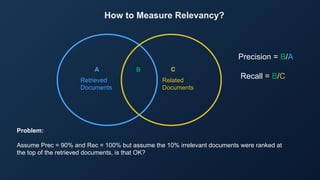
Download as PDF, PPTX













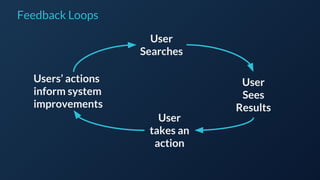











![Term Documents
a doc1 [2x]
brown doc3 [1x]
, doc5 [1x]
cat doc4 [1x]
cow doc2 [1x]
, doc5 [1x]
… ...
once doc1 [1x]
, doc5 [1x]
over doc2 [1x]
, doc3 [1x]
the doc2 [2x]
, doc3 [2x]
,
doc4[2x]
, doc5 [1x]
… …
Document Content Field
doc1 once upon a time, in a land far, far
away
doc2 the cow jumped over the moon.
doc3 the quick brown fox jumped over
the lazy dog.
doc4 the cat in the hat
doc5 The brown cow said “moo” once.
… …
What you SEND to Lucene/Solr:
How the content is INDEXED into
Lucene/Solr (conceptually):
The inverted index](https://image.slidesharecdn.com/reflectedintelligence-evolvingself-learningdatasystems-160714124237/85/Reflected-intelligence-evolving-self-learning-data-systems-31-320.jpg)








![{ ...
"response":{"numFound":22,"start":0,"docs":[
{"jobtitle":" Clinical Educator
(New England/ Boston)",
"city":"Boston",
"state":"MA",
"salary":41503},
…]}}
*Example documents available @ http://github.com/treygrainger/solr-in-action/
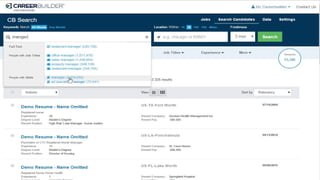
Search Results for Jane
{"jobtitle":"Nurse Educator",
"city":"Braintree",
"state":"MA",
"salary":56183},
{"jobtitle":"Nurse Educator",
"city":"Brighton",
"state":"MA",
"salary":71359}](https://image.slidesharecdn.com/reflectedintelligence-evolvingself-learningdatasystems-160714124237/85/Reflected-intelligence-evolving-self-learning-data-systems-41-320.jpg)



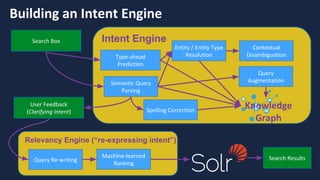


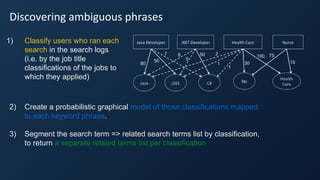
![Bay Area Search
Building a Taxonomy of Entities
Many ways to generate this:
• Topic Modelling
• Clustering of documents
• Statistical Analysis of interesting phrases
• Buy a dictionary (often doesn’t work for
domain-specific search problems)
• …
CareerBuilder’s strategy:
Generate a model of domain-specific phrases by
mining query logs for commonly searched phrases within the domain [1]
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific Jargon," in IEEE Big Data
2014.](https://image.slidesharecdn.com/reflectedintelligence-evolvingself-learningdatasystems-160714124237/85/Reflected-intelligence-evolving-self-learning-data-systems-53-320.jpg)

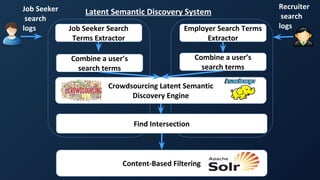









![Bay Area Search
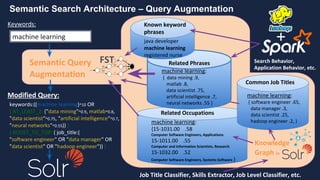
Semantic Search Architecture – Query Parsing
Identification of phrases in queries using two steps:
1) Check a dictionary of known terms that is continuously
built, cleaned, and refined based upon common inputs from
interactions with real users of the system [1]
2) Also invoke a statistical phrase identifier to dynamically
identify unknown phrases using statistics from a corpus of data
(language model)
Shown on next slides:
Pass extracted entities to a Query Augmentation phase to
rewrite the query with enhanced semantic understanding
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of
Domain-specific Jargon," in IEEE Big Data 2014.](https://image.slidesharecdn.com/reflectedintelligence-evolvingself-learningdatasystems-160714124237/85/Reflected-intelligence-evolving-self-learning-data-systems-69-320.jpg)

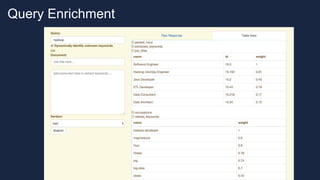


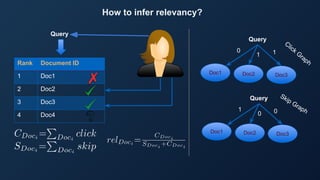

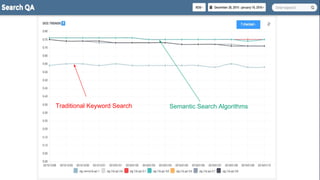




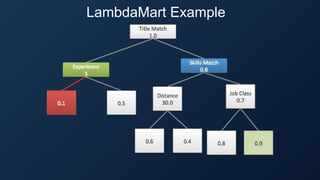
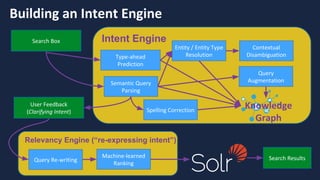




The document discusses the concept of reflected intelligence and its role in data systems, particularly focusing on technologies like Hadoop and Spark, and application areas such as recommendation systems and semantic search. It emphasizes the importance of leveraging past interactions and user context to improve search relevance and user experience. Additionally, it outlines the challenges of big data processing and the mechanisms used to enhance information retrieval and ranking in enterprise search applications.






















































































