svolto [ShowTestUsed] . . . . . . . . . . . . . 125
10.1.14Compito assegnato per un appello d’esame [PrintTest] . . . . . . . . . 125
10.1.15Modifica di un quesito [ModifyQuestion] . . . . . . . . . . . . . . . . . 125
10.1.16Modifica di un argomento [ModifyArgument] . . . . . . . . . . . . . . 126
10.1.17Stampa di un argomento [PrintArgument] . . . . . . . . . . . . . . . . 127
10.1.18Creazione di un nuovo argomento [NewArgument] . . . . . . . . . . . 128
10.1.19Visualizzazione di un compito gi`a assegnato [ShowTest] . . . . . . . . 128
10.1.20Modifica di un compito non ancora assegnato [ModifyTest] . . . . . . 129
10.1.21Creazione di un nuovo compito [NewTest] . . . . . . . . . . . . . . . . 129](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-5-320.jpg)









![1.2 Il Database Management System: MySQL 7
esistono delle relazioni basate sui valori contenuti; le relazioni che legano le tabelle vengono
specificate nel momento in cui si richiedono i dati, cio`e quando si interroga il database.
Essendo inoltre Open Source, MySQL pu`o essere scaricato liberamente da Internet, usato
e modificato per soddisfare le esigenze di ogni utilizzatore. Le caratteristiche principali di
MySQL sono:
• affidabilit`a: questo sistema vanta ormai un numero elevato di installazioni in tutto il
mondo e si `e guadagnato una buona reputazione per la sua affidabilit`a (vedi la lista
degli utenti contenuta nell’appendice B di [4]);
• velocit`a: `e stata la prerogativa principale dei programmatori quando hanno cominciato
lo sviluppo di questo DBMS; questo ha comportato scelte penalizzanti come il non
riconoscimento delle chiavi esterne e dei trigger che richiederebbero il blocco automatico
dei dati o il loro controllo preventivo;
• capacit`a: in linea generale la capacit`a di MySQL in termini di database `e limitata
dalle dimensioni massime dei file ammesse dal sistema operativo: su un PC con Linux,
ad esempio, `e possibile creare una tabella unica da due gigabyte; su Linux–Alpha, invece,
le dimensioni massime di una tabella sono limitate a otto terabyte (alcuni utenti usano
MySQL con 60’000 tabelle e circa 5’000’000’000 di records);
• controllo di accesso: l’accesso al sistema avviene non solo in base all’identificatore
e alla password dell’utente, ma anche in base all’host da cui proviene la richiesta di
connessione; `e possibile inoltre controllare i permessi a livello di tabella e perfino di
colonna;
• strumenti di sviluppo: esistono molte API che permettono l’accesso al database da
molti ambienti di programmazione tra cui Java (attraverso i driver JDBC), C, C++,
Perl, PHP, Python e TCL; anche le applicazioni Win32 si possono collegare al database
utilizzando i driver ODBC (Open–DataBase–Connectivity);
• supporto di varie piattaforme tra cui Windows, Linux, Mac OS X Server e numerose
varianti di UNIX;
• entry level SQL92: il linguaggio di interrogazione usato per accedere ai dati `e un
dialetto dell’SQL (acronimo di Structured Query Language); sono stati inoltre introdotti
nuovi domini per i dati, nuove parole chiave e funzionalit`a specifiche.
Naturalmente i vantaggi di MySQL vengono pagati con la mancanza di alcune caratteristiche
importanti:
• non `e possibile interrogare il database attraverso SELECT annidati come le seguenti:
SELECT * FROM table1 WHERE id IN (SELECT id FROM table2);
SELECT * FROM table1 WHERE id NOT IN (SELECT id FROM table2);](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-15-320.jpg)







![1.3 Il server Web: Tomcat 15
• elementi di scripting: in pratica sono pezzi di codice Java che servono come “collante”
tra azioni e dati statici; sono di tre tipi:
∗ dichiarazioni: servono a dichiarare variabili e metodi che potranno essere usati
nella pagina JSP e non producono nulla nel flusso di uscita verso il client; la
sintassi `e:
<%! declaration ( s ) %>
come per esempio <%! int i = 0; %> oppure
<%! public String f(int i) { if (i<3) return("..."); ... } %>
∗ scriptlet: sono dei veri e propri frammenti di codice che vengono eseguiti nel
momento in cui viene processata la richiesta; la sintassi `e
<% s c r i p t l e t %>
come nel seguente esempio
<% if (Calendar.getInstance().get(Calendar.AM_PM) == Calendar.AM) {%>
Good Morning
<% } else { %>
Good Afternoon
<% } %>
∗ espressioni: `e un’espressione in linguaggio Java che viene valutata e il cui risultato
`e forzatamente convertito in una stringa; il risultato `e successivamente inviato al
client; la sintassi `e:
<%= expression %>
come per esempio <%= (new java.util.Date()).toLocaleString() %>;
Nella pratica non `e buona norma inserire troppo codice nella JSP perch´e ridurrebbe la
leggibilit`a e l’efficienza ddi questa tecnologia; diventa allora pi`u conveniente usare dei
tag personalizzati oppure dei JavaBeans;
• dati statici: `e tutto ci`o che non rientra nelle categorie precedenti e rappresentano le
parti fisse (template); possono essere per esempio del testo, del codice HTML o XML.
Quando `e richiesta una JSP da parte di un utente il JSP container (per esempio Tomcat) legge
la JSP e la utilizza come modello per creare un servlet che viene successivamente compilato
e caricato dal servlet container; ad ogni richiesta successiva della stessa pagina il servlet
container si limiter`a a rieseguire gli stessi metodi su threads concorrenti.
Per una descrizione pi`u accurata e approfondita si rimanda a [1], [21] e [25].
g Servlet: java.sun.com/products/servlet
g JavaServer Pages: java.sun.com/products/jsp](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-23-320.jpg)















![4.3 Vincoli 33
non `e finalizzata allo svolgimento del compito (chiusura del programma, abbandono della
finestra, ecc.) ed infine correggere le risposte date dagli studenti. Appena concluso l’esame il
docente deve poter scegliere uno schema di correzione che stabilisca i criteri per assegnare i
voti e deve poter stampare la tabella dei risultati.
4.3 Vincoli
I vincoli del progetto sono i seguenti (tra parentesi sono specificati gli strumenti utilizzati
durante lo sviluppo dell’applicazione):
• sistema operativo lato server: Linux (per lo sviluppo Windows XP );
• database management system: MySQL (per lo sviluppo MySQL ver 3.23.42–nt [Win32]);
• server web: Tomcat (per lo sviluppo Apache Tomcat HTTP Server ver 4.0.3 [Win32]);
• linguaggi e tecnologie server–side: Java (per lo sviluppo JavaTM 2 SDK Standard Edition
ver 1.3.1), JavaServer Pages ver 1.2, Java Servlet ver 2.3;
• comunicazione client–server mediante protocollo HTTP;
• client dello studente: Java Swing JFrame che permetta di visualizzare delle pagine
HTML;
• clients del docente: Java Swing JFrame e browser web che permettano di visualizzare
delle pagine HTML con fogli di stile;
• linguaggio di scripting client–side (incluso nel browser): JavaScript 1.3 (ECMA–262);
• risorse umane: una sola persona.
Come si pu`o notare l’applicazione `e stata sviluppata su piattaforma Windows anche se dovr`a
essere installata su un sistema Linux; ci`o `e permesso dalla tecnologia Java che garantisce la
massima portabilit`a del software.
4.4 Criticit`a
Di seguito sono descritti i casi pi`u critici che hanno richiesto uno sforzo particolare per essere
risolti, e accanto ad ognuno un breve cenno sulle azioni intraprese per affrontarli.
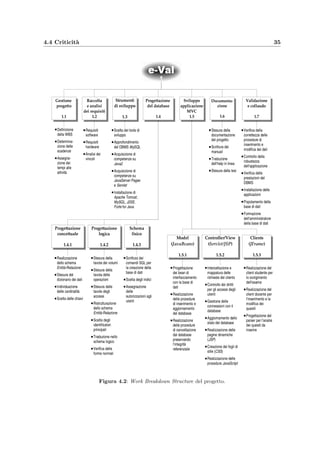
Descrizione criticit`a Azione
Implementazione di una 3–tier archi-
tecture evitando cio`e che i client ac-
cedano direttamente al database via
TCP–IP da internet
Uso della classe
com.oreilly.servlet.HttpMessage che
serializza un qualsiasi oggetto Java e lo invia
via HTTP al server Web il quale lo deserializza
e si occupa di inserirlo nel database](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-41-320.jpg)





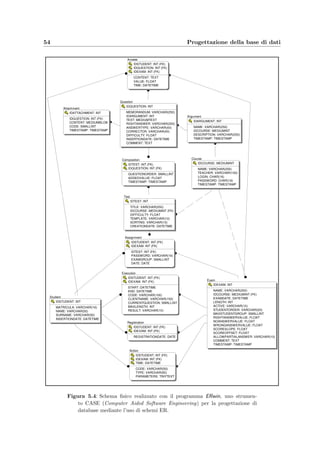
![Capitolo 5
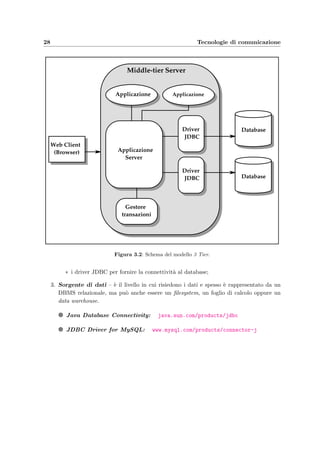
Progettazione della base di dati
La progettazione di una base di dati inizia dalla progettazione concettuale che ha lo scopo
di tradurre il risultato dell’analisi dei requisiti in una descrizione formale e integrata degli
aspetti strutturali e dinamici del sistema, rappresentando i dati in modo indipendente dalle
applicazioni di implementazione della base di dati. Il risultato di questa fase progettuale
`e rappresentato dallo schema Entit`a–Relazione (ER) accompagnato dal Dizionario dei
dati che ne descrive in modo informale le entit`a e le relazioni. A questo punto lo schema va
ristrutturato per adattarlo alla traduzione verso un modello logico; vengono quindi analizzate
le eventuali ridondanze, eliminate le generalizzazioni e vengono scelti gli identificatori primari
(o chiavi), cio`e quegli attributi di un’entit`a che ne identificano univocamente le occorrenze.
La fase successiva `e la progettazione logica che ha lo scopo di tradurre lo schema ER in
uno schema logico tenendo in considerazione l’implementazione della base di dati (nella fat-
tispecie il modello relazionale) e il carico applicativo, inteso come dimensioni dei dati e carat-
teristiche delle operazioni. A questo schema si accompagnano le descrizioni delle operazioni
che si devono svolgere sui dati e le eventuali tavole degli accessi.
La qualit`a dello schema di una base di dati relazionale `e “certificata” da alcune propriet`a
dette forme normali. Il rispetto di tali propriet`a assicura che lo schema relazionale abbia
caratteristiche di qualit`a che garantiscono in particolare che il suo uso non creer`a una base di
dati soggetta ad anomalie di aggiornamento. Spesso le tecniche sopraesposte producono gi`a
schemi che sono in forma normale, per`o comunque la normalizzazione `e utile perch´e costituisce
uno strumento di verifica e che pu`o suggerire ulteriori migliorie.
L’ultima fase progettuale prevede l’implementazione dello schema logico per lo specifi-
co DBMS (MySQL), producendo lo schema fisico, cio`e le istruzioni SQL che permettono
di creare le tabelle necessarie; in questa fase si analizzano anche delle strategie per incre-
mentare le prestazioni, se fosse necessario, ricorrendo all’uso degli indici secondari che con-
sentono l’accesso efficiente ai dati e possono essere usati assieme agli indici primari definiti
automaticamente sugli identificatori principali.
Come si pu`o notare la progettazione prevede diverse fasi che gradualmente vanno dalla
massima astrazione dello scema ER fino alla definizione delle tabelle per mezzo di comandi
SQL (cfr. [2] e [3]).](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-48-320.jpg)








![5.3 Schema fisico 47
si ritirano dall’esame.
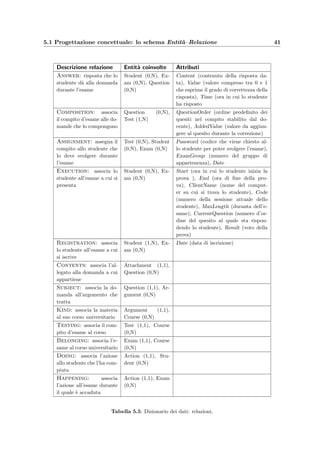
Scelta degli identificatori principali Le chiavi delle entit`a che si sono scelte non sono
tutte adatte a diventare degli identificatori principali per il successivo schema logico; infatti:
• l’occupazione di memoria sarebbe troppo grande e rallenterebbe soprattutto le operazio-
ni SQL di join, basti solamente pensare all’attributo Exam.Name (che ha un’occupazione
di memoria di qualche centinaio di byte) che compare nelle chiavi di Answer (3000 oc-
correnze all’anno), Action (1200 occorrenze all’anno) e Registration (350 occorrenze
all’anno);
• il DBMS (MySQL) su cui verr`a implementata la base di dati non aggiorna i cambiamenti
degli identificatori principali nelle tabelle referenziate, rendendo quasi impossibile il
cambiamento del valore di attributi importanti quali Argument.Name e Test.Title; ci`o
d`a origine alle cosiddette anomalie di aggiornamento.
Per questi motivi sono stati aggiunti degli attributi contenenti dei codici identificativi come
chiavi principali delle entit`a, sostituendo quelle scelte precedentemente che comunque riman-
gono delle chiavi secondarie.
A questo punto la ristrutturazione dello schema ER `e completa come si vede nella figura
5.2 che tradotto diventa lo schema logico di figura 5.3; in particolare le relazioni molti a
molti dello schema ER, cio`e quelle con molteplicit`a N sia a sinistra che a destra, diventano
tabelle che hanno, come attributi, gli attributi della relazione e, come chiave principale, quella
formata dall’unione delle chiavi principali delle entit`a che unisce.
5.2.2 Verifica delle forme normali
La qualit`a dello schema di una base di dati relazionale `e “certificata” da alcune propriet`a
dette forme normali; il rispetto di tali propriet`a assicura che lo schema relazionale abbia
caratteristiche di qualit`a che garantiscono, in particolare, che il suo uso non creer`a una base
di dati soggetta ad anomalie di aggiornamento (si veda [2]).
Lo schema relazionale `e sicuramente in Prima Forma Normale, poich´e tutti gli attributi
di tutte le relazioni contengono solamente valori atomici. La Seconda Forma Normale `e
verificata poich´e per ogni relazione non esistono dipendenze funzionali tra alcuni attributi che
compongono la chiave primaria e alcuni degli altri attributi non primi. Lo schema soddisfa
anche la Terza Forma Normale, se si escludono le dipendenze funzionali dovute all’aggiunta
dei codici che fungono da identificatori principali, poich´e tutti gli attributi non primi sono
mutuamente indipendenti, cio`e non esistono dipendenze funzionali fra di essi.
5.3 Schema fisico
Dallo schema logico ricavato nella sezione precedente si passa a scrivere la sequenza di comandi
SQL che definiscono lo schema della base di dati; in particolare prendendo d’esempio la tabella
dei quesiti (Question) `e necessario:](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-58-320.jpg)









![6.1 Il design pattern Model–View–Controller 59
Pagina 1 Pagina 2Evento A: Pagina 3Evento B:
La Pagina 1 corrisponde al primo stato, la Pagina 2 al secondo, la Pagina 3 al terzo; quello
che accade tra gli stati viene chiamato evento. In realt`a quello che accade `e un po’ pi`u
complesso: il client che si trova in un certo stato pu`o produrre un evento accompagnato
da alcuni parametri. La combinazione dello stato corrente, dell’evento e del risultato della
valutazione delle condizioni determiner`a lo stato successivo ed eventualmente alcune azioni
che devono essere intraprese affinch`e possa avvenire la transizione dello stato. Quanto appena
detto pu`o essere riassunto nella seguente asserzione:
[lo stato corrente + un evento + alcuni parametri]
determinano
[le azioni + lo stato successivo]
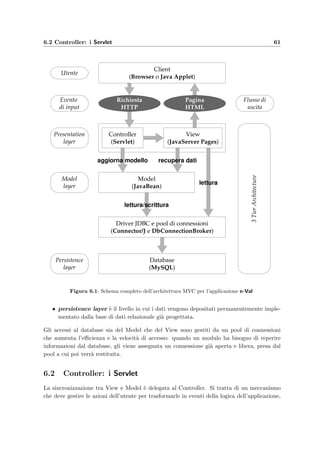
Un’architettura ben consolidata per l’interfaccia utente che consente di implementare questo
modello a stati ed eventi `e il design pattern MVC (o Model 2). Questo modello prevede che
l’applicazione Web sia divisa in tre parti: il Model, la View e il Controller. In questo tipo di
architettura ci sono due requisiti che il Controller deve soddisfare:
• il primo e pi`u importante `e che il Controller deve determinare il flusso di controllo del
sistema: deve analizzare l’evento che arriva dall’interfaccia utente e deve determinare
lo stato successivo dell’interfaccia stessa;
• il secondo, che spesso crea confusione nell’implementazione di questa architettura, `e
che il Controller deve eseguire le azioni necessarie nell’ambito del problema da trattare
(chiamato Model o Problem Domain); queste azioni quindi cambiano lo stato del sistema
sottostante; molta confusione deriva proprio dal fatto che lo stato del sistema `e diverso
dallo stato dell’interfaccia utente: in una normale applicazione, per esempio a finestre, il
Model `e responsabile della notifica alle classi preposte alla visualizzazione (View) di un
qualsiasi cambiamento dello stato del sistema sottostante; viceversa in un’applicazione
Web con un client leggero come un semplice browser, non c’`e modo di notificare al client
un cambiamento dello stato dell’applicazione.
Quindi i Controller ricevono ed analizzano gli eventi in ingresso, considerano lo stato del client
e determinano lo stato successivo del sistema; dal nuovo stato del sistema il Controller invoca
un’appropriata View che visualizza l’output richiesto. Quindi riassumendo:
i Controllers si occupano dell’input mentre le Views dell’output
La View viene creata su richiesta, quindi deve reperire i dati dal Model ogni volta che viene
istanziata e non c’`e alcuna notifica successiva del cambiamaento del modello. Views e Con-
trollers, che comunque devono rimanere separati, formano assieme il Presentetion Layer di
un’applicazione Web.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-70-320.jpg)









![6.3 Model: i JavaBeans 73
24
} e l s e i f ( AnswerType . equalsIgnoreCase ( ” range ” ) ) {
26 RealInterval I n t e r v a l s [ ] = RightAnswer . getRange ( ) ;
f l o a t Score =0;
28 i f ( Answers . s i z e () 1) return WRONGANSWER;
e l s e {
30 f o r ( I t e r a t o r i = Answers . i t e r a t o r ( ) ; i . hasNext ( ) ; ) {
RealInterval r i = new RealInterval (( String ) i . next ( ) ) ;
32 boolean Found = f a l s e ;
f o r ( i n t j =0; jI n t e r v a l s . length ; j++)
34 i f ( I n t e r v a l s [ j ] . contains ( r i ) ) {
Score +=RIGHT ANSWER;
36 Found=true ;
break ;
38 }
i f ( ! Found ) Score += WRONGANSWER;
40 }
return Score /Answers . s i z e ( ) ;
42 }
} e l s e return 0 ;
44 }
Le righe 5, 7, 19 e 25 selezionano il tipo di risposta che deve essere confrontata; prendendo
in considerazione il tipo range, se viene specificata pi`u di una risposta la riga 28 la considera
errata; se invece la risposta `e una sola e numerica, la riga 33 comincia a confrontarla con tutti
i valori della risposta esatta; pi`u precisamente verifica che il valore specificato appartenga
all’intervallo reale della risposta esatta (Intervals[j].contains(ri) alla riga 34).
Le altre tre operazioni descritte per la correzione dei compiti, possono essere riassunte
nella seguente formula:
V oto in trentesimi =
1
n
·
n
i=1
(p(i) + ai) · Slope + Offset (6.1)
in cui n `e il numero dei quesiti presenti nel compito dello studente, Slope e Offset rappre-
sentano la pendenza e lo scostamento della retta di conversione punteggio–voto, p(i) sono i
pesi assegnati alla risposta a seconda che sia corretta, errata oppure non data; infine ai sono
gli eventuali valori aggiunti a discrezione del docente (compresi tra 0 e 1).
Queste operazioni vengono eseguite, per tutti gli studenti che hanno sostenuto un esame,
da un’unica query contenuta nel metodo setExamResult() del bean dbTeacherModel:
SELECT Execution.IDStudent ,
2 Execution.IDExam ,
round(avg(
4 (case
when Answer.Value is null then Exam.NoAnswerValue
6 when Answer.Value =0 || ( Answer.Value 1
Exam. AllowPartialAnswer like ’no’) then Exam. WrongAnswerValue
8 when Answer.Value 0 then Answer.Value*Exam. RightAnswerValue end)](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-84-320.jpg)
![74 Progettazione dell’applicazione server
+ Composition.AddedValue
10 )* Exam.ScoreSlope+Exam.ScoreOffset ) as Score
FROM Student inner join Execution using(IDStudent)
12 inner join Assignment using(IDStudent , IDExam)
inner join Exam on ( Execution.IDExam=Exam.IDExam)
14 inner join Composition on ( Assignment.IDTest=Composition.IDTest)
left join Answer on ( Composition.IDQuestion=Answer.IDQuestion and
16 Execution.IDStudent=Answer.IDStudent and Execution.IDExam=Answer.IDExam)
WHERE Execution.IDExam like IDExam and
18 Execution.Result not like ’R’
GROUP BY Execution.IDStudent
Si analizza ora la query: le righe 5–8 assegnano i pesi ai vari tipi di risposte; la riga 9 aggiunge
un eventuale punteggio correttivo; la riga 3 fa una media di tutte le risposte raggruppate per
singoli studenti come definito nella riga 19; la riga 10 converte i punteggi espressi in centesimi,
in voti espressi in trentesimi moltiplicando i punteggi per la pendenza della retta di conversione
e aggiungendo l’offset; le righe 11–16 specificano le relazioni tra le tabelle considerate; in
particolare la riga 15 esegue un join sinistro per tenere conto anche delle risposte non date;
infine le righe 17 e 18 selezionano l’esame identificato dal codice IDExam e gli studenti che
non si sono ritirati nel corso dell’esame.
6.3.2 Assegnazione dei compiti agli studenti
Prima di attivare un esame `e necessario assegnare agli studenti iscritti uno o pi`u compiti
preparati in precedenza; la procedura di assegnazione prevede che il docente scelga alcuni tra
i compiti disponibili e che l’applicazione li assegni automaticamente a tutti gli studenti; deve
essere tenuto conto anche del numero di studenti per gruppo che possono accedere contempo-
raneamente a sostenere l’esame (corrisponde almeno alla capienza dell’aula di informatica).
Il criterio che viene seguito per l’assegnazione `e il seguente:
• si calcola il numero di gruppi di studenti che sosterranno l’esame (cio`e il numero di
studenti iscritti diviso per gli studenti per gruppo);
• si dividono i compiti da assegnare per il numero di gruppi;
• se non sono abbastanza si assegnano ciclicamente i compiti ai gruppi (perci`o alcuni
gruppi avranno lo stesso compito);
• i compiti destinati ad ogni gruppo vengono assegnati alternativamente e ciclicamente
agli studenti in ordine alfabetico;
• per ogni studente viene creata una password che assieme al numero di matricola iden-
tifica univocamente l’esame.
Questo algoritmo `e implementato dalla seguente procedura:
p u b l i c boolean assignTestExam ( String [ ] strIDsTest ) {
2 boolean b = true ;
ArrayList IDsStudent = getQueryColumn ( ”SELECT Student . IDStudent ” +](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-85-320.jpg)
![6.3 Model: i JavaBeans 75
4 ”FROM Registration natural j o i n Student ” +
”WHERE Registration . IDExam l i k e ” + IDExam + ” ”
6 ”ORDER BY Student . Surname , Student .Name” , 1 ) ;
i n t RegisteredStudent = IDsStudent . s i z e ( ) ;
8 i n t StudentPerGroup = Integer . parseInt (
( String ) getQueryValue ( ”SELECT MaxStudentGroup from Exam ” +
10 ”WHERE IDExam l i k e ” + IDExam ) . get ( ”MaxStudentGroup” ) ) ;
i n t NoTest = strIDsTest . length ;
12 i n t NoGroup = Functions . roundUp (( double ) RegisteredStudent /
( double ) StudentPerGroup ) ;
14 i n t NoMinTestPerGroup = Functions . roundDown (( double ) NoTest /
( double )NoGroup ) ;
16 i n t Group=0;
i n t Test =0;
18 i n t StudentInGroup=0;
i n t TestInGroup=0;
20 i n t NoStPerTest=0;
i n t TestCount=0;
22 f o r ( i n t St =0; StRegisteredStudent ; St++) {
i f ( ( St % StudentPerGroup)==0) {
24 Group++;
Test += TestInGroup ;
26 TestCount=0;
StudentInGroup = (GroupNoGroup?StudentPerGroup :
28 ( RegisteredStudent%StudentPerGroup ) ) ;
TestInGroup = (Group=(NoTest−(NoGroup∗NoMinTestPerGroup ))?
30 ( NoMinTestPerGroup+1):Math .max(1 , NoMinTestPerGroup ) ) ;
NoStPerTest = Functions . roundUp (( double ) StudentInGroup /
32 ( double ) TestInGroup ) ;
}
34 b = addAssignment (( String ) IDsStudent . get ( St ) ,
strIDsTest [ ( Test + ( TestCount++ % TestInGroup )) % NoTest ] , Group ) ;
36 }
}
Alla riga 3 viene recuperata dal database la lista degli studenti iscritti all’esame; le righe 7–21
definiscono alcune variabili utili per i calcoli successivi (per esempio il numero dei compiti
per gruppo, il numero di studenti iscritti, ecc.); il ciclo for della riga 22 scorre tutti gli
studenti iscritti in ordine alfabetico; le righe 23–33 vengono eseguite solamente quando si sta
per iniziare l’assegnazione dei compiti ad un gruppo di studenti; infine la riga 34 richiama,
per ogni iscritto, la funzione addAssignment che aggiorna la base di dati e calcola la password
di accesso per lo studente, assicurandosi che non ne sia gi`a stata assegnata un’altra di uguale.
6.3.3 Calcolo della difficolt`a dei quesiti
La difficolt`a di un quesito viene calcolata utilizzando la media delle correttezze delle risposte
date dagli studenti fino a quel momento. Questa operazione viene svolta dalla procedura](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-86-320.jpg)

![78 Progettazione dell’applicazione server
6.4.1 Struttura di una JSP
Viene ora analizzata la struttura tipica di una JSP. Bisogna ricordare che una JavaServer
Page `e un file di testo in formato XML in cui, tra i vari tag, vengono inseriti i pezzi di codice
HTML necessario per la visualizzazione. Ogni pagina inizia con:
%@ t a g l i b uri=”http: // jakarta . apache . org / t a g l i b s / dbtags ” p r e f i x=”sql ” %
2 %@ t a g l i b uri=”http: // jakarta . apache . org / t a g l i b s / request −1.0”
p r e f i x=”req” %
4 %@ t a g l i b uri=”http: // jakarta . apache . org / t a g l i b s / session −1.0”
p r e f i x=”s e s s ” %
6 %@ t a g l i b uri=”http: // jakarta . apache . org / t a g l i b s / u t i l i t y ” p r e f i x=”x” %
jsp:useBean id=”teacherDB ” scope=”s e s s i o n ”
8 c l a s s=”eValServer . dbTeacherModel”/
jsp:useBean id=”TeacherConnection ” scope=”request ”
10 c l a s s=”java . sql . Connection ”/
!DOCTYPE HTML PUBLIC ”−//W3C//DTD HTML 4 . 0 1 Transitional //EN”
12 ” http: //www. w3 . org /TR/html4/ loose . dtd”
in cui i primi quattro tag dichiarano quali librerie si vogliono utilizzare nella pagina; la riga 7
permette di usare il JavaBean denominato teacherDB per recuperarne le propriet`a da inserire
nella pagina; la riga 9 dichiara invece che la connessione al database deve essere passata alla
JSP come parametro della richiesta HTTP (questo consente il riciclo della connessione e la
sua restituzione al pool di connessioni); infine la riga 11 specifica il tipo e la versione del
documento HTML.
All’interno del tag HEAD, che rappresenter`a l’intestazione della futura pagina HTML,
vengono inserite le righe
META http−equiv=”CONTENT−TYPE” content=”text /html ; charset=iso −8859−1”
LINK REL=s t y l e s h e e t HREF=”Common/ eVal style . css ” TYPE=”text / css ”
SCRIPT type=”text / j a v a s c r i p t ” src=”Common/ e V a l s c r i p t . j s ”/SCRIPT
che specificano al browser il tipo di contenuto, il set di caratteri, il foglio di stile CSS e il file
con il codice JavaScript.
L’accesso al database per recuperare i dati da inserire nella pagina, avviene tramite la
libreria di tag DBTags; per recuperare, ad esempio, gli esami di un determinato corso e
inserirli in una lista di selezione di un form basta scrivere:
sql:statement id=”stmt ” conn=”TeacherConnection”
2 . . .
FORM method=POST name=’Exam’ action = ’ ’
4 DIV c l a s s =’FormHead ’Esami/DIV
sql:query
6 SELECT concat(Name , ’ [’, date_format(ExamDate ,’%d %M %Y, %H:%i’), ’]’),
IDExam
8 FROM Exam
WHERE IDCourse like jsp:getProperty name=teacherDB property=idCourse/ and
10 ExamDate SUBDATE(curdate (), INTERVAL](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-89-320.jpg)






![86 Progettazione dei client
p r i v a t e String FromServer ( String HttpQuery , S e r i a l i z a b l e obj ) {
2 try {
return FromServer ( ServerRequest ( HttpQuery ) . sendPostMessage ( obj ) ) ;
4 } catch ( IOException e ) {
ParserMessage ( ” [#] Errore n e l l a comunicazione con i l server ( obj ) ! ” ) ;
6 return ”” ;
}
8 }
in cui alla riga 3 il metodo ServerRequest restituisce l’oggetto HttpMessage corrispondente
all’URL desiderato (HttpQuery).
7.2 I browsers Web
I broswers consentono al docente e all’amministratore di accedere via Web ai servizi messi
a disposizione da e-Val. I problemi maggiori incontrati nello sviluppo delle pagine HTML
dinamiche riguardano proprio i diversi gradi di compatibilit`a dei browser con gli standard in
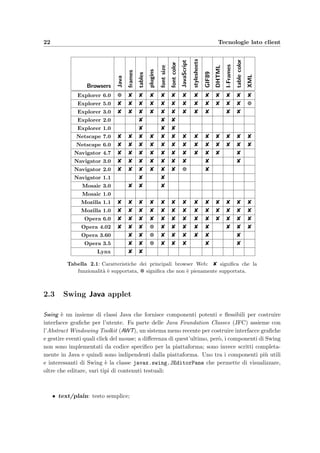
circolazione (vedi tabella 2.1); a tal proposito si sono testate con successo le seguenti versioni:
Mozilla 1.1, Microsoft Internet Explorer 6.0 e Netscape 7.0. Altri browser, come per esempio
Opera o versioni precedenti di Netscape, non offrono un supporto soddisfacente ai fogli di
stile.
7.2.1 I fogli di stile: CSS
I fogli di stile permettono di separare la struttura di un documento HTML dal suo layout. A
questo scopo sono stati realizzati i seguenti files:
• eVal style.css: descrive lo stile dell’applicazione Web del docente; poich´e i browser
supportano quasi pienamente lo standard CSS, sono state usate anche caratteristiche
avanzate;
• Question style.css: descrive lo stile di visualizzazione dei quesiti;
• Student style.css: descrive lo stile delle pagine HTML visualizzate da e–Val Student
durante l’esecuzione dell’esame; i comandi sono semplici poich´e JEditorPane non sup-
porta interamente i fogli di stile (l’orientamento degli sviluppatori di Java `e comunque
quello di estenderne il supporto nelle versioni successive);
• Welcome style.css: descrive lo stile delle pagine di benvenuto;
7.2.2 Il linguaggio di scripting client–side: JavaScript
Per migliorare l’interazione con l’utente, migliorare l’interfaccia grafica e ridurre il numero di
bottoni dei form, si `e ricorso all’inserimento di semplici pezzi di codice JavaScript che vengono
eseguiti dal browser dell’utente. Non si sono riscontrati problemi di compatibilit`a con i diversi
browsers. Le procedure sono contenute in due files:](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-97-320.jpg)
![7.3 Il client dello studente: e–Val Student 87
• Calendar.js: contiene il codice per la creazione e la gestione del calendario per la scelta
della data e dell’ora di un appello d’esame;
• eVal script.js: contiene le procedure per la gestione dei form HTML; per esempio la
selezione di tutti gli elementi di una lista viene realizzata dalla seguente funzione:
function CheckAll ( xCheck ) {
i f ( xCheck . length==undefined )
xCheck . checked=true ;
e l s e
f o r ( var i = 0; i xCheck . length ; i ++) xCheck [ i ] . checked=true ;
}
7.3 Il client dello studente: e–Val Student
Il funzionamento, le procedure di inizializzazione, di autenticazione e di comunicazione con il
server di questa applicazione Java sono del tutto simili a quelle di e–Val Question Manager del
docente e descritte nella sezione 7.1. Questo client contiene in pi`u una classe interna derivata
da TimerTask per la temporizzazione delle seguenti operazioni:
• visualizzare ad intervalli regolari il form di autenticazione dello studente;
• decrementare il tempo rimasto a disposizione dello studente per completare il compito;
• sincronizzare periodicamente il tempo rimanente del client con quello del server;
• eseguire il countdown per la chiusura dell’applicazione nel caso in cui riceva dal server
il comando di chiusura.
L’inizializzazione del timer avviene in questo modo:
p r i v a t e TimeClass Clock ;
p r i v a t e Timer ClientTimer = new Timer ( ) ;
. . .
Clock = new TimeClass ( TimerPeriod ) ;
ClientTimer . schedule ( Clock , TimerPeriod ∗1000 , TimerPeriod ∗1000);
A questo punto, dopo ogni TimerPeriod secondi viene eseguito il metodo run() della classe
TimeClass:
p u b l i c void run ( ) {
2 SecondsElapsed += TimeInterval ;
i f ( ExamRunning Logged ) {
4 //L ’ esame `e in corso
i f ( ( SecondsElapsed % SecondsTimeSync ) == 0){
6 i f ( ! getServerTime ( ) ) {
Decrement ( ) ;
8 setLoginButton ( true ) ;
} e l s e setLoginButton ( f a l s e ) ;](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-98-320.jpg)


![90 Organizzazione del codice
8.1 Package eVal
eVal
ConfigurationHandler
ReadingParameters : boolean
ReadingName : boolean
ReadingValue : boolean
Name : String
Value : String
Parameters : HashMap
RootTag : String
ErrorOccurred : boolean
strError : String
create ConfigurationHandler(RootTag: String,XMLreader: Reader)
setError(strError: String) : void
getError() : String
getConfiguration() : HashMap
error(str: String) : void
startDocument() : void
endDocument() : void
startElement(tag: void) : void
endElement(tag: void) : void
text(str: String) : void
HTMLDriver
create HTMLDriver()
parse(HTMLReader: Reader) : void
startDocument() : void
startElement(tag: void) : void
text(str: String) : void
endElement(tag: void) : void
error(msg: String) : void
endDocument() : void
Answer
RIGHT_ANSWER_SCORE : float
WRONG_ANSWER_SCORE : float
INPUT_NAME : String
ANSWER_SEPARATOR : String
Answers : ArrayList
AnswerType : String
NullAnswer : boolean
Score : int
create Answer(Content: String[],AnswerType: String)
create Answer(Content: String,AnswerType: String)
parseAnswer(strAnswer: String) : void
getAnswerString() : String
getAnswerType() : String
size() : int
contains(str: String) : boolean
getRange() : RealInterval[]
compareAnswer(RightAnswer: Answer) : float
isValidAnswer() : boolean
AttachmentClass
content : byte[]
create AttachmentClass(buffer: byte[])
getContent() : byte[]
setContent(buffer: byte[]) : void
RealInterval
loVal : double
hiVal : double
Val : double
SinglePoint : boolean
create RealInterval(interval: String)
convert(d: String) : double
getLoVal() : double
getHiVal() : double
getVal() : double
isSinglePoint() : boolean
toString(val: double) : String
toString() : String
contains(value: String) : boolean
contains(ri: RealInterval) : boolean
ErrorLog
FILE_NAME : String
fout : FileOutputStream
getLogDirectory() : File
write(str: String) : void
Functions
getCode() : int
getStringCode(length: int) : String
implode(glue: String,ob: Object[]) : String
implode(glue: String,al: ArrayList) : String
explode(separators: String,str: String) : ArrayList
roundUp(d: double) : int
roundDown(d: double) : int
QuestionClass
Memorandum : String
Comment : String
RightAnswer : Answer
update : boolean
Text : StringBuffer
create QuestionClass(Memorandum: String)
setRightAnswer(RightAnswer: Answer) : void
getRightAnswer() : Answer
setComment(Comment: String) : void
getComment() : String
printText(str: String) : void
getText() : String
getMemorandum() : String
finalize() : void
setUpdate(b: boolean) : void
toUpdate() : boolean
Figura 8.1: Classi del package eVal.
Le classi contenute in questo package sono utilizzate sia dall’applicazione sul lato server
che dai client; contiene anche delle classi di utilit`a:
• Answer rappresenta la risposta ad un quesito; pu`o essere di quattro tipi;
• AttachmentClass rappresenta un allegato che il client e–Val Question Manager invia
al server per inserirlo nel database;
• ConfigurationHandler consente di leggere un file di configurazione in formato XML;
`e usato dai client del docente e studente;](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-101-320.jpg)

![92 Organizzazione del codice
swing
JDialog
util
JFrame
TimerTask
eValStudent
TimeClass
TimeInterval : int
SecondsLeft : int
SecondsElapsed : int
create TimeClass(SecondsInterval: int)
Round(N: int) : int
getServerTime() : boolean
run() : void
TimeRefresh() : void
Decrement() : void
setTimeout() : void
AuthenticationPanel
create AuthenticationPanel(parent: Frame,modal: boolean)
getAuthenticationString() : String
getReturnStatus() : int
initComponents() : void
okButtonActionPerformed(evt: ActionEvent) : void
cancelButtonActionPerformed(evt: ActionEvent) : void
closeDialog(evt: WindowEvent) : void
doClose(retStatus: int) : void
StudentClient
create StudentClient(host: String)
create StudentClient()
StartClient() : void
setError(strError: String) : void
initParameters() : void
initComponents() : void
buttonLoginMouseClicked(evt: MouseEvent) : void
formWindowIconified(evt: WindowEvent) : void
formWindowDeactivated(evt: WindowEvent) : void
exitForm(evt: WindowEvent) : void
AuthenticateStudent() : void
Extract(Response: String,tag: String) : String
RequestURL(Action: String) : String
RequestURL(Action: String,Parameters: String) : String
sendServerRequest(strRequest: String) : String
Violation(Type: String,Parameters: String) : void
setLoginButton(b: boolean) : void
CloseClient() : void
main(args: String[]) : void
Figura 8.2: Classi del package eValStudent.
• AttachmentController servlet che restituisce ai client che lo richiedono gli allegati
dei quesiti;
• BackResponseClass viene usata per acquisire l’output delle JSP e inserirlo negli
archivi JAR o ZIP;
• dbAccess implementa le routine d’accesso a basso livello alla base di dati; viene estesa
dalle classi dbAttachmentAccess, dbStudentModel e dbTeacherModel
• dbAttachmentAccess mette a disposizione i metodi necessari per il reperimento degli
allegati;](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-103-320.jpg)

![94 Organizzazione del codice
swing
eVal
JDialogJFrame
HTMLDriver
QuestionClass AttachmentClass
JFileChooser
ConfigurationHandler
eValTeacher
MyFileFilter
AuthenticationPanel
create AuthenticationPanel(parent: Frame,modal: boolean)
getAuthenticationData() : HashMap
clearForm() : void
setInfo(msg: String) : void
hide() : void
getReturnStatus() : int
initComponents() : void
okButtonActionPerformed(evt: ActionEvent) : void
cancelButtonActionPerformed(evt: ActionEvent) : void
closeDialog(evt: WindowEvent) : void
doClose(retStatus: int) : void
TeacherClient
create TeacherClient(host: String)
create TeacherClient()
StartClient() : void
initParameters() : void
ServerResponse(serverURL: String,props: Properties) : String
AuthenticateTeacher() : boolean
Extract(Response: String,tag: String) : String
setError(str: String) : void
enableQuestionPanel(b: boolean) : void
initComponents() : void
buttonSaveQuestionMouseClicked(evt: MouseEvent) : void
buttonHTMLSourceMouseClicked(evt: MouseEvent) : void
buttonInsertQuestionMouseClicked(evt: MouseEvent) : void
buttonCloseMouseClicked(evt: MouseEvent) : void
buttonLoginMouseClicked(evt: MouseEvent) : void
buttonShowQuestionMouseClicked(evt: MouseEvent) : void
comboModelItemStateChanged(evt: ItemEvent) : void
editorHTMLMouseClicked(evt: MouseEvent) : void
ParseQuestion(insert: boolean,Source: Reader,HTMLfile: File) : void
exitForm(evt: WindowEvent) : void
main(args: String[]) : void
QuestionHandler
create QuestionHandler(ParserOption: ParserOptionClass,Question: QuestionClass,ServerOption: HashMap,OutputLog: OutputLogClass)
ParserMessage(msg: String) : void
error(str: String) : void
FromServer(is: InputStream) : String
ServerRequest() : void
FromServer(HttpQuery: String,obj: Serializable) : String
FromServer(HttpQuery: String,props: Properties) : String
startDocument() : void
newDocument(strMemorandum: String) : void
startElement(tag: void) : void
text(str: String) : void
endElement(tag: void) : void
print(str: String) : void
printElement(tag: void) : void
endDocument() : void
endQuestionParsing() : void
ExcludeSection(b: boolean) : void
setAnswer(Type: String,tag: void) : boolean
insertAttachment(imgSRC: String) : String
returnFile(filename: String,out: OutputStream) : void
SaveQuestion() : boolean
isQuestionSaved() : boolean
ParserOptionClass
create ParserOptionClass()
addOption(Name: String,Content: String) : void
isSet(Name: String) : boolean
isSet(Name: String,Ob: String) : boolean
OutputLogClass
create OutputLogClass(JTA: JTextArea)
write(msg: String) : void
clear() : void
Figura 8.3: Classi del package eValTeacher.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-105-320.jpg)
![8.4 Package eValServer 95
eValServer
AttachmentController
init(config: void) : void
destroy() : void
processRequest(request: void) : void
doGet(request: void) : void
doPost(request: void) : void
getServletInfo() : String
dbAccess
create dbAccess()
create dbAccess(host: String,database: String,user: String,password: String)
setdbConnection(conn: Connection) : boolean
getdbConnection() : Connection
freeDBConnection() : Connection
setError(strError: String) : void
getError() : String
resetError() : void
isErrorOccurred() : boolean
getdbHost() : String
getdbName() : String
getdbUser() : String
getdbPassword() : String
escapeString(str: String) : String
setQuery(str_sql: String) : int
updateQuery(str_sql: String) : int
getRecord() : String[]
resetQuery() : void
getQueryValue(str_sql: String) : HashMap
getOrderedQuery(str_sql: String,ColumnIndex: int) : TreeMap
getQueryColumn(str_sql: String,ColumnIndex: int) : ArrayList
getQuery(str_sql: String) : ArrayList
lastID() : int
finalize() : void
closeStatement() : void
dbAttachmentAccess
dbInsertQuestion
create dbInsertQuestion()
create dbInsertQuestion(host: String,database: String,user: String,password: String)
String2ID(strID: String) : int
setIDCourse(IDCourse: int) : void
setIDCourse(strIDCourse: String) : boolean
getIdCourse() : String
setIDArgument(strIDArgument: String) : boolean
getIdArgument() : String
setIDExam(strIDExam: String) : boolean
getIdExam() : String
setIDTest(strIDTest: String) : boolean
getIdTest() : String
setIDQuestion(strIDQuestion: String) : boolean
getIdQuestion() : String
setIDStudent(strIDStudent: String) : boolean
getIdStudent() : String
isAuthenticated(Login: String,Password: String) : boolean
setFirstIdArgument() : boolean
putEmptyQuestion() : String
InsertQuestion(question: QuestionClass) : boolean
updateQuestion(AnswerType: String,RightAnswer: String,HTMLtext: String) : boolean
updateQuestionFields(Memorandum: String,Comment: String) : boolean
getQuestion() : HashMap
deleteQuestion() : boolean
putAttachment(buffer: byte[]) : String
finalize() : void
dbStudentModel
create dbStudentModel()
create dbStudentModel(host: String,database: String,user: String,password: String)
getIdStudent() : String
getIdQuestion() : String
getIdExam() : String
getCode() : String
getIdTest() : String
getAnswerType() : String
isAuthenticated() : boolean
isExamEnd() : boolean
isRunningExam() : boolean
getExecutionStatus() : String
putAction(Type: String,Parameters: String) : void
isAuthenticated(Matricula: String,Password: String,jSessionID: String,strClientName: String,HTTPHeader: String) : boolean
isStillAuthenticated(jSessionID: String) : boolean
StartExam() : boolean
getTimeLeft() : String
setNextQuestion() : boolean
setCurrentQuestion() : boolean
setQuestion(Next: boolean) : boolean
setStudentAnswer(strContent: String[]) : boolean
setStudentAnswer(strContent: String[],Value: float) : boolean
getRightAnswer() : String
Surrender() : boolean
End() : boolean
dbTeacherModel
create dbTeacherModel()
create dbTeacherModel(host: String,database: String,user: String,password: String)
setMonths(strMonths: String) : boolean
getMonths() : String
isAdministrator() : boolean
setAdministrator(b: boolean) : void
clearJSPHistory() : void
isJSPHistoryEmpty() : boolean
setCurrentJSP(JSP: String) : void
getCurrentJSP() : String
setPreviousJSP() : void
deleteRecords(son: String,father: String,joinField: String) : int
clear() : int
insertCourse(Name: String,Teacher: String,Login: String,Password: String) : boolean
updateCourse(Name: String,Teacher: String) : boolean
deleteCourses(strIDsCourse: String[]) : boolean
updateCourseLogin(Login: String,Password: String) : boolean
insertArgument(Name: String,Description: String) : boolean
updateArgument(Name: String,Description: String) : boolean
deleteArguments(strIDsArgument: String[]) : boolean
insertExam(Name: String,ExamDate: String,Length: String,MaxStudentGroup: String,Comment: String) : boolean
updateExam(Name: String,ExamDate: String,Length: String,MaxStudentGroup: String,Comment: String) : boolean
deleteExams(strIDsExam: String[]) : int
isExamStarted() : boolean
setExamActive() : boolean
setExamInactive() : boolean
setExamResult() : boolean
isTestUsed() : boolean
insertTest(Title: String,RandomSorting: boolean) : boolean
updateTest(Title: String,Template: String,Sorting: String) : boolean
deleteTests(strIDsTest: String[]) : boolean
copyTest() : boolean
setTestDifficulty() : boolean
addTestQuestion(strIDsQuestion: String[]) : boolean
deleteTestQuestion(strIDsQuestion: String[]) : boolean
updateTestQuestionValue(strValue: String[],strIDsQuestion: String[]) : boolean
updateTestQuestionOrder(strOrder: String[],strIDsQuestion: String[]) : boolean
assignTestExam(strIDsTest: String[]) : boolean
addAssignment(strIDStudent: String,strIDTest: String,ExamGroup: int) : boolean
setRightAnswer(strRightAnswer: String) : boolean
setAnswerValue(strRightAnswerValue: String,strNoAnswerValue: String,strWrongAnswerValue: String,AllowPartialAnswer: boolean) : boolean
setScoreParameter(strScoreMax: String,strScoreMin: String,strValueMax: String,strValueMin: String) : boolean
RecorrectAnswer() : boolean
updateAnswerValue(strValue: String[],strIDsQuestion: String[]) : boolean
isAllAnswerCorrect() : boolean
deleteQuestions(strIDsQuestion: String[]) : boolean
getQuestionCount() : String
setQuestionDifficulty(diff: double) : boolean
moveQuestions(strIDArgument: String,strIDsQuestion: String[]) : boolean
setQuestionsDifficulty() : boolean
getAnswerType() : String
getAttachments(strIDsQuestion: String[]) : ArrayList
addStudentRegistration(r: Reader) : boolean
addStudentRegistration(Matricula: String,Surname: String,Name: String) : boolean
removeStudentRegistration(IDsStudent: String[]) : boolean
finalize() : void
eVal
AttachmentClassHTMLDriver QuestionClass
http
HttpServletHttpServletResponseWrapper
TeacherController
init(config: void) : void
destroy() : void
JSPdispatcher(strJSP: String,request: void) : void
ShowPoolInfo(Login: boolean,request: void) : void
HTTPHeader(request: void) : String
Send(response: void) : boolean
UpdateClientXMLConfig(host: String) : boolean
processRequest(request: void) : void
doGet(request: void) : void
doPost(request: void) : void
getServletInfo() : String
QuestionJarHandler
create QuestionJarHandler(os: OutputStream)
ParserMessage(msg: String) : void
error(str: String) : void
startDocument() : void
startElement(tag: void) : void
text(str: String) : void
endElement(tag: void) : void
endDocument() : void
print(str: String) : void
printElement(tag: void) : void
BackResponseClass
pw : PrintWriter
create BackResponseClass(response: void)
getWriter() : PrintWriter
setContentType(type: String) : void
flushBuffer() : void
isCommitted() : boolean
resetBuffer() : void
StudentController
init(config: void) : void
destroy() : void
JSPdispatcher(strJSP: String,request: void) : void
ShowPoolInfo(CurrentQuestion: boolean,request: void) : void
HTTPHeader(request: void) : String
processRequest(request: void) : void
doGet(request: void) : void
doPost(request: void) : void
getServletInfo() : String
Figura 8.4: Classi del package eValServer.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-106-320.jpg)






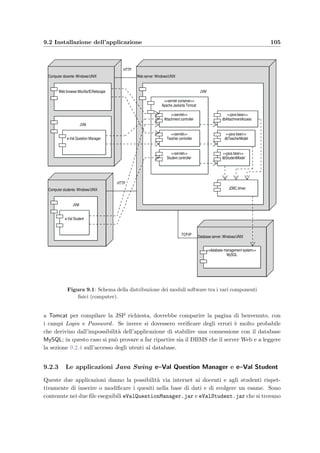




![9.3 I files di configurazione 107
• quelle degli studenti sono costituite dal numero di matricola (Student.Matricula) e
da un codice univoco per l’accesso ad un esame (Assignment.Password).
9.3 I files di configurazione
I vari moduli dell’applicazione leggono i parametri necessari al funzionamento da alcuni files
di configurazione in formato XML che ora verrano analizzati in dettaglio.
9.3.1 Il file web.xml
Questo file contiene i parametri di configurazione dell’applicazione server e si trova nella
directory TomcatDir/webapps/eVal/WEB-INF. Ogni volta che viene avviato Tomcat, il
servlet container legge i parametri che gli servono per configurare l’applicazione (mappature
dei servlet, parametri globali, regole di sicurezza, metodi di autenticazione, dichiarazioni delle
librerie di tag, ecc.) e altri parametri che vengono messi a disposizione dei singoli servlet.
Per una descrizione approfondita della sua struttura e per il significato completo dei tag
si rimanda a [1] e [25]. Vengono ora esaminati i parametri pi`u significativi per l’applicazione:
• configurazione del database server: le seguenti righe
context−param
param−names e r v e r/param−name
param−valuel o c a l h o s t : 3 3 0 6/param−value
/ context−param
servono per specificare il nome del server e la porta (di solito MySQL `e configurato con
la 3306);
• configurazione dell’accesso per l’amministratore: le righe
init −param
2 param−nameadmin login/param−name
param−valuea dm i ni st rat or/param−value
4 / ini t −param
init −param
6 param−nameadmin password/param−name
param−valuepassword/param−value
8 / ini t −param
permettono di settare la login (riga 3) e la password (riga 7) dell’amministratore del
sistema;
• configurazione automatica dei client:
init −param
param−namec l i e n t c o n f i g/param−name
param−valuetrue/param−value
/ init −param](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-118-320.jpg)


![110 Manuale dell’amministratore
param−namet i m e r p e r i o d/param−name
param−value4/param−value
setta il periodo in secondi del timer interno per la gestione dei vari task tra cui anche
quello dell’aggiornamento della visualizzazione del tempo rimanente allo studente (in
questo caso viene aggiornato ogni 4 secondi); gli intervalli precedenti devono essere presi
maggiori o uguali a questo valore.
9.4 I files di log
L’applicazione installata sul server e i client Java generano dei file di log salvati nella directory
home dell’utente; contengono vari tipi di informazioni tengono traccia della data e dell’ora di
inserimento degli eventi, come in questo esempio:
[13-dic-2002 12.28.21]: Il servlet docente `e attivo
[13-dic-2002 12.28.42]: Amministratore autenticato:[host]: localhost:8080
[user-agent]: Mozilla/5.0 ...
[13-dic-2002 12.29.02]: Docente autenticato:[host]: localhost:8080
[user-agent]: Mozilla/5.0 (Windows; ...
I tipi di messaggi che vengono inseriti riguardano:
• l’avvenuta autenticazione dei docenti e degli amministratori;
• le autenticazioni fallite da parte degli amministratori, dei docenti e degli studenti;
• gli avvisi di avvio o di fuori servizio dei pool di connessioni con il database;
• gli errori interni dell’applicazione server;
• le queries che al momento dell’esecuzione hanno generato un errore;
• le invalidazione di sessioni HTTP rimaste aperte.
9.5 I servizi di amministrazione accessibili dal Web
La creazione di nuovi corsi e la cancellazione di quelli inutilizzati nel database vengono eseguite
dall’amministratore, accedendo tramite un browser all’indirizzo
localhost:8080/eVal/Welcome.teacher
ed inserendo la login e la password di amministrazione cos`ı come sono settate nel file web.xml
(vedi 9.3.1).](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-121-320.jpg)
![9.5 I servizi di amministrazione accessibili dal Web 111
Figura 9.2: Administration – Cancellazione di un corso
9.5.1 Cancellazione di un corso [Administration]
t figura 9.2
A questo punto comparir`a la pagina di amministrazione in cui si possono vedere i corsi pre-
senti nel database con i relativi docenti. Per eliminare definitivamente un corso che non deve
contenere alcun esame `e sufficiente sceglierlo dalla lista e premere il bottone Elimina corso .
Client dello studente avvia lo scaricamento dell’applicazione e–Val Student per lo svolgimento
degli esami. Il bottone Nuovo corso permette invece di aprire il form per l’inserimento di
un nuovo corso.
Figura 9.3: NewCourse – Creazione di un nuovo corso](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-122-320.jpg)
![112 Manuale dell’amministratore
9.5.2 Creazione di un nuovo corso [NewCourse]
t figura 9.3
Per inserire un nuovo corso `e necessario specificare un nome che lo identifichi univoca-
mente; i campi Login e Password saranno usati per consentire l’accesso da parte del docente
al corso di appartenenza. Se tutto `e corretto, cliccando su Inserisci corso il nuovo corso verr`a
inserito nel database e ricomparir`a la pagina principale con la lista aggiornata dei corsi.
9.6 Incrementare le prestazioni
Le prestazioni del sistema possono essere penalizzate da due fattori principali:
• il grande numero di studenti che svolgono contemporaneamente gli esami (varie decine
di studenti) che incide sulla prontezza del sistema solamente durante gli appelli d’esame;
• la grande mole di dati contenuta nella base di dati (centinaia di compiti svolti) che
rallentano l’esecuzione delle varie queries.
Il primo caso pu`o essere risolto incrementando il numero di connessioni contemporaneamente
aperte dal pool di connessioni; ci`o si realizza cambiando i parametri di configurazione descritti
a pagina 108 e facendo ripartire il server Web.
Il secondo caso `e invece pi`u difficile da affrontare perch´e richiede di individuare ed analizza-
re quali siano le queries verso il database pi`u critiche, cio`e quelle che rallentano notevolmente
il sistema; non appena si `e individuata la query, la soluzione `e quella di creare degli indici
sulle chiavi secondarie del database per velocizzare le operazioni di reperimento dei dati; per
fare ci`o si pu`o usare il comando:
CREATE INDEX index_name ON tbl_name ( col_name [( length )] ,... )
Nel definire un nuovo indice bisogna fare attenzione allo spazio che occupa dopo la sua
creazione; `e infatti proporzionale al numero di record della tabella.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-123-320.jpg)

![114 Manuale del docente
corrispondente alla pagina in esame, indica la pagina o le pagine che la precedono, indica
invece le pagine alle quali si pu`o accedere.
Figura 10.1: Welcome – Pagina di benvenuto
10.1.1 Pagina di benvenuto [Welcome]
t figura 10.1
Header alla sezione 10.1.2
Menu alla sezione 10.1.3
`E la pagina iniziale che permette al docente di inserire la propria login (campo Login) e
la propria password (campo Password) ed accedere al sistema. Se l’autenticazione non va a
buon fine viene visualizzato una pagina di errore.
Figura 10.2: Header – Comandi della testata principale](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-125-320.jpg)
![10.1 Accesso dal Web 115
10.1.2 Testata principale [Header]
t figura 10.2
Welcome alla sezione 10.1.1
Menu alla sezione 10.1.3
ModifyCourse alla sezione 10.1.4
Il menu `e sempre disponibile durante la navigazione tra le pagine; i comandi danno la
possibilit`a di tornare al menu principale o alla pagina precedente, di aggiornare la pagina
corrente con i dati pi`u recenti, di modificare i dati di un corso ( Modifica dati corso per
cambiare per esempio la login e la password d’accesso) e di uscire dall’applicazione e terminare
la sessione corrente.
Figura 10.3: Menu – Menu principale dell’applicazione del docente
10.1.3 Menu principale [Menu]
t figura 10.3
Welcome alla sezione 10.1.1
NewTest alla sezione 10.1.21
ShowTest alla sezione 10.1.19
ModifyTest alla sezione 10.1.20
NewArgument alla sezione 10.1.18
ModifyArgument alla sezione 10.1.16
NewExam alla sezione 10.1.5
ModifyExam alla sezione 10.1.6
ShowExamDone alla sezione 10.1.8
Il menu principale contiene gli elenchi degli esami finora svolti o programmati, dei compiti
creati e degli argomenti del corso che raggruppano le domande presenti nella base di dati. Gli
elementi delle liste possono essere scelti con un doppio click oppure selezionando l’elemento](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-126-320.jpg)
![116 Manuale del docente
desiderato e premendo il bottone Vai . Il bottone Elimina permette di eliminare uno o
pi`u elementi delle liste con le seguenti regole:
• un argomento non pu`o essere eliminato se raccoglie ancora dei quesiti;
• un compito non pu`o essere eliminato se `e stato assegnato in un esame;
• quando viene eliminato un esame vengono cancellate anche le risposte degli studenti.
Il bottone Nuovo permette di creare un nuovo esame, un nuovo compito oppure aggiungere
un argomento. Il bottone Copia duplica il compito selezionato e permette di modificarlo;
Aggiorna difficolt`a quesiti ricalcola il grado di difficolt`a di ogni quesito tenendo conto delle
risposte date dagli studenti durante tutti gli esami svolti fino a quel momento: la difficolt`a
viene calcolata come il numero delle risposte esatte diviso il numero di tutte le volte che quel
quesito `e stato assegnato ad uno studente. Client dello studente permette di scaricare e–Val
Student, l’applicazione java necessaria per l’esecuzione degli esami; infine Aggiorna intervallo
stabilisce l’intervallo di mesi oltre il quale non visualizzare gli elementi creati precedentemente.
Figura 10.4: ModifyCourse – Form per la modifica dei dati del corso
10.1.4 Modifica dei dati del corso [ModifyCourse]
t figura 10.4
Header alla sezione 10.1.2
Questa pagina permette di cambiare il nome del corso e il nome del docente; si possono
modificare anche la login di accesso e la password (dopo la modifica cliccare su Salva login ).
10.1.5 Creazione di un nuovo esame [NewExam]
t figura 10.5
Menu alla sezione 10.1.3
ModifyExam alla sezione 10.1.6
Per la creazione di un nuovo esame sono necessarie le seguenti informazioni:](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-127-320.jpg)
![10.1 Accesso dal Web 117
Figura 10.5: NewExam – Form per la creazione di un nuovo esame
• nome dell’esame;
• data dell’esame: per sceglierne una basta selezionare l’anno, il mese e cliccare sul giorno
desiderato (evidenziato con il colore arancione);
• durata dell’esame in minuti;
• il numero di studenti per gruppo: corrisponde al massimo numero di computer disponi-
bili nell’aula di informatica per svolgere l’esame o il massimo numero di studenti che
possono contemporaneamente partecipare all’esame;
• un avviso per lo studente che gli verr`a mostrato prima di iniziare l’esame.
Quando sono state inserite tutte le informazioni, `e necessario cliccare Salva l’esame .
10.1.6 Modifica di un esame ancora da sostenere [ModifyExam]
t figura 10.6
Menu alla sezione 10.1.3
NewExam alla sezione 10.1.5
PrintExamStudentList alla sezione 10.1.7
I campi modificabili sono gli stessi descritti a pagina 116 con l’aggiunta delle procedure
per iscrivere gli studenti ed assegnare loro un compito. Per iscrivere nuovi studenti `e neces-
sario scrivere (o usare un copia–incolla) nell’area di testo del form, il numero di matricola](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-128-320.jpg)

![10.1 Accesso dal Web 119
La password `e costituita da due lettere alfabetiche (senza distinzione tra maiuscole e mi-
nuscole) e da due numeri scelti casualmente. Sono uniche per ogni studente perch´e devono
identificare l’appelo d’esame a cui lo studente partecipa.
Figura 10.7: PrintExamStudentList – Tabella d’esame necessaria per far sostenere
gli esami agli studenti
10.1.7 Stampa della tabella d’esame [PrintExamStudentList]
t figura 10.7
ModifyExam alla sezione 10.1.6
ShowExamDone alla sezione 10.1.8
Questa lista deve essere stampata e resa disponibile agli studenti che devono partecipare
all’appello d’esame; infatti solamente conoscendo la password uno studente pu`o sostenere
l’esame.
10.1.8 Esame svolto o in corso di svolgimento [ShowExamDone]
t figura 10.8
Menu alla sezione 10.1.3
PrintExamStudentList alla sezione 10.1.7
PrintExamResult alla sezione 10.1.9
ShowExamStudent alla sezione 10.1.10
ShowTestUsed alla sezione 10.1.13
La pagina contiene la lista degli studenti presenti all’esame scelto, il tempo che hanno
impiegato per rispondere alle domande, il compito a loro assegnato, il punteggio in cen-
tesimi ottenuto e il voto in trentesimi calcolato in base allo schema di correzione scelto.
Correggi di nuovo permette di rifare la correzione delle risposte date (necessario solamente
nel caso in cui siano stati modificati i quesiti successivamente allo svolgimento dell’esame).
Per stampare i risultati dell’esame basta cliccare su Tabella risultati ; selezionando Filtro voti
vengono visualizzati solamente i voti maggiori o uguali a 18; si pu`o anche stabilire il voto in
trentesimi oltre il quale assegnare la lode; infine possono essere nascosti gli assenti.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-130-320.jpg)

![10.1 Accesso dal Web 121
• considerare, per le domande a scelta multipla (CHECKBOX), anche le risposte parziali (che
altrimenti verrebbero considerate errate): il peso della risposta esatta viene moltiplicato
per il grado di correttezza della risposta.
La terminologia usata `e la seguente: Correttezza e Punteggio sono valori compresi tra 0 (peg-
giore) e 1 (migliore) espressi talvolta in percentuale (%) mentre Difficolt`a = 1−Correttezza
quindi ha valori compresi tra 0 (facile) e 1 (difficile). La correttezza o la difficolt`a di un compito
sono la media delle correttezze o delle difficolt`a dei singoli quesiti.
In definitiva supponendo che il compito sia formato da n quesiti il voto per ogni studente
viene calcolato in questo modo:
V oto in trentesimi =
1
n
·
n
i=1
(p(i) + ai) · Slope + Offset (10.1)
non appena siano definiti
• la pendenza della retta di conversione:
Slope =
V oto max − V oto min
Punteggio max − Punteggio min
(10.2)
• l’offset della medesima:
Offset =
(V oto min × Punteggio max) − (V oto max × Punteggio min)
Punteggio max − Punteggio min
(10.3)
• la funzione di pesatura:
p(i) =
Peso risposta corretta se la risposta `e corretta
Peso risposta non data se non `e stata data la risposta
Peso risposta errata se la risposta `e errata
e non si considerano le risposte parziali
Correttezza risposta× se la risposta `e parzialmente corretta
Peso risposta corretta e si considerano le risposte parziali
(10.4)
• i punteggi aggiunti alle singole domande di un compito inserito nel form ShowTestUsed
alla sezione 10.1.13:
ai = valore aggiunto alla domanda (tra 0 e 1). (10.5)
10.1.9 Stampa della lista dei risultati [PrintExamResult]
t figura 10.9
ShowExamDone alla sezione 10.1.8
La pagina contiene la lista degli studenti e dei risultati che hanno ottenuto all’esame scelto:
le modalit`a di visualizzazione (lode, filtro assenti, filtro voti insufficienti) sono definite nella
pagina precedente (ShowExamDone alla sezione 10.1.8).](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-132-320.jpg)
![122 Manuale del docente
Figura 10.9: PrintExamResult – Lista degli studenti che hanno svolto un esame
e risultati
Figura 10.10: ShowExamStudent – Compito svolto o in corso di svolgimento dello
studente
10.1.10 Compito svolto o in corso di svolgimento dello studente [ShowEx-
amStudent]
t figura 10.10
ShowExamDone alla sezione 10.1.8
PrintStudentTest alla sezione 10.1.11
ShowQuestion alla sezione 10.1.12
La pagina mostra i quesiti assegnati allo studente, le risposte corrette, le risposte date
dallo studente, la correttezza (calcolata dal correttore automatico), il punteggio assegnato
in base al peso delle risposte e all’eventuale valore aggiunto ed infine il voto in trentesi-
mi. Cliccando su un quesito viene visualizzato il testo della domanda, mentre cliccando su](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-133-320.jpg)
![10.1 Accesso dal Web 123
Mostra compito si vede il compito completo assegnato allo studente. C’`e anche la possibilit`a
di cambiare il punteggio assegnato dal correttore automatico (aggiornando con il bottone
Aggiorna correttezza quesiti ). Infine pi`u sotto `e presente una lista con le azioni compiute
dallo studente.
Le azioni compiute durante lo svolgimento dell’esame
Il sistema registra ogni azione che lo studente compie durante lo svolgimento dell’esame e
l’ora in cui `e stata compiuta; i tipi di azioni registrate sono le seguenti:
Tipo Descrizione
Login lo studente ha richiesto il primo login per svolgere l’esame:
vengono annotate anche le informazioni sul client HTTP
ReLogin lo studente ha richiesto di nuovo un login per continuare a
svolgere l’esame
TimeExpired lo studente ha terminato il tempo a disposizione
ExamEnded lo studente ha terminato l’esame (perch´e ha risposto a tutti
i quesiti o perch´e ha volontariamente concluso l’esame)
Iconified lo studente ha ridotto ad icona il client
LostFocus lo studente ha cercato di abbandonare il client
CloseClientNow lo studente ha volontariamente chiuso il client
Figura 10.11: PrintStudentTest – Compito assegnato ad uno studente
10.1.11 Compito assegnato ad uno studente [PrintStudentTest]
t figura 10.11
ShowExamStudent alla sezione 10.1.10
Visualizza il testo di tutti i quesiti del compito assegnato ad uno studente.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-134-320.jpg)
![124 Manuale del docente
Figura 10.12: ShowQuestion – Esempio di quesito
10.1.12 Visualizzazione di un quesito [ShowQuestion]
t figura 10.12
ShowExamStudent alla sezione 10.1.10
ShowTest alla sezione 10.1.19
ModifyTest alla sezione 10.1.20
Rappresenta il testo di un quesito con la risposta corretta.
Figura 10.13: ShowTestUsed – Rapporto su un compito svolto](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-135-320.jpg)
![10.1 Accesso dal Web 125
10.1.13 Rapporto su un compito svolto [ShowTestUsed]
t figura 10.13
ShowExamDone alla sezione 10.1.8
PrintTest alla sezione 10.1.14
ModifyQuestion alla sezione 10.1.15
Questa pagina mostra i quesiti che compongono un tema d’esame dato ad un appello, il
calcolo delle difficolt`a relative all’appello scelto e quelle relative a tutti gli appelli precedenti.
Si ha la possibilit`a di aggiungere un punteggio che verr`a sommato al punteggio ottenuto da
ogni studente che aveva nel compito quel quesito (premere Aggiorna punteggi per rendere
effettive le modifiche); questo per esempio permette al docente di assegnare come corretto un
quesito, indipendentemente dalla risposta data dagli studenti. Se si clicca sul memorandum
di un quesito del compito si possono visualizzare e modificare i dati di quel quesito (vedi
ModifyQuestion alla sezione 10.1.15). La difficolt`a del compito visualizzata subito sotto il
titolo `e quella calcolata nel momento in cui si `e creato il compito e non tiene conto dei
risultati ottenuti in questo appello.
Figura 10.14: PrintTest – Compito assegnato per un appello d’esame
10.1.14 Compito assegnato per un appello d’esame [PrintTest]
t figura 10.14
ShowTestUsed alla sezione 10.1.13
ShowTest alla sezione 10.1.19
Visualizza un compito con tutti i quesiti e le risposte corrette.
10.1.15 Modifica di un quesito [ModifyQuestion]
t figura 10.15
ShowTestUsed alla sezione 10.1.13
ModifyArgument alla sezione 10.1.16
Il form permette di modificare il memorandum del quesito, il commento ed eventualmente
di ridefinire la risposta corretta; per cambiare la risposta basta riempire i campi del form
come se si dovesse rispondere alla domanda e premere Aggiorna risposta corretta . Per una
descrizione completa dei possibili tipi di risposte si rimanda alla sezione 10.2.1. Se si cambia
la risposta corretta di un quesito dato ad un esame `e necessario far eseguire di nuovo la
correzione dei compiti (vedi ShowExamDone alla sezione 10.1.8).](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-136-320.jpg)
![126 Manuale del docente
Figura 10.15: ModifyQuestion – Quesito di esempio
10.1.16 Modifica di un argomento [ModifyArgument]
t figura 10.16
Menu alla sezione 10.1.3
PrintArgument alla sezione 10.1.17
ModifyQuestion alla sezione 10.1.15
In questa pagina `e possibile modificare il nome e la descrizione dell’argomento. Inoltre
la lista dei quesiti presenti permette di selezionare alcuni quesiti (cliccando sul quadratino a
sinistra del memorandum) e di compiere una delle seguenti azioni:
• spostarli in un altro argomento (scegliendo l’argomento destinatario dalla lista e clic-
cando su Sposta in );
• vederli premendo su Mostra quesiti (vedi PrintArgument alla sezione 10.1.17);
• scaricarli in formato HTML compresso (.zip) assieme agli allegati per avere una copia
di backup;
• cancellarli se non sono presenti in qualche compito.
Il bottone Inserisci nuovi quesiti avvia lo scaricamento del client docente e–Val Question
Manager necessario per modificare o inserire nuovi quesiti. Cliccando sul memorandum si
visualizza il quesito (vedi ModifyQuestion alla sezione 10.1.15).](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-137-320.jpg)
![10.1 Accesso dal Web 127
Figura 10.16: ModifyArgument – Modifica di un argomento
Figura 10.17: PrintArgument – Quesiti selezionati di un argomento
10.1.17 Stampa di un argomento [PrintArgument]
t figura 10.17
ModifyArgument alla sezione 10.1.16](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-138-320.jpg)
![128 Manuale del docente
Il codice HTML di questa pagina `e scritto in modo da fornire una copia di backup dei
quesiti scelti nella pagina precedente. Se infatti viene salvata o meglio se viene scaricata in
formato compresso assieme agli allegati (vedi Scarica quesiti in ModifyArgument alla sezione
10.1.16), pu`o essere reinserita direttamente nel client e–Val Question Manager, per ricostruire
esattamente i quesiti nella base di dati.
Figura 10.18: NewArgument – Form per la creazione di un nuovo argomento
10.1.18 Creazione di un nuovo argomento [NewArgument]
t figura 10.18
Menu alla sezione 10.1.3
ModifyArgument alla sezione 10.1.16
Permette di inserire un nuovo argomento con un nome e una sua descrizione.
Figura 10.19: ShowTest – Lista dei quesiti di un compito gi`a assegnato
10.1.19 Visualizzazione di un compito gi`a assegnato [ShowTest]
t figura 10.19
Menu alla sezione 10.1.3
PrintTest alla sezione 10.1.14
ShowQuestion alla sezione 10.1.12
Questa pagina mostra la lista dei quesiti che formano un compito `e gi`a stato assegnato ad
un esame e che quindi non `e pi`u modificabile. Si possono vedere le singole domande (cliccando
sul memorandum del quesito) oppure il compito completo (cliccando su Mostra compito ).](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-139-320.jpg)
![10.1 Accesso dal Web 129
Figura 10.20: ModifyTest – Form di modifica di un compito
10.1.20 Modifica di un compito non ancora assegnato [ModifyTest]
t figura 10.20
Menu alla sezione 10.1.3
NewTest alla sezione 10.1.21
ShowQuestion alla sezione 10.1.12
Questa pagina permette di modificare un compito aggiungendo o togliendo quesiti dagli
argomenti disponibili: per aggiungere un quesito basta cliccare su Aggiungi accanto ad uno
dei quesiti appartenenti all’argomento a destra oppure selezionando pi`u quesiti e premendo il
bottone Inserisci nel compito . Per rimuovere viceversa i quesiti dal compito basta selezionare i
quesiti da togliere e cliccare su Rimuovi quesito . Si pu`o anche assegnare un ordine prestabilito
(ordine di default) per la presentazione dei quesiti allo studente, assegnando un numero ad
ogni quesito, in base al quale verr`a ordinato; se invece si vuole che ogni studente abbia un
ordine di visualizzazione casuale allora `e sufficiente scegliere come Ordinamento dei quesiti
l’opzione random. Anche qui `e possibile visualizzare il testo di un singolo quesito o quello
dell’intero compito cliccando rispettivamente sui memorandum o su Mostra compito .
10.1.21 Creazione di un nuovo compito [NewTest]
t figura 10.21
Menu alla sezione 10.1.3
ModifyTest alla sezione 10.1.20
Permette di inserire un nuovo compito con un titolo che lo identifichi scegliendo l’ordina-
mento desiderato dei quesiti (vedi ModifyTest alla sezione 10.1.20).](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-140-320.jpg)
![130 Manuale del docente
Figura 10.21: NewTest – Form per la creazione di un nuovo compito
10.2 Inserimento dei quesiti: e–Val Question Manager
Questa applicazione Java permette l’inserimento di nuovi quesiti e la modifica di quelli esi-
stenti; si scarica dalla pagina web ModifyArgument alla sezione 10.1.16 e pu`o essere usata da
qualsiasi computer che abbia la possibilit`a di stabilire un collegamento HTTP via Internet.
Per eseguire l’applicazione `e necessario che sia installata una JVM e digitare da una shell, il
seguente comando (specificando se necessario il nome del server):
java -jar eValQuestionManager.jar [nome del server]
Interfaccia grafica La finestra `e divisa in due parti (vedi la figura 10.22): un browser Web
nella parte superiore e vari comandi per il settaggio del parser e l’inserimento dei quesiti.
10.2.1 Il parser
e-Val accetta come quesiti validi qualsiasi documento HTML contenente dei campi che diano
la possibilit`a di dare una risposta. Per riconoscere la tipologia di risposta, ricavare la risposta
corretta, distillare opportunamente il codice HTML, e–Val Question Manager sottopone il
documento al parser che lo analizza prima di inserirlo nel database: i messaggi generati
durante questa operazione sono visualizzati nel riquadro in basso a destra.
10.2.2 Tipologie di quesiti
I tipi di quesiti in formato HTML che possono essere inseriti devono far parte di una di queste
quattro categorie:
Risposte a scelta singola (RADIO)
Lo studente pu`o scegliere una sola risposta tra quelle presentate, come si pu`o vedere in questo
esempio:](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-141-320.jpg)
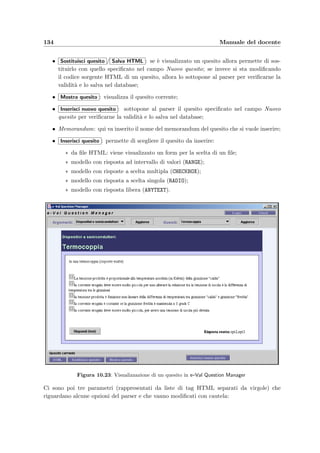



![10.2 Inserimento dei quesiti: e–Val Question Manager 135
• Tag separatori: questi tag vengono utilizzati per separare pi`u quesiti all’interno dello
stesso documento HTML;
• Tag da escludere: i tag di questa lista vengono rimossi dal documento e non vengono
quindi salvati (utile per eliminare per esempio i link ipertestuali);
• Tag senza attributi: da questi tag verrano eliminati tutti gli attributi eventualmente
presenti (utile per i documenti HTML generati dagli editor grafici in cui per esempio
i tag P contengono spesso informazioni sulla formattazione grafica dei paragrafi, che
potrebbero venire visualizzati non correttamente).
Nelle pagine del browser integrato sono presenti dei bottoni che sono di facile comprensione
(vedi la figura 10.23):
• Argomenti: la lista contiene gli argomenti del corso; quando si cambia un argomento `e
necessario premere il pulsante Aggiorna ;
• Quesiti: la lista contiene i quesiti dell’argomento scelto; quando si cambia la selezione
di un quesito `e necessario premere il pulsante Aggiorna ;
• Rispondi (test) : questo bottone serve per verificare che l’invio al server Web delle
risposte dei quesiti avvenga correttamente; bisogna inserire una risposta qualsiasi, non
necessariamente quella giusta; e premere questo bottone: se la risposta non `e arrivata
correttamente al server verr`a visualizzato un messaggio di errore;
10.2.5 L’editor HTML
I quesiti inseriti nella base di dati possono venire modificati premendo il tasto HTML quando
`e visualizzato il quesito che interessa; la finestra allora cambia aspetto e si accede all’editor
illustrato in figura 10.24. In questa modalit`a `e anche possibile inserire un’immagine salvata
in un file premendo CTRL + [tasto sinistro del mouse]; per agevolare l’editing vengono
evidenziati i memorandum e i commenti; una volta terminata la modifica occorre premere il
tasto Salva HTML perch´e il quesito venga analizzato dal parser e salvato nella base di dati.
Se si preme Mostra quesito si ritorna alla normale visualizzazione del quesito corrente.
Anche se i documenti non sono strettamente conformi allo standard HTML, il parser cerca
comunque di ricavarne le informazioni utili alla definizione del tipo di risposta e della risposta
esatta; se segnala ci`o non `e possibile lo segnala con un messaggio di errore.
10.2.6 Procedura per l’inserimento di un quesito
Vengono ora descritte le operazioni da compiere per l’inserimento di un quesito:
• si seleziona l’argomento in cui si vuole inserire il quesito o i quesiti e si preme il bottone
Aggiorna ;
• si inserisce nella casella di testo Memorandum un nome che descriva il quesito e che lo
identifichi univocamente all’interno dell’argomento;](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-146-320.jpg)
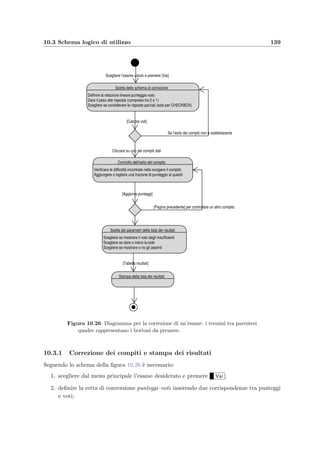

![138 Manuale del docente
Creazione di un nuovo compito
Inserire un titolo per il compito
Specificare l’ordinamento dei quesiti
Creazione di un nuovo argomento
Inserire un nome per l’argomento
Inserire una descrizione
Inserimento di alcuni quesiti
Avvio dell’applet per inserire nuovi quesiti
Premere il pulsante [Mostra quesiti]
Scegliere l’argomento e premere il pulsante [Aggiorna]
Inserire un memorandum valido
Premere il pulsante [Inserisci quesiti]
Scegliere il tipo di quesito che si vuole inserire
Premere il pulsante [Inserisci nuovo quesito]
Modificare eventualmente il quesito premendo il pulsante [HTML]
Ripetere le precedenti operazioni per inserire più quesiti
Inserimento di quesiti nel compito
Selezionare i quesiti da aggiungere
Premere il pulsante [Inserisci nel compito]
Oppure cliccare direttamente su [Aggiungi]
a fianco di ogni quesito
Creazione di un nuovo esame
Inserire un nome per l’appello d’esame
Scegliere la data e l’ora dell’appello
Inserire la durata dell’esame
Inserire il numero di studenti per ogni gruppo
Inserire se necessario un avviso per lo studente
Iscrizione degli studenti all’esame
Srivere nell’area di testo la lista degli studenti
Assegnazione dei compiti
Selezionare uno o più compiti dalla tabella dei compiti disponibili
Tabella d’esame degli studenti iscritti
Controllare che la tabella sia completa
Stampare la lista da affiggere in aula
Attivazione dell’esame
Attivare l’esame premendo sul [Sì]
Premere il pulsante [Nuovo] argomento
Scaricare l’applet e-Val Question Manager
[Salva l’argomento]
Già inseriti tutti gli argomenti necessari
[Menu principale] per crearne un altro
Premere [Menu principale] e successivamente [Nuovo] compito
[Salva il compito]
Selezionare un argomento tra quelli disponibili
[Menu principale] per crearne un altro
Premere il pulsante [Nuovo] esame
[Salva l’esame]
[Iscrivi studenti]
Iscrivere ancora studenti
[Menu principale], selezionare un esame e premere [Vai]
Già iscritti all’esame tutti gli studenti
[Pagina precedente]
Può iniziare lo svolgimento dell’esame
[Assegna compito] e [Tabella esame]
Figura 10.25: Diagramma per la preparazione di un’esame: i termini tra pa-
rentesi quadre rappresentano i bottoni da premere nei form delle pagine
Web.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-149-320.jpg)
![10.3 Schema logico di utilizzo 139
Scelta dello schema di correzione
Definire la relazione lineare punteggio-voto
Dare il peso alle risposte (compreso tra 0 e 1)
Scegliere se considerare le risposte parziali (solo per CHECKBOX)
Controllo dell’esito del compito
Verificare le difficoltà incontrate nello svolgere il compito
Aggiungere o togliere una frazione di punteggio ai quesiti
Scelta dei parametri della lista dei risultati
Scegliere se mostrare il voto degli insufficienti
Scegliere se dare o meno la lode
Scegliere se mostrare o no gli assenti
Stampa della lista dei risultati
Scegliere l’esame voluto e premere [Vai]
[Calcola voti]
Se l’esito dei compiti non è soddisfacente
Cliccare su uno dei compiti dati
[Aggiorna punteggi]
[Pagina precedente] per controllare un altro compito
[Tabella risultati]
Figura 10.26: Diagramma per la correzione di un’esame: i termini tra parentesi
quadre rappresentano i bottoni da premere.
10.3.1 Correzione dei compiti e stampa dei risultati
Seguendo lo schema della figura 10.26 `e necessario:
1. scegliere dal menu principale l’esame desiderato e premere Vai ;
2. definire la retta di conversione punteggi–voti inserendo due corrispondenze tra punteggi
e voti;](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-150-320.jpg)

![Capitolo 11
Manuale dello studente
Figura 11.1: Pagina di benvenuto di e–Val Student.
Questo manuale `e rivolto agli studenti che devono utilizzare il sistema e-Val per sostenere
un esame. Per mandare in esecuzione il client e–Val Student e cominciare a sostenere l’esame
bisogna aprire una shell e digitare il comando (specificando se necessario il nome del server)
java -jar eValStudent.jar [nome del server]
A questo punto dovrebbe comparire una pagina di benvenuto come `e mostrato nella figura
11.1); dopo qualche istante una piccola finestra chieder`a di inserire il numero di matricola e
la password.](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-152-320.jpg)









![Bibliografia
[1] David Harms: JSP, Servlet e MySQL, McGraw–Hill (2001)
Database
[2] Atzeni–Ceri–Paraboschi–Torlone: Basi di dati, McGraw–Hill (1999)
[3] Maristella Agosti: Appunti di Basi di Dati, Corso di laurea in Ingegneria
Informatica (A.A. 2000/2001)
[4] Axmark – Widenius – Cole – DuBois: MySQL Reference Manual, MySQL AB (2001)
[5] Marc A. Mnich: Multi Tier Architectures for Database Connectivity, JavaExchange
(1998)
[6] JavaExchange: DbConnectionBroker
www.javaexchange.com
[7] Jon Ellis – Linda Ho: JDBCTM 3.0 Specification, Sun Microsystems (2001)
Java
[8] Herbert Schildt: JavaTM 2 – The complete reference, McGraw–Hill (1999)
[9] James Gosling – Bill Joy – Guy Steele – Gilad Bracha: The JavaTM Language
Specification Second Edition, Addison–Wesley (2000)
[10] JavaTM 2 SDK, Standard Edition Documentation v1.3.1, Sun Microsystems (2001)
[11] Vari: The JavaTM tutorial, Sun Microsystems (2001)
[12] John D. Mitchell – Arthur Choi: Java Tip 49: How to extract Java resources from
JAR and zip archives, JavaWorld (1998)
[13] Z. Steve Jin – John D. Mitchell: Java Tip 120: Execute self–extracting JARs,
JavaWorld (2001)](https://image.slidesharecdn.com/a5c6f1f3-0738-4555-8f6d-4b583577efe2-160802140622/85/repairpdf_Oy51nCFX-162-320.jpg)















































