Downloaded 192 times



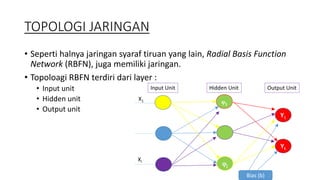


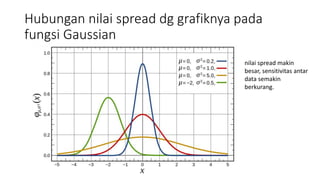








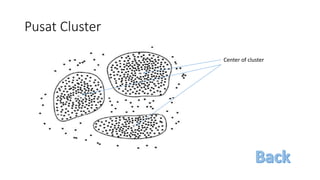

Dokumen ini membahas tentang Radial Basis Function Network (RBFN) sebagai sistem pakar dalam topologi jaringan, yang terdiri dari unit input, hidden, dan output. RBFN digunakan untuk pengklasifikasian pola dan pemodelan deret waktu dengan fungsi aktivasi berbasis radial, seperti fungsi Gaussian, dan memiliki algoritma pelatihan yang mencakup tahap clustering data dan pembaharuan bobot. Selain itu, dokumen tersebut juga menjelaskan variasi fungsi aktivasi dan metode untuk menentukan pusat cluster dalam tahap clustering.























































































