The document discusses model fitting in deep learning, focusing on the concepts of underfitting and overfitting, and the importance of regularization techniques to improve model generalization. It details various regularization approaches such as early stopping, L1/L2 regularization, batch normalization, and dropout, explaining their mechanisms and effectiveness. Key takeaways include the relationships between model complexity, bias, variance, and methods to reduce overfitting for better performance in machine learning models.




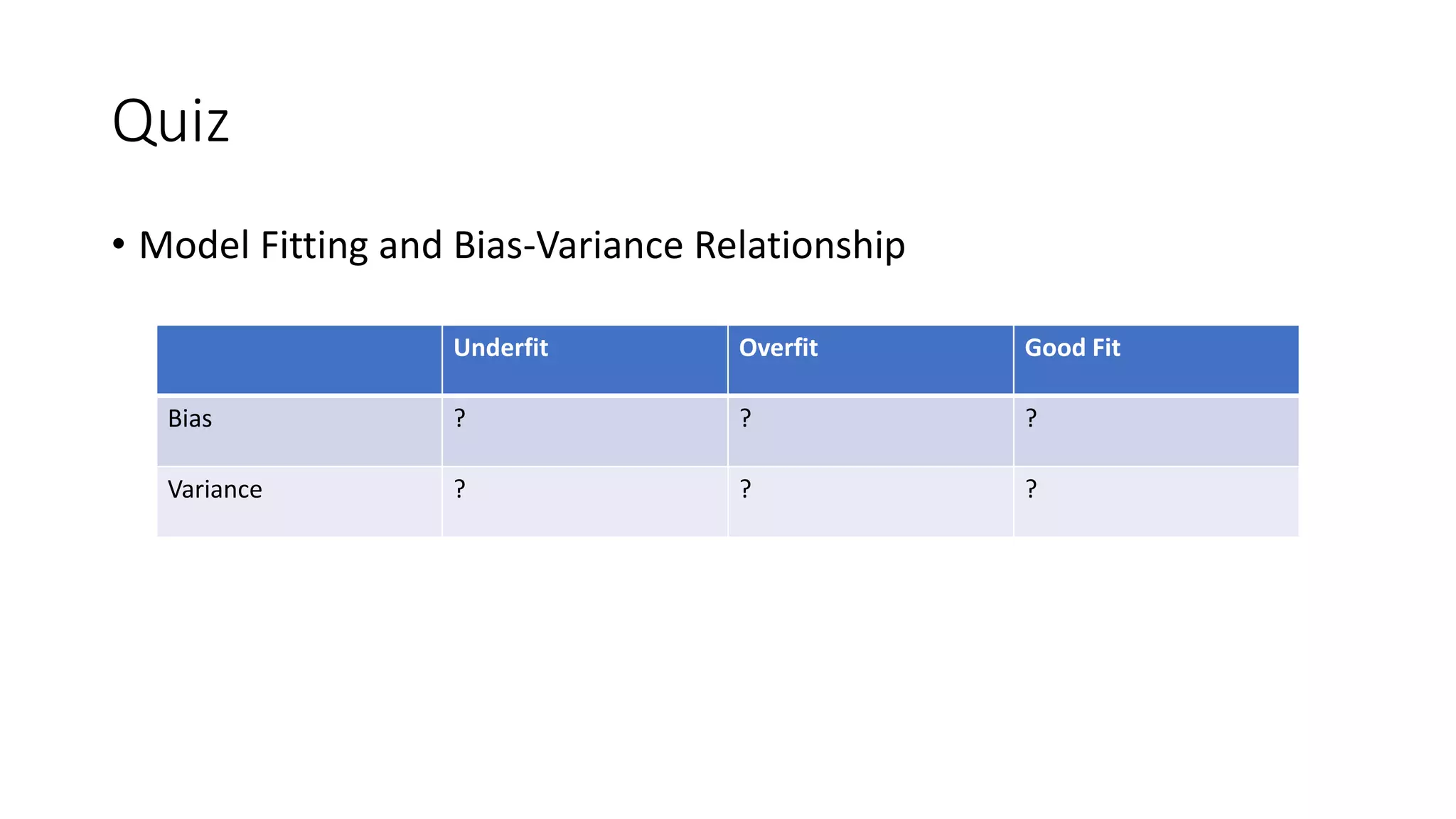
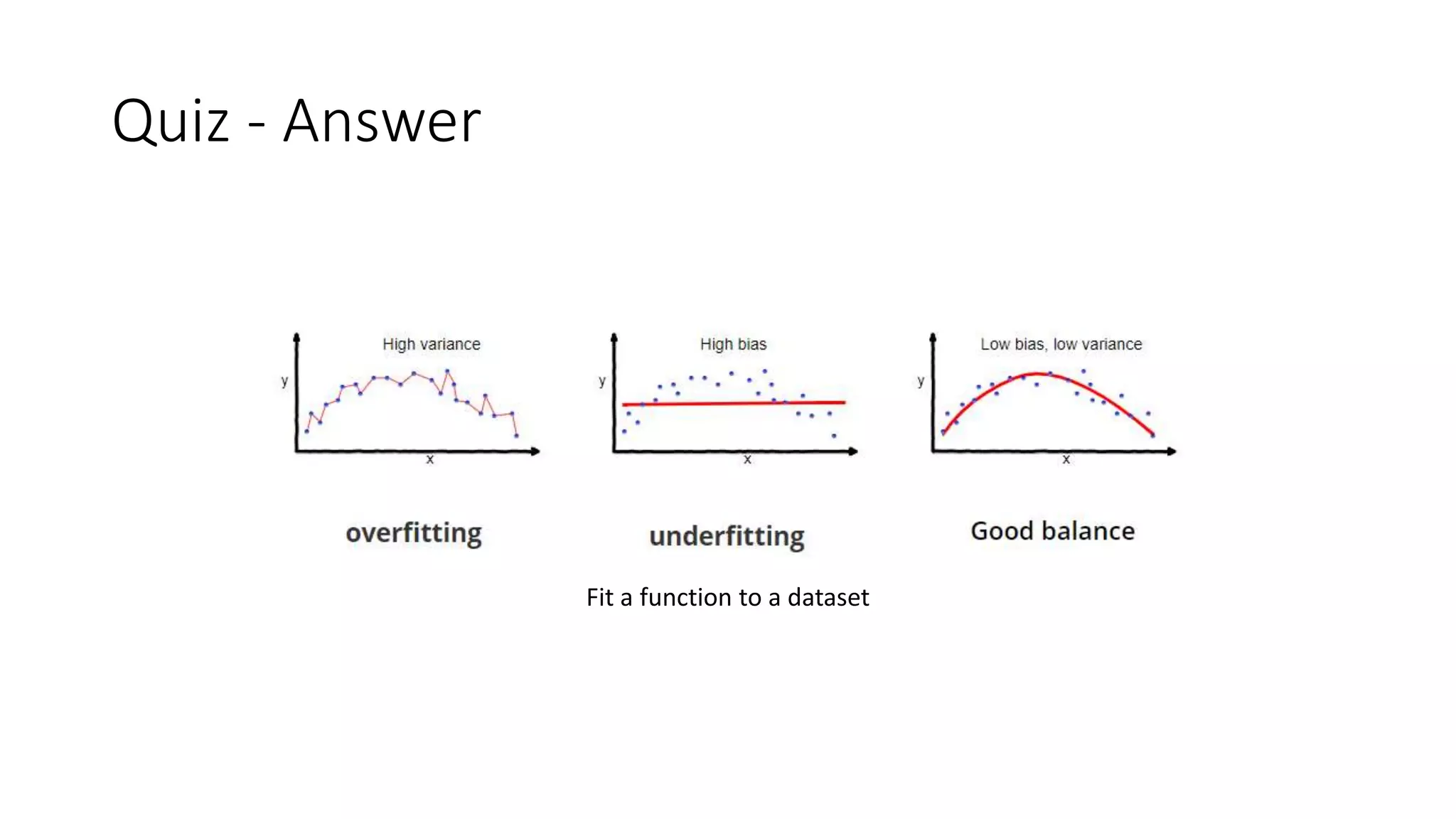
![Model Fitting – Visualization
Variations of model fitting [1]](https://image.slidesharecdn.com/yrzcfqwktpux4iwd8swb-signature-ecc2d8be78a6771d7b785613643b071af13ede63f3b314b1801b799316ccb3ef-poli-190527020506/75/Regularization-in-deep-learning-5-2048.jpg)
![Bias Variance
• Prediction errors [2]
𝐸𝑟𝑟𝑜𝑟 𝑥 = (𝐸 𝑓 𝑥 − 𝑓 𝑥 )2+𝐸 𝑓 𝑥 − 𝐸[ 𝑓 𝑥 ]
2
(Bias)2 Variance
𝐸𝑟𝑟𝑜𝑟 = (𝐴𝑣𝑔 𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 − 𝑇𝑟𝑢𝑒)2+𝐴𝑣𝑔(𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 − 𝐴𝑣𝑔(𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑))2](https://image.slidesharecdn.com/yrzcfqwktpux4iwd8swb-signature-ecc2d8be78a6771d7b785613643b071af13ede63f3b314b1801b799316ccb3ef-poli-190527020506/75/Regularization-in-deep-learning-6-2048.jpg)





![Regularization Definition
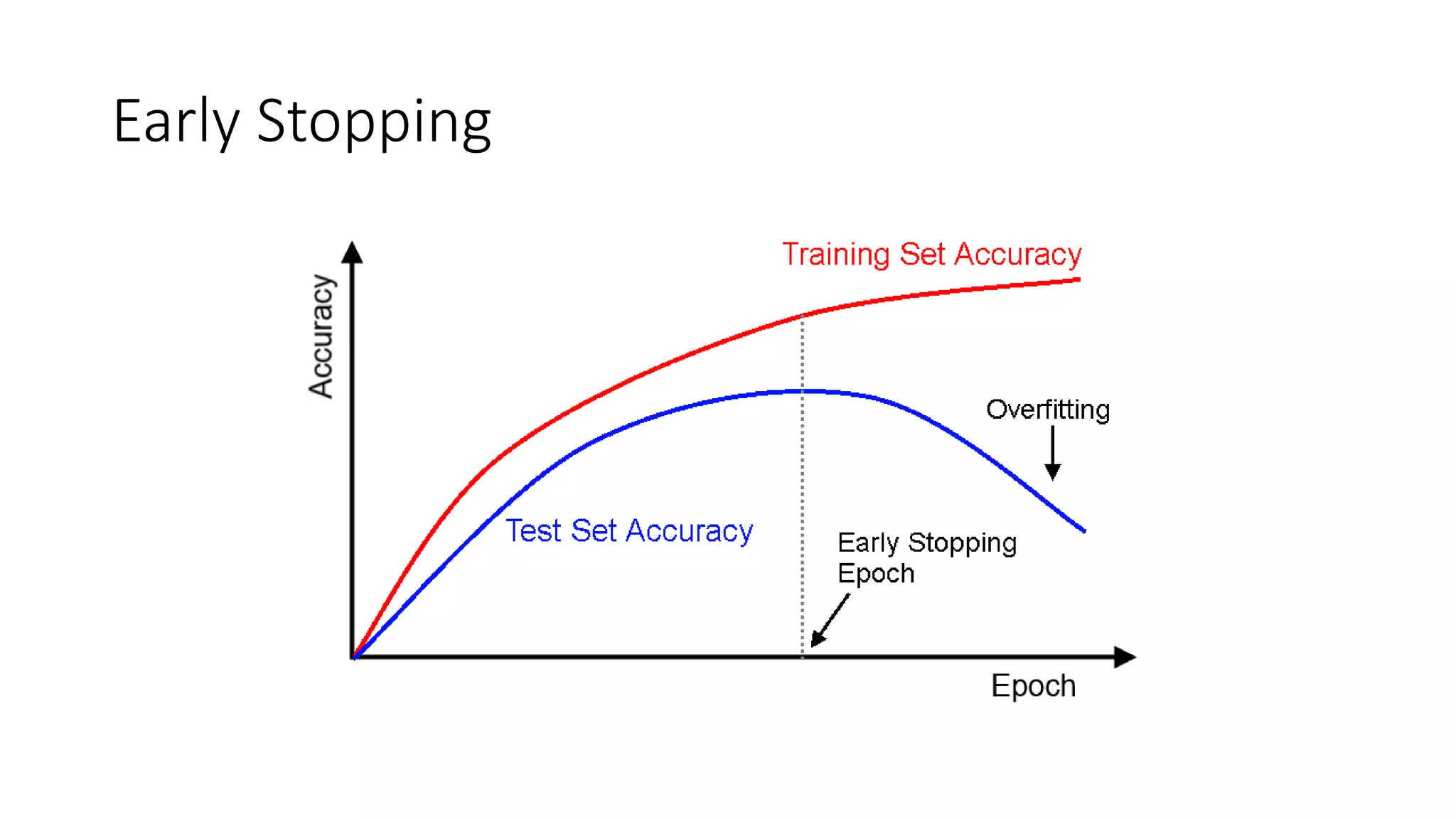
• Regularization is any modification we make to a learning algorithm
that is intended to reduce its generalization error but not its training
error. [4]](https://image.slidesharecdn.com/yrzcfqwktpux4iwd8swb-signature-ecc2d8be78a6771d7b785613643b071af13ede63f3b314b1801b799316ccb3ef-poli-190527020506/75/Regularization-in-deep-learning-14-2048.jpg)





![L1/L2 Regularization
• Regularization works on assumption that smaller weights generate
simpler model and thus helps avoid overfitting. [5]
• Why?](https://image.slidesharecdn.com/yrzcfqwktpux4iwd8swb-signature-ecc2d8be78a6771d7b785613643b071af13ede63f3b314b1801b799316ccb3ef-poli-190527020506/75/Regularization-in-deep-learning-21-2048.jpg)


![Sparsity ([3])
𝑤1 = 𝑤1 − 0.5 ∗ 𝑔𝑟𝑎𝑑𝑖𝑒𝑛𝑡 𝑤1 = 𝑤1 − 0.5 ∗ 𝑔𝑟𝑎𝑑𝑖𝑒𝑛𝑡
gradient is constant (1 or -1)
w1: 5->0 in 10 steps
gradient is smaller over time (
w2: 5->0 in a big number of steps](https://image.slidesharecdn.com/yrzcfqwktpux4iwd8swb-signature-ecc2d8be78a6771d7b785613643b071af13ede63f3b314b1801b799316ccb3ef-poli-190527020506/75/Regularization-in-deep-learning-25-2048.jpg)

![Batch Norm
• Original Paper Title:
• Batch Normalization: Accelerating Deep Network Training by Reducing
Internal Covariate Shift [6]
• Internal Covariate Shift:
• The change in the distribution of network activations due to the change in
network parameters during training.](https://image.slidesharecdn.com/yrzcfqwktpux4iwd8swb-signature-ecc2d8be78a6771d7b785613643b071af13ede63f3b314b1801b799316ccb3ef-poli-190527020506/75/Regularization-in-deep-learning-27-2048.jpg)






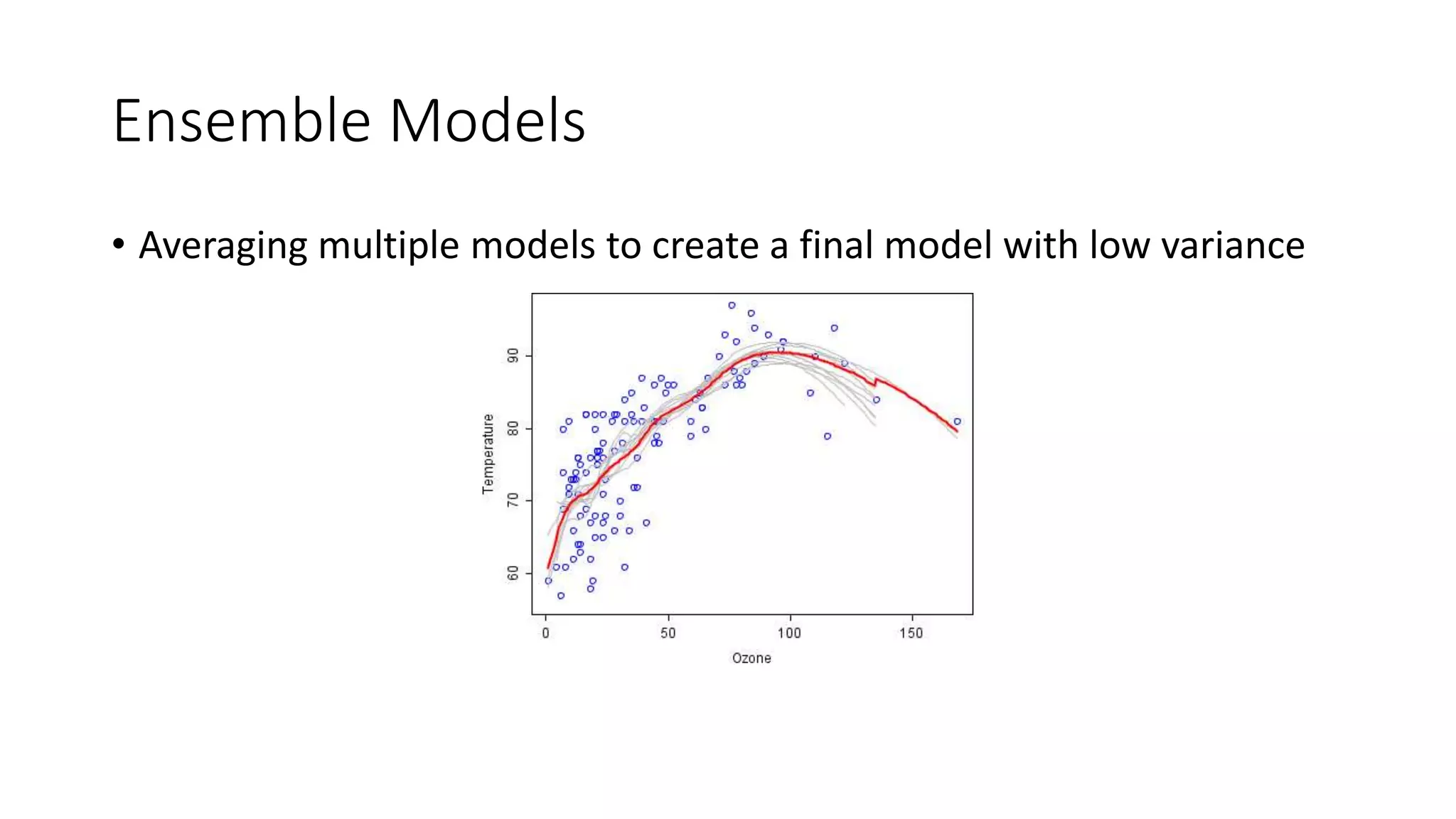







![References
• [1] https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-
learning-and-how-to-deal-with-it-6803a989c76
• [2] Pattern Recognition and Machine Learning, M. Bishop
• [3] https://stats.stackexchange.com/questions/45643/why-l1-norm-for-sparse-models
• [4] Deep Learning, Goodfellow et. al
• [5] https://medium.com/datadriveninvestor/l1-l2-regularization-7f1b4fe948f2
• [6] Batch Normalization: Accelerating Deep Network Training by Reducing Internal
Covariate Shift, Sergey Ioffe et al
• [7] https://towardsdatascience.com/batch-normalization-8a2e585775c9
• [8] Dropout: A Simple Way to Prevent Neural Networks from Overfitting Srivastava et al
• [9] https://machinelearningmastery.com/train-neural-networks-with-noise-to-reduce-
overfitting/
• [10] Popular Ensemble Methods: An Empirical Study, Optiz et. al](https://image.slidesharecdn.com/yrzcfqwktpux4iwd8swb-signature-ecc2d8be78a6771d7b785613643b071af13ede63f3b314b1801b799316ccb3ef-poli-190527020506/75/Regularization-in-deep-learning-42-2048.jpg)



































































