Downloaded 295 times


















![Autoencoders
>>> import tensorflow as tf
>>> from tensorflow.contrib.layers import fully_connected
>>> n_inputs = 3 # 3D inputs
>>> n_hidden = 2 # 2D codings
>>> n_outputs = n_inputs
>>> learning_rate = 0.01
>>> X = tf.placeholder(tf.float32, shape=[None, n_inputs])
>>> hidden = fully_connected(X, n_hidden, activation_fn=None)
>>> outputs = fully_connected(hidden, n_outputs, activation_fn=None)
>>> reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
>>> optimizer = tf.train.AdamOptimizer(learning_rate)
>>> training_op = optimizer.minimize(reconstruction_loss)
>>> init = tf.global_variables_initializer()
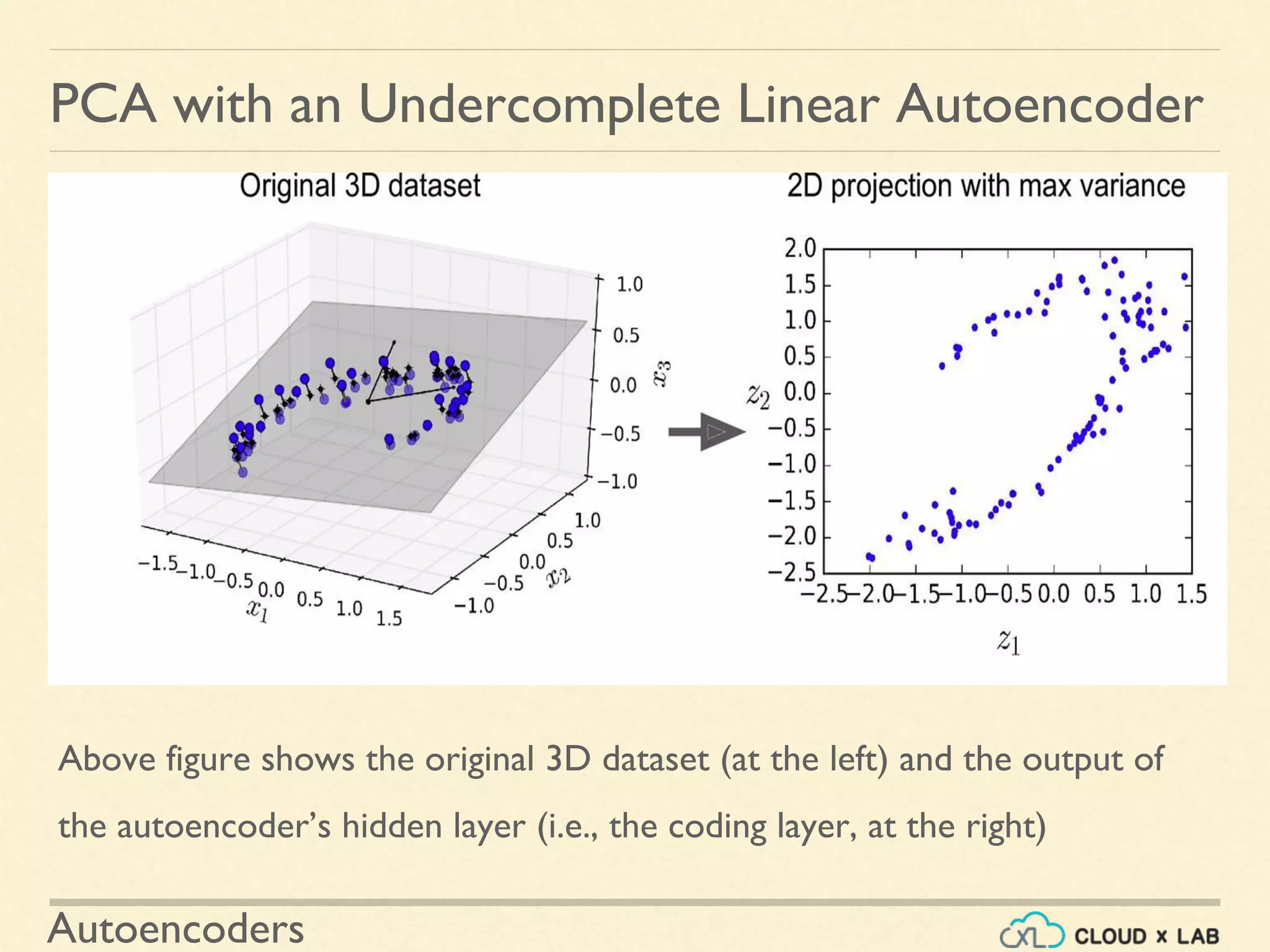
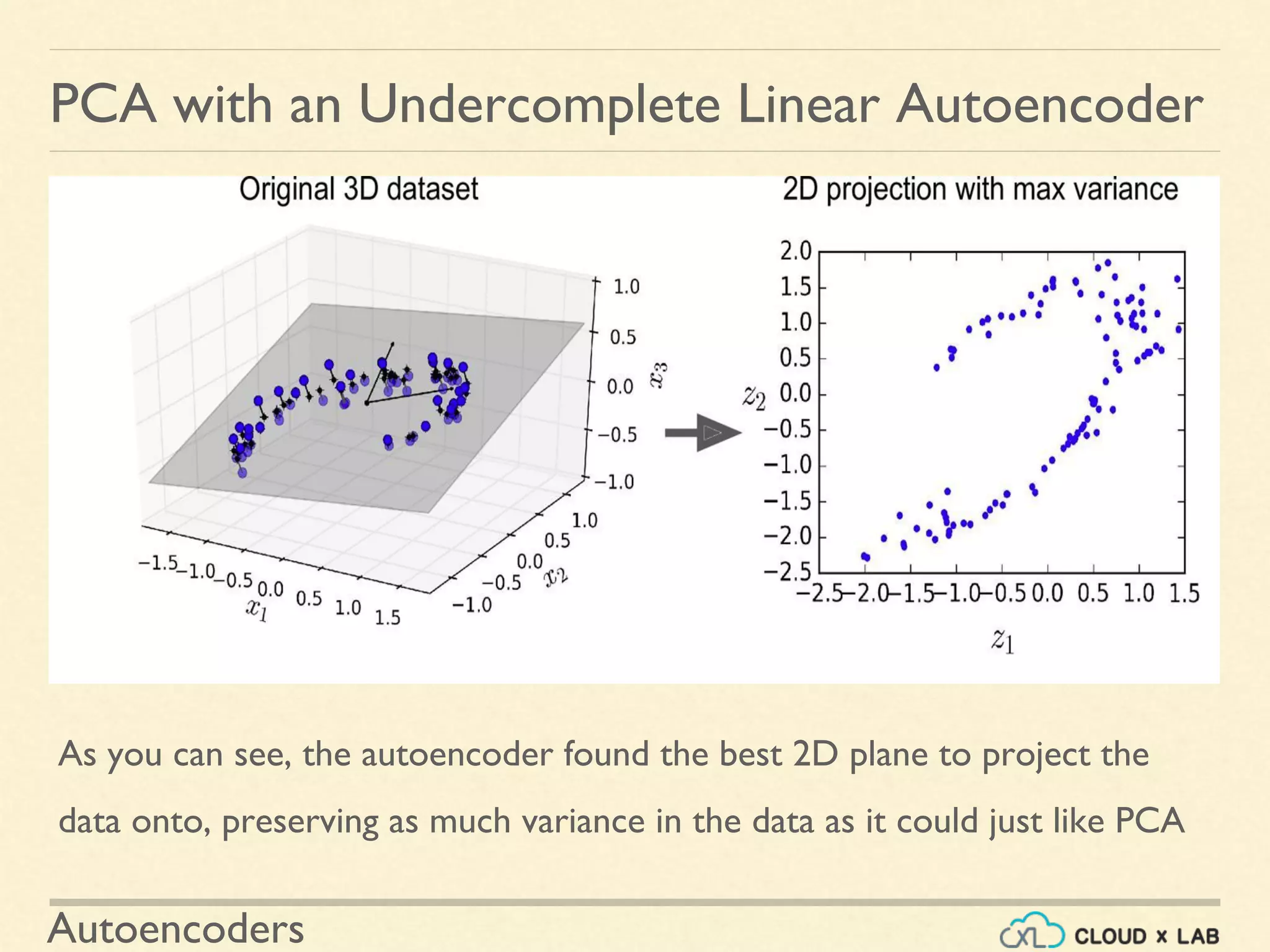
PCA with an Undercomplete Linear Autoencoder
Run it on Notebook](https://image.slidesharecdn.com/d7-180531085553/75/Autoencoders-26-2048.jpg)

![Autoencoders
Now let’s load the dataset, train the model on the training set, and use it to
encode the test set i.e., project it to 2D
>>> X_train, X_test = [...] # load the dataset
>>> n_iterations = 1000
>>> codings = hidden # the output of the hidden layer provides the
codings
>>> with tf.Session() as sess:
init.run()
for iteration in range(n_iterations):
training_op.run(feed_dict={X: X_train}) # no labels
codings_val = codings.eval(feed_dict={X: X_test})
PCA with an Undercomplete Linear Autoencoder
Run it on Notebook](https://image.slidesharecdn.com/d7-180531085553/75/Autoencoders-28-2048.jpg)

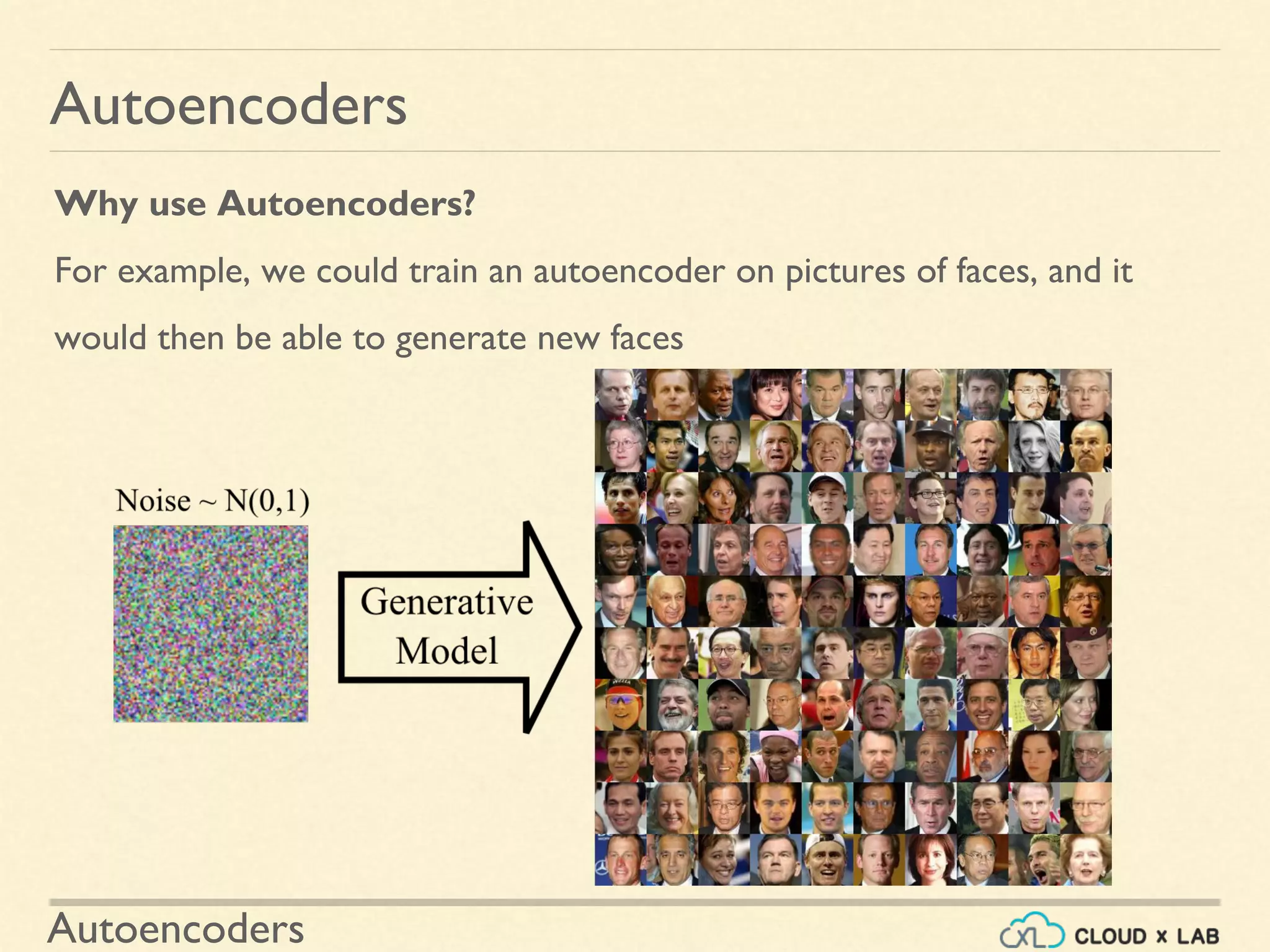
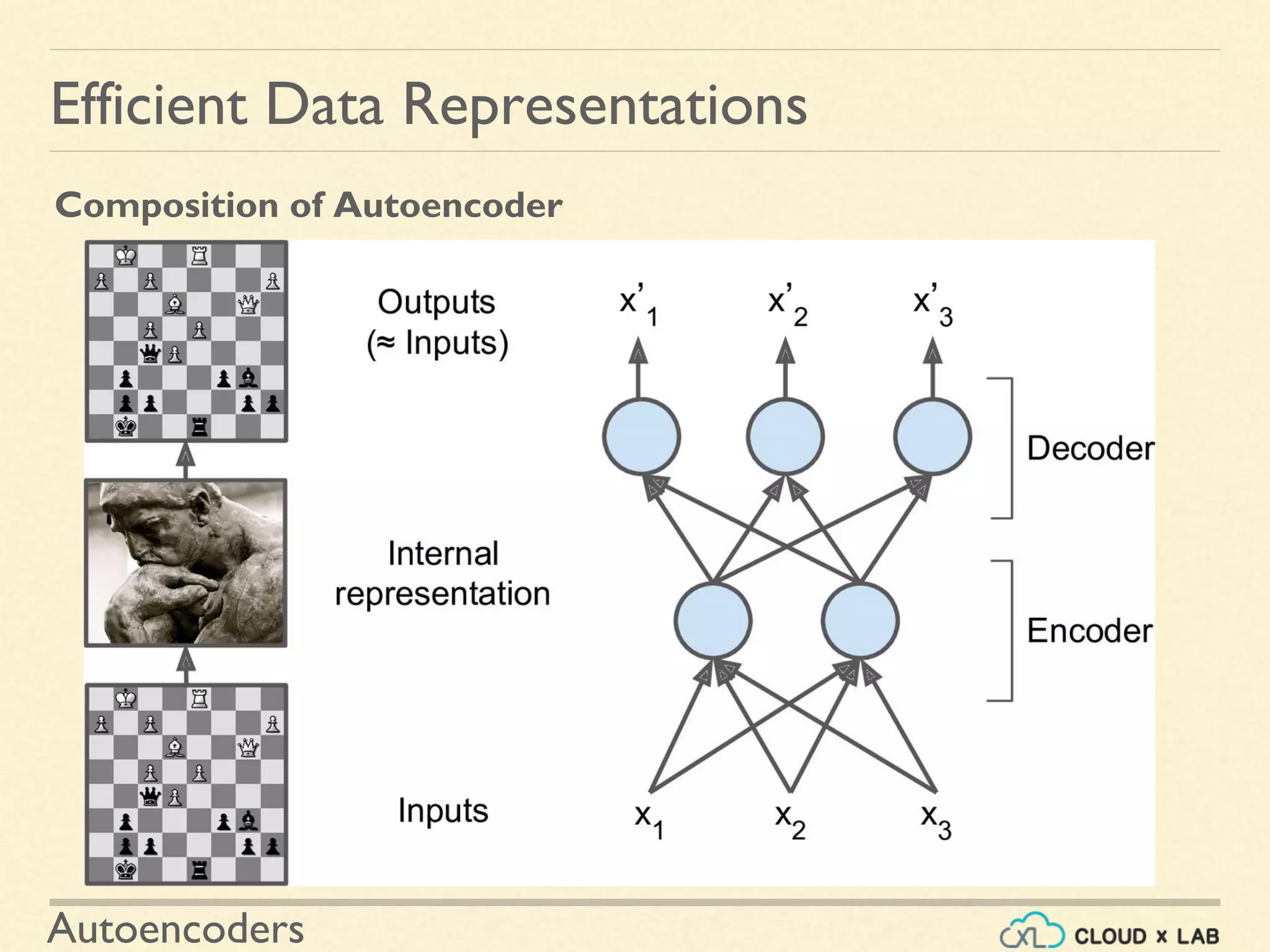
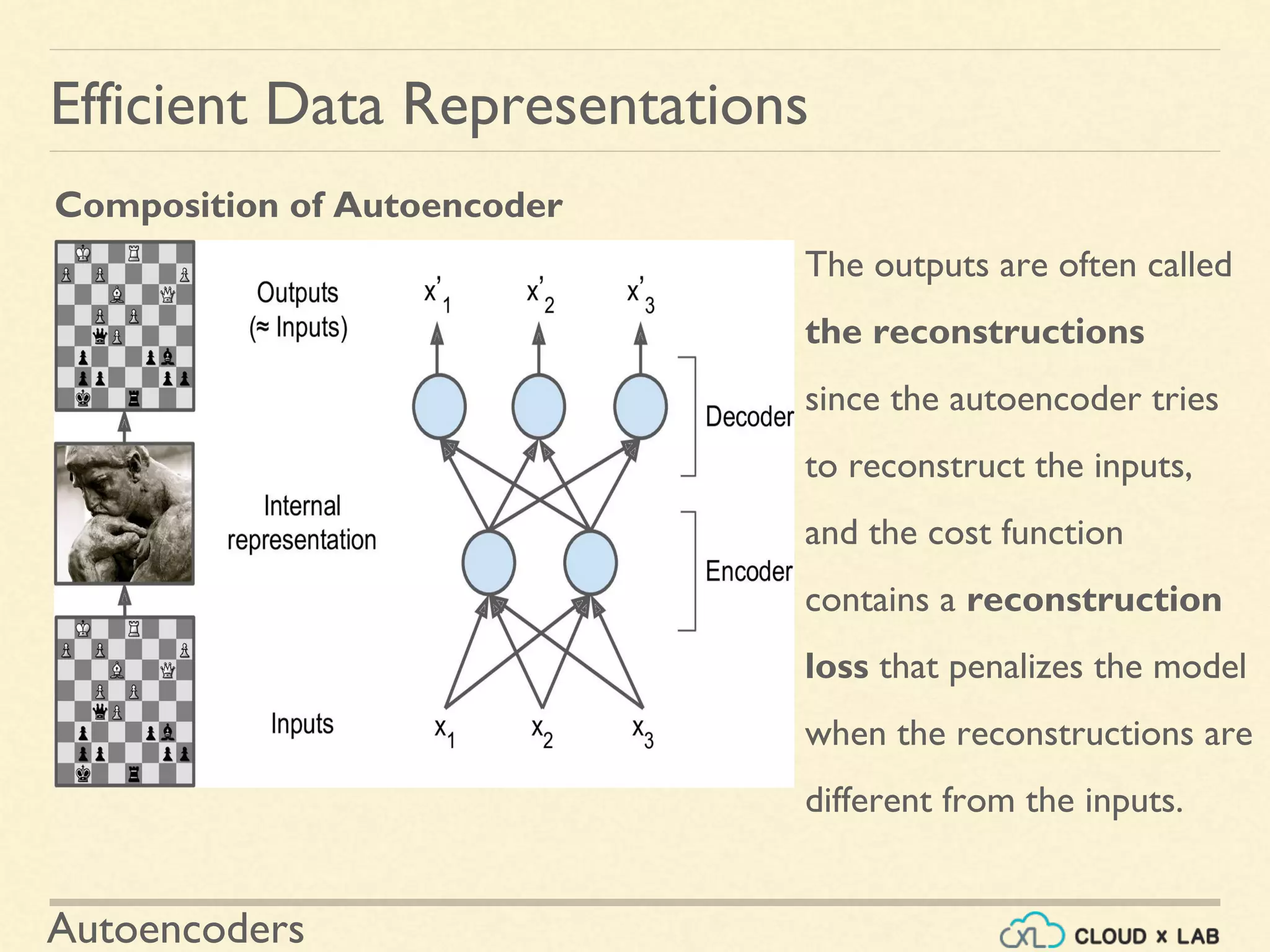
An autoencoder is an artificial neural network that is trained to copy its input to its output. It consists of an encoder that compresses the input into a lower-dimensional latent-space encoding, and a decoder that reconstructs the output from this encoding. Autoencoders are useful for dimensionality reduction, feature learning, and generative modeling. When constrained by limiting the latent space or adding noise, autoencoders are forced to learn efficient representations of the input data. For example, a linear autoencoder trained with mean squared error performs principal component analysis.
Overview of autoencoders as neural networks for learning data representations. Highlights their use in dimensionality reduction, feature detection, and generative modeling.
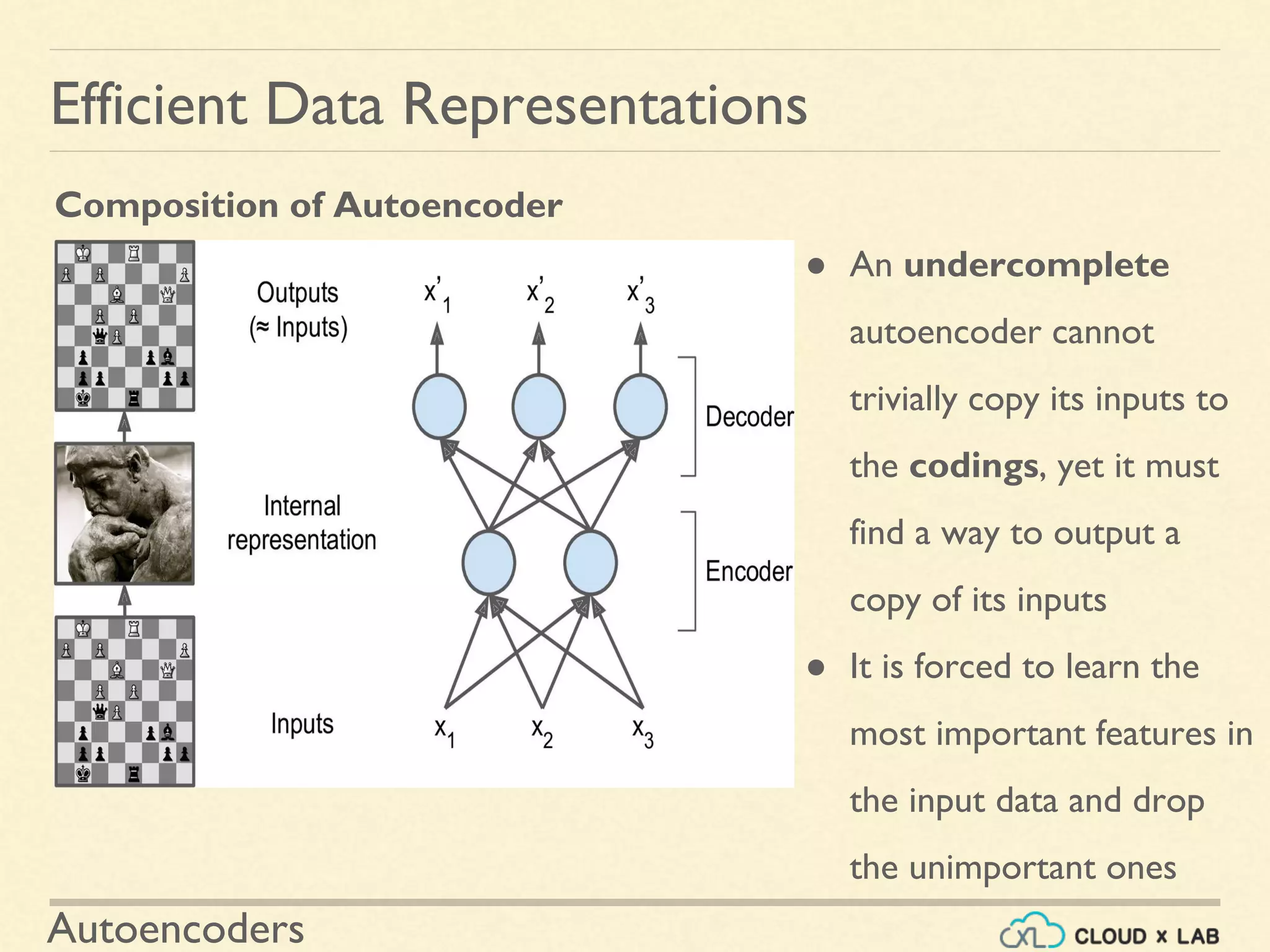
Describes how autoencoders copy inputs to outputs and the importance of adding constraints to learn efficient representations from data.
Overview of the topics to be explored, including constraints, TensorFlow implementation, and applications like dimensionality reduction and generative modeling.
Explains the concept of memorization in sequences and how recognizing patterns, similar to autoencoders, aids in data representation.
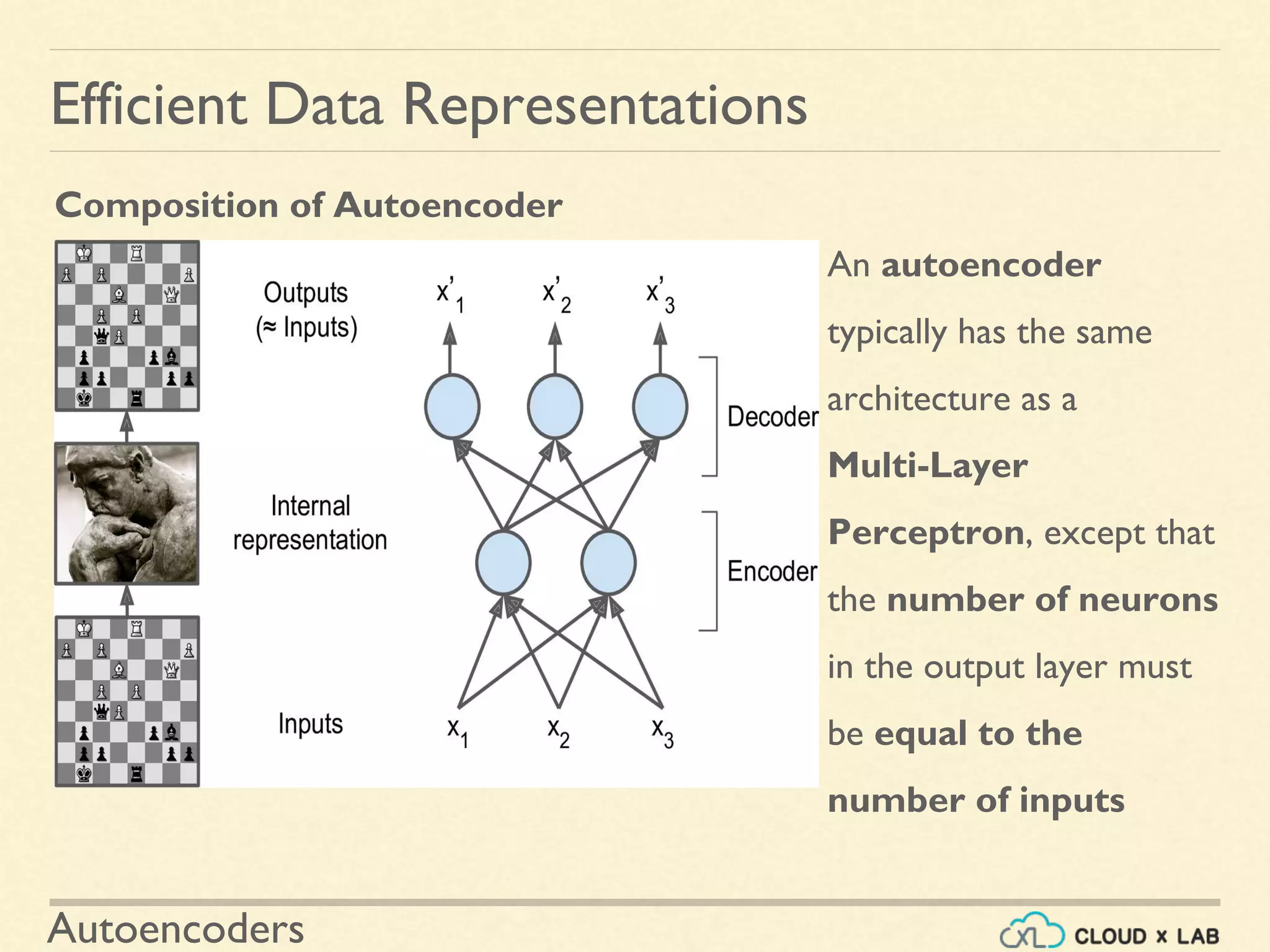
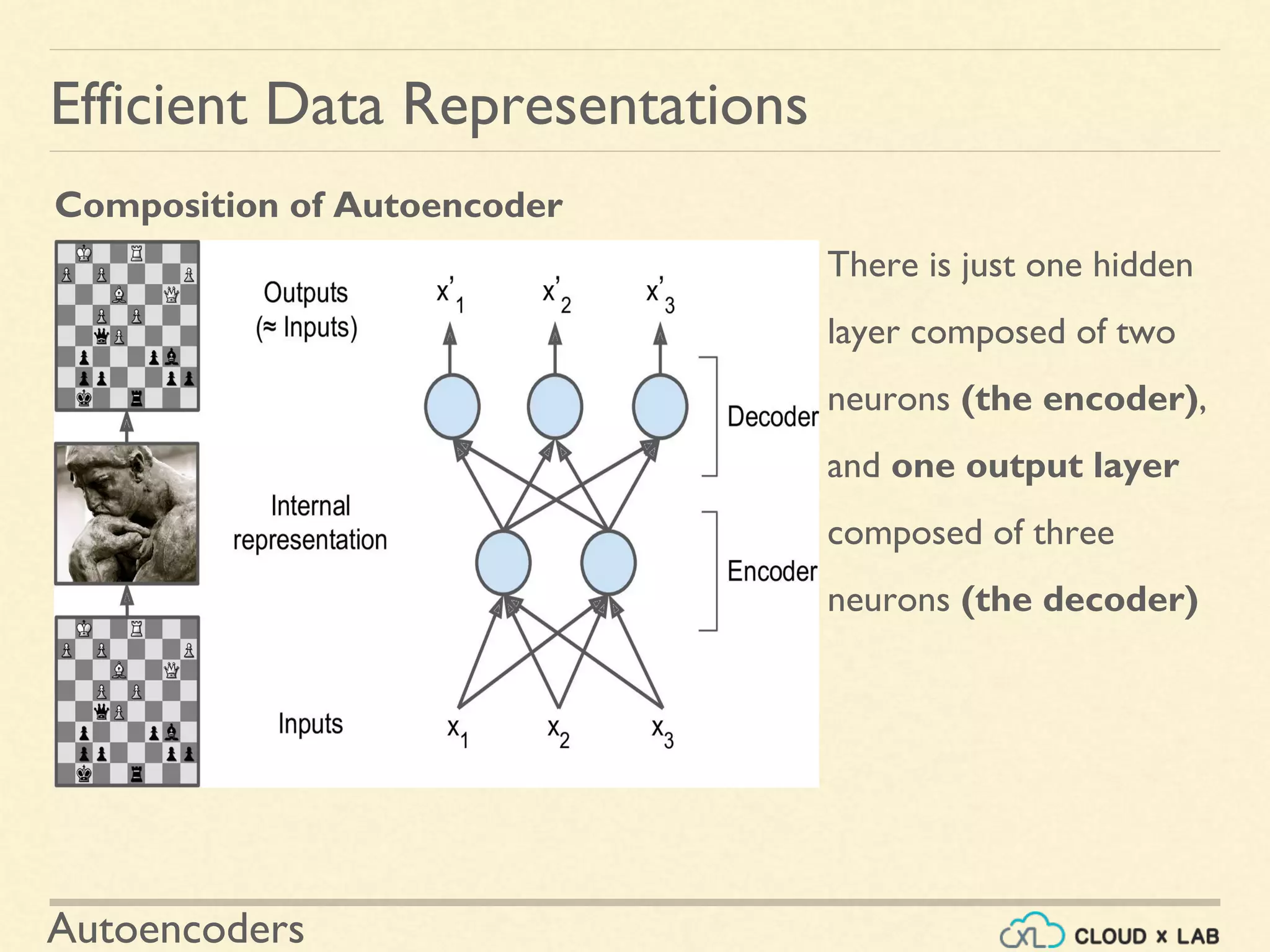
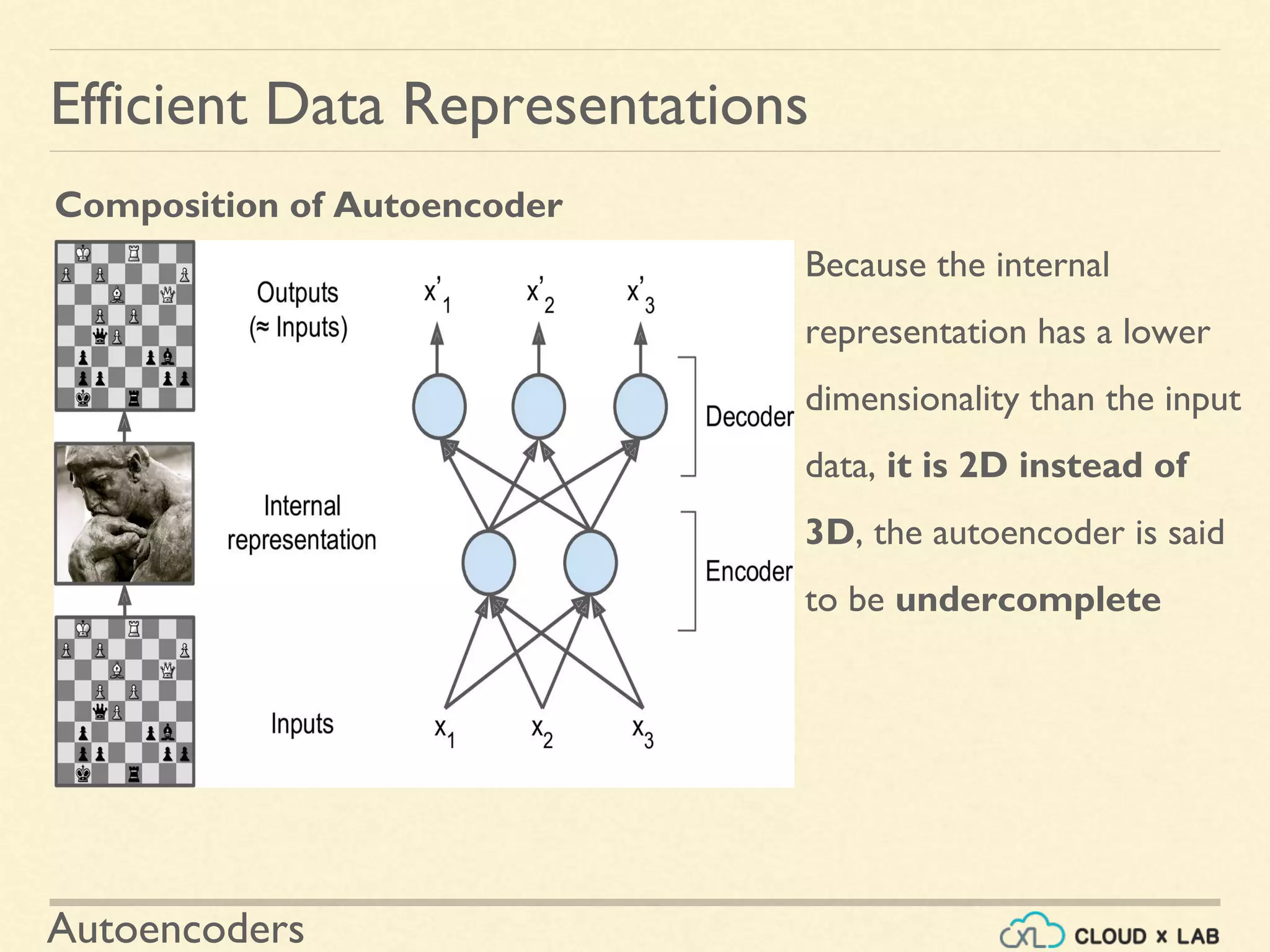
Details the structure of autoencoders consisting of an encoder and a decoder, emphasizing the importance of dimensionality and learning features.
Introduction to implementing a simple undercomplete autoencoder for PCA, outlining the code and demonstrating how it projects data while preserving variance.
Invitation for questions and further discussion on the topic, providing contact information for inquiries.




































































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)









