Q-learning 是一种源自心理学的增强式学习算法,旨在通过与环境的互动学习最优策略。它利用 Q 值来积累每次行动后的经验,并通过奖励反馈强化学习过程。文档还以例子说明 Q-learning 的实际应用,如在游戏 Flappy Bird 中的决策制定。





![7
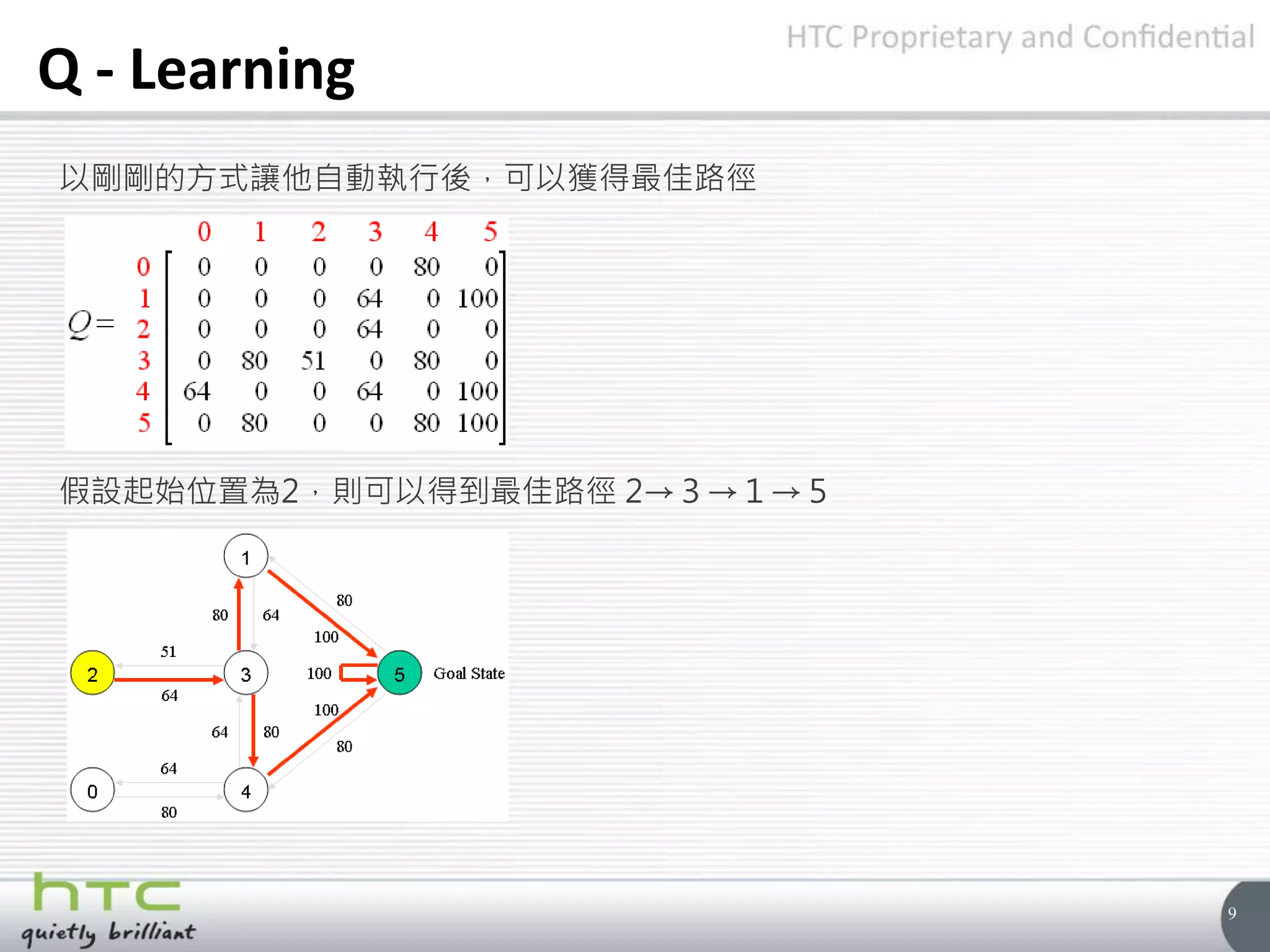
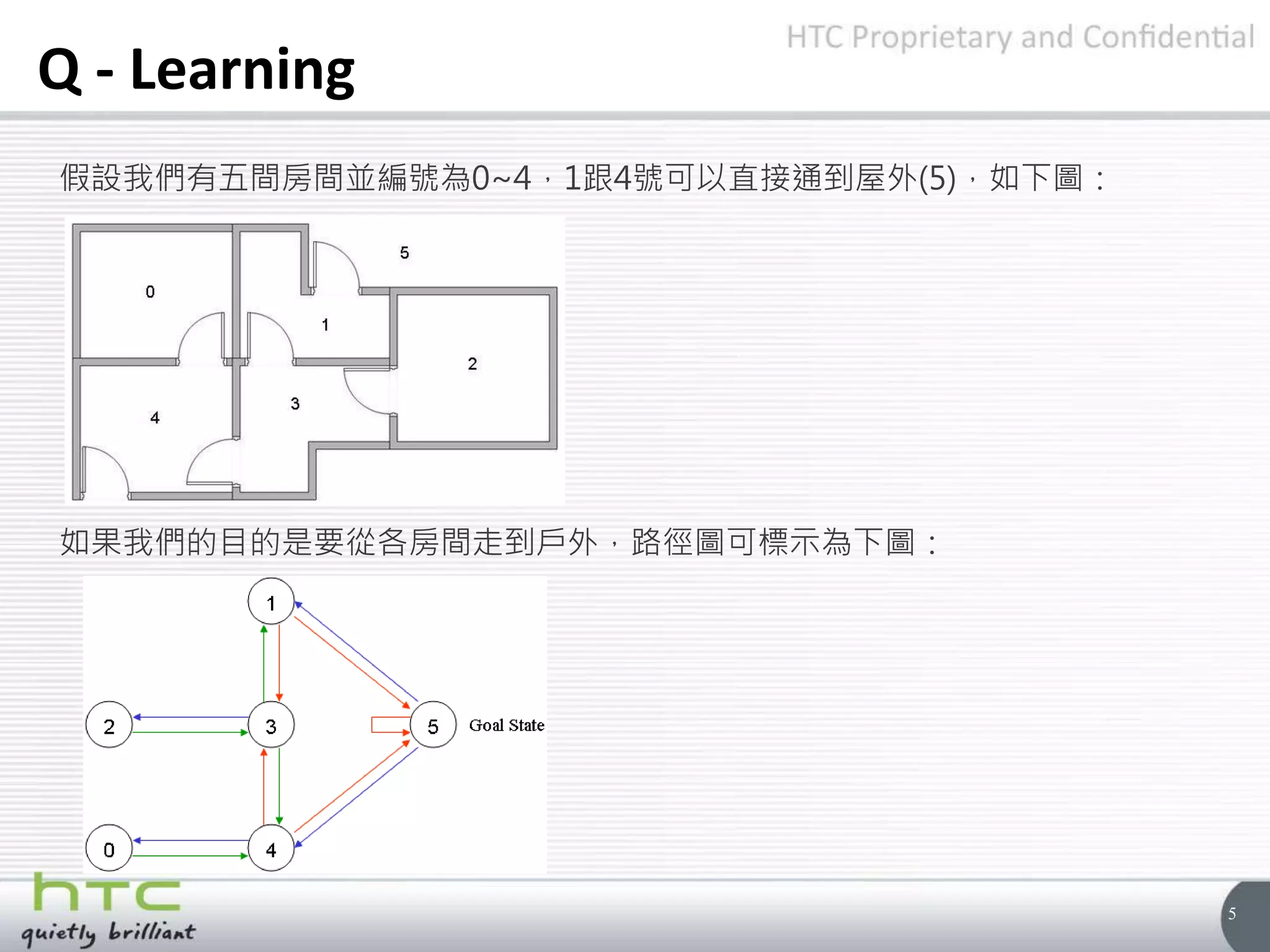
Q - Learning
假設我們的學習率先設定為0.8,起始房間為1,初始陣列Q為下
起始為1,有3跟5可以選擇,假設我們選擇5
在5的時候有三種路徑可以選,1、4、5,此時套用公式將我們的陣列Q更新
• Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
• Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100](https://image.slidesharecdn.com/qlearning-160518064855/75/Qlearning-7-2048.jpg)
![8
Q - Learning
接著以3為我們的起始狀態
起始為3,有145可以選擇,假設我們選擇1
在1的時候有兩種路徑可以選,3、5,此時套用公式將我們的陣列Q更新
• Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
• Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 3), Q(1, 5)] = 0 + 0.8 * Max(0, 100) = 80](https://image.slidesharecdn.com/qlearning-160518064855/75/Qlearning-8-2048.jpg)