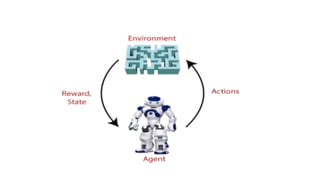
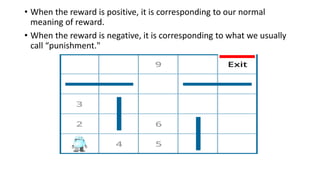
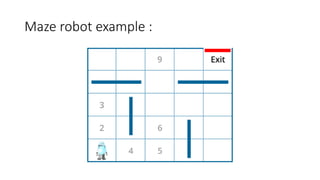
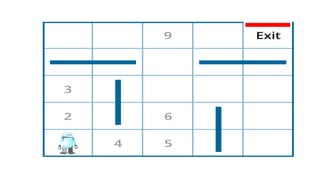
Reinforcement learning involves learning optimal actions through rewards or punishments, centered on three key concepts: state, action, and reward. The most common method, q-learning, enables agents to learn the long-term value of actions via a formula that incorporates learning and discount rates. While reinforcement learning excels in solving complex problems and mimics human learning, it does require significant time and computational resources.