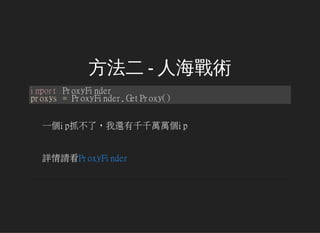
本文介绍了网页爬虫的一些实用技巧,涵盖了简单抓取、使用Selenium处理复杂问题、多线程与多进程抓取等方法。作者也分享了通过代理和等待策略来规避限制的经验。内容较为基础,主要为提供相关心得和解决方案。















![看個例子
classWorker(threading.Thread):
def__init__(self,queue):
threading.Thread.__init__(self)
self.queue=queue
defrun(self):
whileTrue:
try:
url=self.queue.get(timeout=1)
exceptQueue.Empty:
return
GetData(url)
self.queue.task_done()
queue=Queue.Queue()
threads=[]
foriinrange(thread_num):
worker=Worker(queue)
worker.setDaemon(True)
worker.start()
threads.append(worker)](https://image.slidesharecdn.com/reveal-150517074138-lva1-app6892/85/Python-16-320.jpg)