about me
2
- KAISTSOC 4학년
- 2019.1.2 ~ 2019.8.14
AITRICS
software engineering intern
(backend: Django Rest Framework,
frontend: Vue.js)
3.
1. 회사에서 개발중인 Django를 이용한 서비스
- 성능의 문제점을 중심으로
2. Django ORM이란?
- ORM의 특징과 실제 사용 사례를 중심으로
3. Query profiling하는 법
4. API로 들어온 대용량의 데이터를 빠르게 DB로
5. DB의 데이터를 빠르게 ML model로
3
현재 상황에서의
문제점 소개
문제점 개선을 위한
background
실제로 문제점을
개선한 사례
4.
1. 회사에서 개발중인 Django를 이용한 서비스
- 성능의 문제점을 중심으로
2. Django ORM이란?
- ORM의 특징과 실제 사용 사례를 중심으로
3. Query profiling하는 법
4. API로 들어온 대용량의 데이터를 빠르게 DB로
5. DB의 데이터를 빠르게 ML model로
4
현재 상황에서의
문제점 소개
문제점 개선을 위한
background
실제로 문제점을
개선한 사례
5.
5
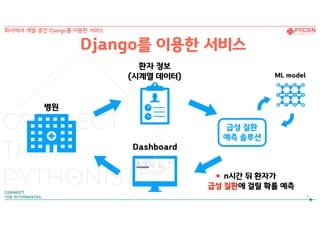
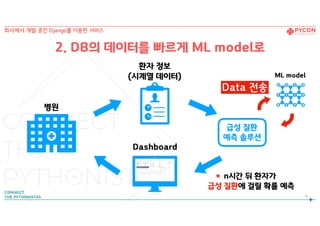
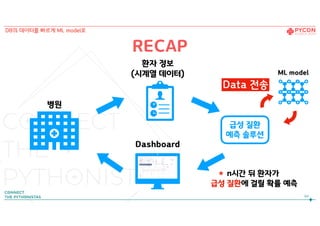
환자 정보
(시계열 데이터)
n시간뒤 환자가
급성 질환에 걸릴 확률 예측
Dashboard
*
급성 질환
예측 솔루션
병원
ML model
Django를 이용한 서비스
회사에서 개발 중인 Django를 이용한 서비스
6.
환자 정보
(시계열 데이터)
n시간뒤 환자가
급성 질환에 걸릴 확률 예측
Dashboard
*
6
급성 질환
예측 솔루션
병원
ML model
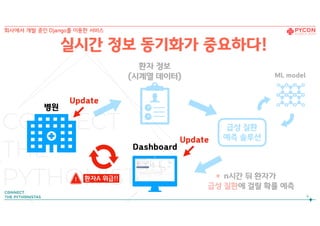
실시간 정보 동기화가 중요하다!
Update
Update
회사에서 개발 중인 Django를 이용한 서비스
! 환자A 위급!!
7.
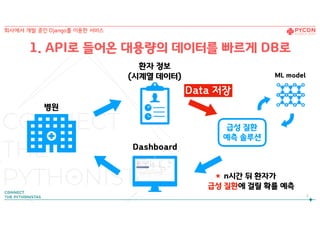
Data 저장
7
환자 정보
(시계열데이터)
Dashboard
*
급성 질환
예측 솔루션
병원
ML model
n시간 뒤 환자가
급성 질환에 걸릴 확률 예측
회사에서 개발 중인 Django를 이용한 서비스
1. API로 들어온 대용량의 데이터를 빠르게 DB로
8.
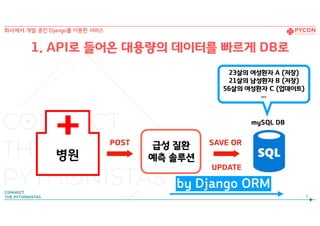
병원
POST SAVE OR
UPDATE
예)환자 정보 저장
mySQL DB
급성 질환
예측 솔루션
[23살의 여성환자 A
21살의 남성환자 B
56살의 여성환자 C
… ]
8
회사에서 개발 중인 Django를 이용한 서비스
1. API로 들어온 대용량의 데이터를 빠르게 DB로
9.
병원
POST SAVE OR
UPDATE
mySQLDB
급성 질환
예측 솔루션
23살의 여성환자 A (저장)
21살의 남성환자 B (저장)
56살의 여성환자 C (업데이트)
…
9
회사에서 개발 중인 Django를 이용한 서비스
1. API로 들어온 대용량의 데이터를 빠르게 DB로
by Django ORM
10.
병원
POST SAVE OR
UPDATE
mySQLDB
급성 질환
예측 솔루션
10
회사에서 개발 중인 Django를 이용한 서비스
1. API로 들어온 대용량의 데이터를 빠르게 DB로
by Django ORM
데이터 업데이트가 너무 느리다!!
매 분마다 수백 명의 환자 정보 ->
!
-최적화 필요-
11.
Data 전송
11
환자 정보
(시계열데이터)
n시간 뒤 환자가
급성 질환에 걸릴 확률 예측
Dashboard
*
급성 질환
예측 솔루션
병원
ML model
회사에서 개발 중인 Django를 이용한 서비스
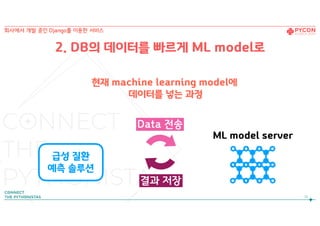
2. DB의 데이터를 빠르게 ML model로
12.
현재 machine learningmodel에
데이터를 넣는 과정
12
Data 전송
결과 저장
회사에서 개발 중인 Django를 이용한 서비스
급성 질환
예측 솔루션
ML model server
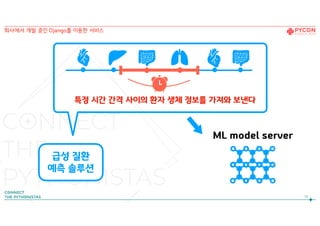
2. DB의 데이터를 빠르게 ML model로
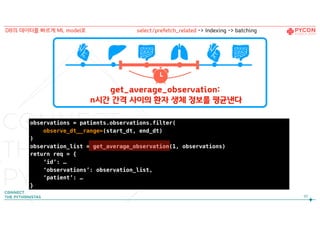
13.
특정 시간 간격사이의 환자 생체 정보를 가져와 보낸다
13
급성 질환
예측 솔루션
ML model server
회사에서 개발 중인 Django를 이용한 서비스
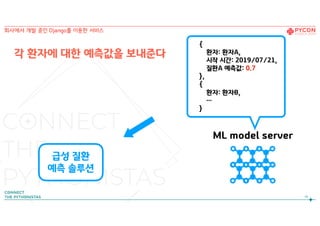
14.
각 환자에 대한예측값을 보내준다
14
회사에서 개발 중인 Django를 이용한 서비스
급성 질환
예측 솔루션
ML model server
{
환자: 환자A,
시작 시간: 2019/07/21,
질환A 예측값: 0.7
},
{
환자: 환자B,
…
}
15.
이걸 주기적으로 매분마다 해야한다!
시간별로 검색한 환자 정보를 빠르게 가져오고,
받은 예측값을 빠르게 저장하는 것이 필수적
예측값시간별 환자정보
15
회사에서 개발 중인 Django를 이용한 서비스
급성 질환
예측 솔루션
ML model server
SCORE
DB
16.
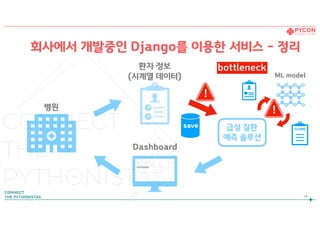
회사에서 개발중인 Django를이용한 서비스 - 정리
16
환자 정보
(시계열 데이터)
Dashboard
급성 질환
예측 솔루션
병원
ML model
SCORE
save
!
bottleneck
!
17.
1. 회사에서 개발중인 Django를 이용한 서비스
- 성능의 문제점을 중심으로
2. Django ORM이란?
- ORM의 특징과 실제 사용 사례를 중심으로
3. Query profiling하는 법
4. API로 들어온 대용량의 데이터를 빠르게 DB로
5. DB의 데이터를 빠르게 ML model로
17
현재 상황에서의
문제점 소개
문제점 개선을 위한
background
실제로 문제점을
개선한 사례
18.
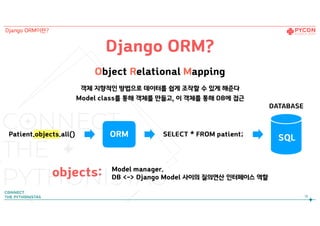
Django ORM?
Object RelationalMapping
객체 지향적인 방법으로 데이터를 쉽게 조작할 수 있게 해준다
Model class를 통해 객체를 만들고, 이 객체를 통해 DB에 접근
Patient.objects.all() SELECT * FROM patient;ORM
DATABASE
SQL
Model manager.
DB <-> Django Model 사이의 질의연산 인터페이스 역할objects:
18
Django ORM이란?
19.
SELECT * FROM`api_patient`
WHERE `api_patient`.`uid` = 10110;
SELECT 수행
object가 딱 하나여야함!
여러개 이거나 없으면 Exception
.get()
19
Django ORM이란?
Patient.objects.get(uid=‘10110’)
| 10110 | 10111 | 10112 | …api_patient:
SQL
20.
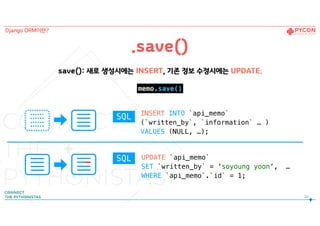
UPDATE `api_memo`
SET `written_by`= ‘soyoung yoon’, …
WHERE `api_memo`.`id` = 1;
memo.save()
save(): 새로 생성시에는 INSERT, 기존 정보 수정시에는 UPDATE.
.save()
20
Django ORM이란?
INSERT INTO `api_memo`
(`written_by`, `information` … )
VALUES (NULL, …);
SQL
SQL
21.
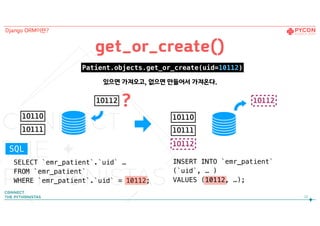
21
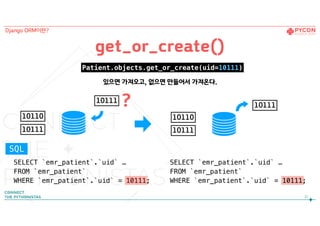
get_or_create()
SELECT `emr_patient`.`uid` …
FROM`emr_patient`
WHERE `emr_patient`.`uid` = 10111;
10110
10111
10110
10111
10111
Django ORM이란?
Patient.objects.get_or_create(uid=10111)
SELECT `emr_patient`.`uid` …
FROM `emr_patient`
WHERE `emr_patient`.`uid` = 10111;
SQL
있으면 가져오고, 없으면 만들어서 가져온다.
?10111
patients = Patient.objects.filter(gender=‘F’)
patents= patients.filter(age__gte=23)
print(patients)
Lazy_loading
django 2.2 공식문서
Django ORM?
query sets are lazy: https://docs.djangoproject.com/en/2.2/topics/db/queries/#querysets-are-lazy
When query sets are evaluated: https://docs.djangoproject.com/en/2.2/ref/models/querysets/#when-querysets-are-evaluated
24
Evaluation은 여기서만 수행됨
: Queryset을 쓴다고 바로 evaluated되는 것이 아님
Django ORM이란?
1. lazy QuerySet *Slicing, Pickling/Caching, repr(), len(), list(), bool() …
2. lazy fetching
25.
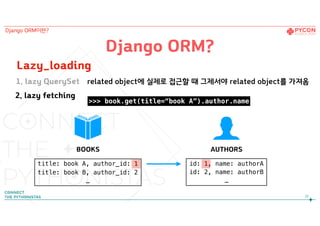
25
Django ORM이란?
Django ORM?
Lazy_loading
relatedobject에 실제로 접근할 때 그제서야 related object를 가져옴
BOOKS AUTHORS
title: book A, author_id: 1
title: book B, author_id: 2
…
id: 1, name: authorA
id: 2, name: authorB
…
>>> book.get(title=“book A”).author.name
1. lazy QuerySet
2. lazy fetching
26.
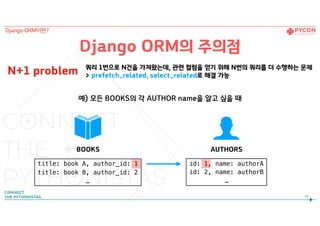
Django ORM의 주의점
N+1problem 쿼리 1번으로 N건을 가져왔는데, 관련 컬럼을 얻기 위해 N번의 쿼리를 더 수행하는 문제
> prefetch_related, select_related로 해결 가능
BOOKS AUTHORS
예) 모든 BOOKS의 각 AUTHOR name을 알고 싶을 때
26
title: book A, author_id: 1
title: book B, author_id: 2
…
id: 1, name: authorA
id: 2, name: authorB
…
Django ORM이란?
27.
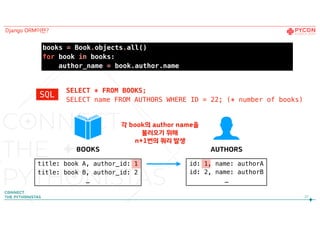
27
books = Book.objects.all()
forbook in books:
author_name = book.author.name
각 book의 author name을
불러오기 위해
n+1번의 쿼리 발생
BOOKS AUTHORS
title: book A, author_id: 1
title: book B, author_id: 2
…
id: 1, name: authorA
id: 2, name: authorB
…
Django ORM이란?
SELECT * FROM BOOKS;
SELECT name FROM AUTHORS WHERE ID = 22; (* number of books)
SQL
1. 회사에서 개발중인 Django를 이용한 서비스
- 성능의 문제점을 중심으로
2. Django ORM이란?
- ORM의 특징과 실제 사용 사례를 중심으로
3. Query profiling하는 법
4. API로 들어온 대용량의 데이터를 빠르게 DB로
5. DB의 데이터를 빠르게 ML model로
29
현재 상황에서의
문제점 소개
문제점 개선을 위한
background
실제로 문제점을
개선한 사례
30.
ORM으로 실행한 실제SQL을 보고 싶다!
https://wayhome25.github.io/django/2017/04/01/django-ep9-crud/
https://django-orm-cookbook-ko.readthedocs.io/en/latest/query.html 30
리턴값이 queryset인 경우:
Query profiling하는 법
>>> my_query = Patient.objects.filter(id=1)
>>> str(my_query.query)
SELECT `emr_patient`.`uid`, `emr_patient`.`name` ..
FROM `emr_patient` WHERE `emr_patient`.`id` = 1
str(<MY_QUERYSET>.query)
31.
ORM으로 실행한 실제SQL을 보고 싶다!
>>> from django.db import connection
>>> Patient.objects.count()
>>> connection.queries[-1]
{‘sql’: ‘SELECT COUNT(*) AS `__count` FROM `emr_patient`’,
‘time’: ‘0.001’}
connection 모듈을 통해
queryset으로 만들어진 실제 sql문을 shell에서 확인할 수 있다.
31
Query profiling하는 법
connection.queries[-1]
장점
단점
Live 환경에서 사용가능
여러 개를 비교하며 한 번에 볼 수 있음.
Profile Graph, Traceback 지원
느리다 (쿼리가 많아질수록 느려짐)
실제 실행 시간도 같이 느려진다
ORM을 사용하지 않으면 SQL 쿼리를 보여주지 않는다.
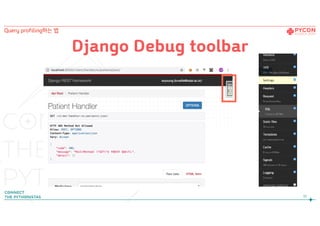
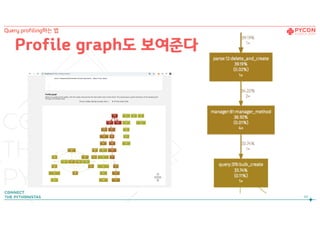
Silk 정리
43
Query profiling하는 법
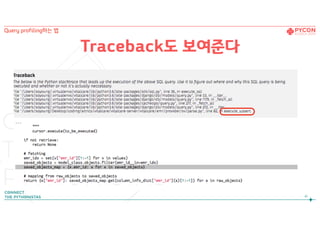
44.
Query profiling하는 법- 정리
44
Query profiling하는 법
str(my_query.query)
connection.queries[-1]
Profiling
-Django Debug Toolbar
-Silk
See query string
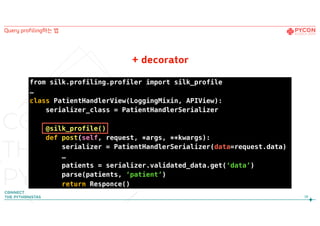
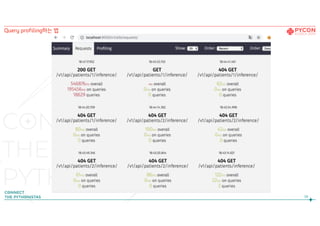
45.
1. 회사에서 개발중인 Django를 이용한 서비스
- 성능의 문제점을 중심으로
2. Django ORM이란?
- ORM의 특징과 실제 사용 사례를 중심으로
3. Query profiling하는 법
4. API로 들어온 대용량의 데이터를 빠르게 DB로
5. DB의 데이터를 빠르게 ML model로
45
현재 상황에서의
문제점 소개
문제점 개선을 위한
background
실제로 문제점을
개선한 사례
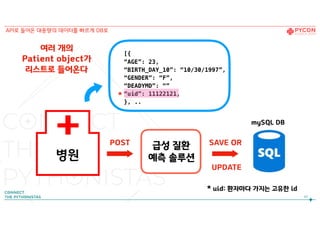
46.
병원
POST SAVE OR
UPDATE
mySQLDB
급성 질환
예측 솔루션
46
4. API로 들어온 대용량의 데이터를 빠르게 DB로
by Django ORM
데이터 업데이트가 너무 느리다!!
매 분마다 수백 명의 환자 정보 ->
!
-최적화 필요-
API로 들어온 대용량의 데이터를 빠르게 DB로
47.
병원
POST SAVE OR
UPDATE
mySQLDB
[{
“AGE”: 23,
“BIRTH_DAY_10”: “10/30/1997”,
“GENDER”: “F”,
“DEADYMD”: “”
“uid”: 11122121,
}, ..
여러 개의
Patient object가
리스트로 들어온다
급성 질환
예측 솔루션
47
* uid: 환자마다 가지는 고유한 id
*
API로 들어온 대용량의 데이터를 빠르게 DB로
48.
병원
POST SAVE OR
UPDATE
mySQLDB
급성 질환
예측 솔루션
48
API로 들어온 대용량의 데이터를 빠르게 DB로
def parse_patient(obj):
patient, _ = Patient.objects.get_or_create(uid=obj[‘uid’])
patient.gender = obj[‘GENDER’]
…
patient.save()
49.
문제: Patient 하나씩저장해서 느리다!
한 번에 저장할 수 있는 로직이 필요
def parse_patient(obj):
patient, _ = Patient.objects.get_or_create(uid=obj[‘uid’])
patient.gender = obj[‘GENDER’]
…
patient.save()
49
API로 들어온 대용량의 데이터를 빠르게 DB로
def parse_patients(objs):
patients =[]
for obj in objs:
…
patients.append(patient)
Patient.objects.bulk_create(patients)
def parse_patient(obj):
patient, _ = Patient.objects.get_or_create(uid=obj[‘uid’])
patient.gender = obj[‘GENDER’]
…
patient.save()
AFTER
BEFORE
51
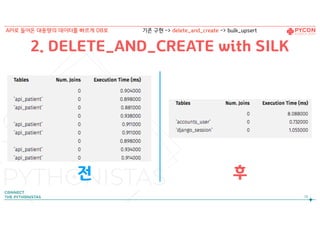
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
52.
bulk_create를 통해
이미존재하는 row를 다시 생성할 수 없다.
실패(동작하지 않는다!)
52
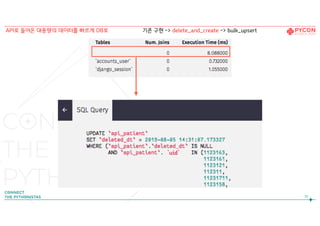
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
get_or_create(…) -> bulk_create() x
53.
기존 값이 있으면다 지워버리고
한번에 만들자!
(Get_or_create를
안써도 되도록)
-> 방법2: Delete_and_create
53
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
54.
구현 방법
1. ORM
-DBMS 제한 없이 사용 가능. 보안 이슈 적음. 어느 정도 성능 최적화 가능.
- DB의 schema를 그대로 class로 매핑
2. Raw query
- 말 그대로 query를 자율적으로 조절 가능. (customizeable)
- 성능을 극대로 최적화할 수 있음.
54
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
Patient.objects.filter(uid__in=[1, 4, 5, 24..]).delete()
Patient.objects.raw(
‘DELETE FROM emr_patient where uid IN (1, 4, 5, 24..)’)
55.
def parse_patients(objs):
patients =[]
for obj in objs:
patients.append(Patient(uid=obj[‘uid’],
gender=obj[‘GENDER’],
…))
delete_and_create(patients, Patient.objects)
55
API로 들어온 대용량의 데이터를 빠르게 DB로
def delete_and_create(objects, manager):
uids = [o.uid for o in objects]
manager.filter(uid__in=uids).delete()
manager.bulk_create(objects)
bulk_create -> delete_and_create -> bulk_upsert
56.
잘 될거라고 생각했으나...문제발생
gender uid first_name death_dt birth
F 1002495111 Soyoung
Yoon
NULL 1997-10-30
gender uid first_name death_dt birth
F 1002495111 Soyoung
Yoon
2019-07-17 1997-10-30
56
{
“First_name”: “Soyoung Yoon”,
“Gender”: 23,
“Uid”: “1002495111”,
“DeadYmd”: “”,
“BirthYmd”: “19971030”
}
SENT AT 2019/6/10 SENT AT 2019/7/18
{
“First_name”: “Soyoung Yoon”,
“Gender”: 23,
“Uid”: “1002495111”,
“DeadYmd”: “20190717”,
“BirthYmd”: “19971030”
}
+
+
API로 들어온 대용량의 데이터를 빠르게 DB로
57.
gender uid first_namedeath_dt birth
F 1002495111 Soyoung
Yoon
NULL 1997-10-30
57
{
“First_name”: “Soyoung Yoon”,
“Gender”: 23,
“Uid”: “1002495111”,
“DeadYmd”: “”,
“BirthYmd”: “19971030”
}
SENT AT 2019/6/10 SENT AT 2019/7/18
-
-
-
+
gender uid first_name death_dt birth
NULL 1002495111 NULL 2019-07-17 NULL
- - -+
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
{
“Uid”: “1002495111”,
“DeadYmd”: “20190717”,
}
잘 될거라고 생각했으나...문제 발생
58.
한계
delete_and_create
58
API로 들어온 대용량의데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
gender uid first_name death_dt birth
F 1002495111 Soyoung
Yoon
2019-07-17 1997-10-30원하는 것
AFTER gender uid first_name death_dt birth
NULL 1002495111 NULL 2019-07-17 NULL
1. delete를 하는 경우
foreign key relationship을 포함한
기존 정보가 날라감
2. delete -> create 하는 동안에
어떤 일이 발생할 지 모른다.
59.
개선 방법:
없는 데이터는INSERT하고
있는 데이터는 UPDATE
-> UPSERT(UPDATE + INSERT)
59
한계
delete_and_create
BUT Django ORM으로는
bulk_upsert를 할 수 없다
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
60.
한 object에 대한update_or_create()는 있지만..
필요한 건 BULK update_or_create
60
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
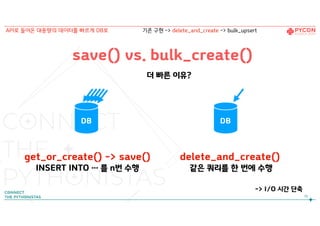
save() vs. bulk_create()
get_or_create()-> save()
INSERT INTO … 를 n번 수행
delete_and_create()
같은 쿼리를 한 번에 수행
DB
더 빠른 이유?
DB
-> I/O 시간 단축
76
API로 들어온 대용량의 데이터를 빠르게 DB로 기존 구현 -> delete_and_create -> bulk_upsert
1. 회사에서 개발중인 Django를 이용한 서비스
- 성능의 문제점을 중심으로
2. Django ORM이란?
- ORM의 특징과 실제 사용 사례를 중심으로
3. Query profiling하는 법
4. API로 들어온 대용량의 데이터를 빠르게 DB로
5. DB의 데이터를 빠르게 ML model로
83
현재 상황에서의
문제점 소개
문제점 개선을 위한
background
실제로 문제점을
개선한 사례
84.
환자 정보
(시계열 데이터)
n시간뒤 환자가
급성 질환에 걸릴 확률 예측
Dashboard
*
Data 전송
84
급성 질환
예측 솔루션
병원
ML model
DB의 데이터를 빠르게 ML model로
RECAP
85.
RECAP
시간별로 검색한 환자정보를 빠르게 가져오고,
받은 예측값을 빠르게 저장하는 것이 필수적
예측값시간별 환자정보
85
회사에서 개발 중인 Django를 이용한 서비스
급성 질환
예측 솔루션
ML model server
SCORE
DB
86.
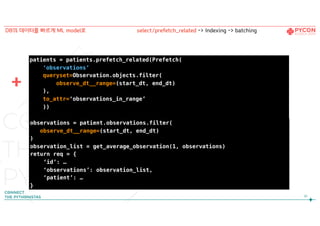
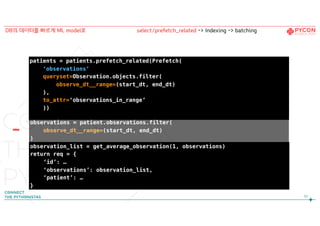
1. select_related &prefetch_related
2. Indexing
3. Batching
데이터를 빠르게 가져오고 저장하는 방법?
86
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
87.
select_related & prefetch_related
한Queryset를 가져올 때, related object들까지 다 불러와준다
-> 총 발생하는 쿼리수
+ 앞서 말한 Django ORM의 N+1 problem을 해결해준다 :)
https://jupiny.tistory.com/entry/selectrelated%EC%99%80-prefetchrelated
87
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
88.
select_related
JOIN 사용(Execute onlyone query)
single-valued relationships에서만! (foreign-key, one-to-one)
Patient.objects.select_related('location')
특징
예시
> SELECT `emr_patient`.`first_name`, `emr_patient`.`uid`, …
FROM `emr_patient`
LEFT OUTER JOIN `emr_location`
ON (`emr_patient`.location_id` = `emr_location`.`id`);
88
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
SQL
89.
prefetch_related
먼저 해당 object를가져온 후 별도의 query 실행
모든 relationships에서 사용가능! (foreign-key, many-to-many …)특징
예시
> SELECT `emr_patient`.`first_name`, `emr_patient`.`uid`, …
FROM `emr_patient;
> SELECT `emr_location`.`name`, `emr_location`.`uid`, …
FROM `emr_location`
WHERE ` emr_location`.`id` IN (list_of_patient_ids);
Patient.objects.prefetch_related(‘location’)
89
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
SQL
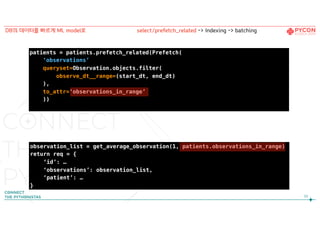
Indexing
!94
성 이름 입원일
김가나 18/12/21
김 다라 18/12/30
박 마바 18/7/26
이 사아 16/2/11
이 가나 19/3/4
박 자차 17/5/7
김 카타 19/5/23
이 파하 17/9/11
박 다라 16/10/30
김 마바 18/6/8
입원일
16/2/11
16/10/30
17/5/7
17/9/11
18/6/8
18/7/26
18/12/21
18/12/30
19/3/4
19/5/23
TABLEINDEX
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
95.
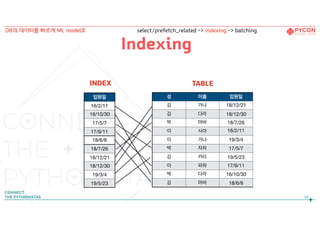
Indexing
!95
입원일이 18년 7월26일인 환자를 찾을 때?
성 이름 입원일
김 가나 18/12/21
김 다라 18/12/30
박 마바 18/7/26
이 사아 16/2/11
이 가나 19/3/4
박 자차 17/5/7
김 카타 19/5/23
이 파하 17/9/11
박 다라 16/10/30
김 마바 18/6/8
입원일
16/2/11
16/10/30
17/5/7
17/9/11
18/6/8
18/7/26
18/12/21
18/12/30
19/3/4
19/5/23
TABLEINDEX
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
96.
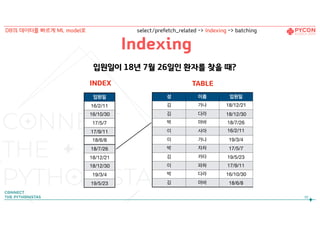
성 이름 입원일
김가나 18/12/21
김 다라 18/12/30
박 마바 18/7/26
이 사아 16/2/11
이 가나 19/3/4
박 자차 17/5/7
김 카타 19/5/23
이 파하 17/9/11
박 다라 16/10/30
김 마바 18/6/8
성
김
이
박
TABLE
INDEX
성이 “김”인 환자를 찾을 때?
부적절
96
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
Indexing
97.
좋을 때
나쁠 때
많이검색되어지는 Column
Join에 자주 사용되는 Column
INSERT/UPDATE/DELETE가 많이 일어남
데이터가 중복됨(예: 남/여, 성)
Indexing
97
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
98.
다루는 데이터는 시계열데이터
-시간 기준으로 자주 ORDERING
-검색도 주기적으로, 자주 일어남
-Select_related를 하면 Join도 일어남
-데이터가 중복되지 않음
-> 시간 field에 indexing!
98
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
99.
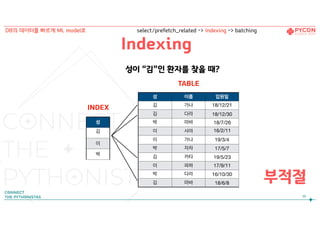
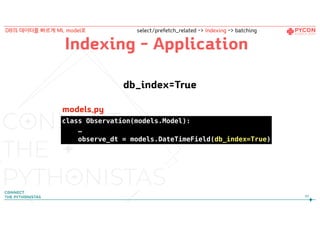
Indexing - Application
db_index=True
99
DB의데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
class Observation(models.Model):
…
observe_dt = models.DateTimeField(db_index=True)
models.py
100.
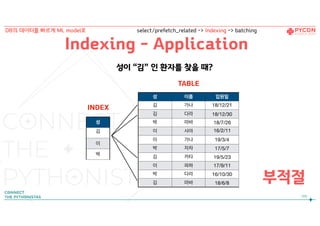
성 이름 입원일
김가나 18/12/21
김 다라 18/12/30
박 마바 18/7/26
이 사아 16/2/11
이 가나 19/3/4
박 자차 17/5/7
김 카타 19/5/23
이 파하 17/9/11
박 다라 16/10/30
김 마바 18/6/8
성
김
이
박
TABLE
INDEX
성이 “김” 인 환자를 찾을 때?
부적절
Indexing - Application
100
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
101.
!101
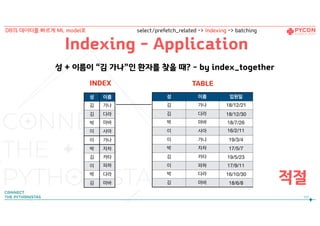
성 + 이름이“김 가나”인 환자를 찾을 때? - by index_together
성 이름 입원일
김 가나 18/12/21
김 다라 18/12/30
박 마바 18/7/26
이 사아 16/2/11
이 가나 19/3/4
박 자차 17/5/7
김 카타 19/5/23
이 파하 17/9/11
박 다라 16/10/30
김 마바 18/6/8
성 이름
김 가나
김 다라
박 마바
이 사아
이 가나
박 자차
김 카타
이 파하
박 다라
김 마바
TABLEINDEX
적절
Indexing - Application
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
102.
Indexing - Application
성+이름으로index_together도 가능
class Patient(models.Model):
first_name = models.TextField(db_index=True)
last_name= models.TextField(db_index=True)
class Meta:
index_together = [[‘first_name’, ‘last_name’]]
102
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
models.py
103.
Batching
predictions = []
forresult in results:
prediction = Prediction(
patient=result[‘patient’],
score=result[‘score’],
…
)
predictions.append(prediction)
if len(predictions) >= 1000:
Prediction.objects.bulk_create(predictions)
predictions = []
장점: 매 분마다 n개 이상의 Object를 생성해야 할 때
하나씩 저장하는 것 보다 I/O시간을 줄일 수 있어 효율적
103
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
요청을 n개씩 모아서 처리
1. 회사에서 개발중인 Django를 이용한 서비스
- 성능의 문제점을 중심으로
2. Django ORM이란?
- ORM의 특징과 실제 사용 사례를 중심으로
3. Query profiling하는 법
4. API로 들어온 대용량의 데이터를 빠르게 DB로
5. DB의 데이터를 빠르게 ML model로
105
현재 상황에서의
문제점 소개
문제점 개선을 위한
background
실제로 문제점을
개선한 사례
106.
• 파이썬 웹서버REST API 문서 쉽고 빠르게 작성하기 (Yongseon Lee)
18th (Sun) 11:55 ~ 12:35
• Advanced Python testing techniques (Jaeman An)
18th (Sun) 11:55 ~ 12:35
• 실시간 의료 인공지능 데이터 처리를 위한 Django Query Optimization (Soyoung Yoon)
18th (Sun) 13:55 ~ 14:35
• Pickle & Custom Binary Serializer (Young Seok Kim)
18th (Sun) 14:55 ~ 15:35
Talks from AITRICS
www.aitrics.com
contact@aitrics.com
Thank
Soyoung Yoon <lovelife@kaist.ac.kr>
We are Hiring!
● Software Engineer
● Machine Learning Researc





![병원
POST SAVE OR
UPDATE
예) 환자 정보 저장
mySQL DB
급성 질환
예측 솔루션
[23살의 여성환자 A
21살의 남성환자 B
56살의 여성환자 C
… ]
8
회사에서 개발 중인 Django를 이용한 서비스
1. API로 들어온 대용량의 데이터를 빠르게 DB로](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-8-320.jpg)




![bulk_create()
Patient.objects.bulk_create([Patient(name=‘soyoung’),
Patient(name=‘person1’) …])
한 번의 쿼리로 여러 objects를 db에 넣는다
주의 save()가 불리지 않음 -> pre_save & post_save signal 이 불리지 않음
Many-to-many relationship에서는 되지 않음
23
Django ORM이란?
soyoung
person1
…](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-23-320.jpg)




![ORM으로 실행한 실제 SQL을 보고 싶다!
>>> from django.db import connection
>>> Patient.objects.count()
>>> connection.queries[-1]
{‘sql’: ‘SELECT COUNT(*) AS `__count` FROM `emr_patient`’,
‘time’: ‘0.001’}
connection 모듈을 통해
queryset으로 만들어진 실제 sql문을 shell에서 확인할 수 있다.
31
Query profiling하는 법
connection.queries[-1]](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-31-320.jpg)


![settings.py
INSTALLED_APPS = [
…
‘debug_toolbar’,
…
]
MIDDLEWARE = [
…
‘debug_toolbar.middleware.DebugToolbarMiddleware’,
…
]
INTERNAL_IPS = (‘127.0.0.1’,)
1. Install DJDT
urls.py
import debug_toolbar
urlpatterns += [
path(‘__debug__/’,
include(‘debug_toolbar.urls’)),
]
34
Query profiling하는 법](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-34-320.jpg)

![settings.py
INSTALLED_APPS = [
…
‘silk’,
…
]
MIDDLEWARE = [
…
‘silk.middleware.SilkyMiddleware’,
…
]
How to Install
urls.py
urlpatterns += [
path(‘v1/silk/‘,
include(‘silk.urls’, namespace=‘silk’)],
]
migration
python manage.py makemigrations
&& python manage.py migrate
37
Query profiling하는 법
+](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-37-320.jpg)


![Query profiling하는 법 - 정리
44
Query profiling하는 법
str(my_query.query)
connection.queries[-1]
Profiling
-Django Debug Toolbar
-Silk
See query string](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-44-320.jpg)


![병원
POST SAVE OR
UPDATE
mySQL DB
급성 질환
예측 솔루션
48
API로 들어온 대용량의 데이터를 빠르게 DB로
def parse_patient(obj):
patient, _ = Patient.objects.get_or_create(uid=obj[‘uid’])
patient.gender = obj[‘GENDER’]
…
patient.save()](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-48-320.jpg)
![문제: Patient 하나씩 저장해서 느리다!
한 번에 저장할 수 있는 로직이 필요
def parse_patient(obj):
patient, _ = Patient.objects.get_or_create(uid=obj[‘uid’])
patient.gender = obj[‘GENDER’]
…
patient.save()
49
API로 들어온 대용량의 데이터를 빠르게 DB로](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-49-320.jpg)

![def parse_patients(objs):
patients = []
for obj in objs:
…
patients.append(patient)
Patient.objects.bulk_create(patients)
def parse_patient(obj):
patient, _ = Patient.objects.get_or_create(uid=obj[‘uid’])
patient.gender = obj[‘GENDER’]
…
patient.save()
AFTER
BEFORE
51
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-51-320.jpg)


![구현 방법
1. ORM
- DBMS 제한 없이 사용 가능. 보안 이슈 적음. 어느 정도 성능 최적화 가능.
- DB의 schema를 그대로 class로 매핑
2. Raw query
- 말 그대로 query를 자율적으로 조절 가능. (customizeable)
- 성능을 극대로 최적화할 수 있음.
54
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
Patient.objects.filter(uid__in=[1, 4, 5, 24..]).delete()
Patient.objects.raw(
‘DELETE FROM emr_patient where uid IN (1, 4, 5, 24..)’)](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-54-320.jpg)
![def parse_patients(objs):
patients = []
for obj in objs:
patients.append(Patient(uid=obj[‘uid’],
gender=obj[‘GENDER’],
…))
delete_and_create(patients, Patient.objects)
55
API로 들어온 대용량의 데이터를 빠르게 DB로
def delete_and_create(objects, manager):
uids = [o.uid for o in objects]
manager.filter(uid__in=uids).delete()
manager.bulk_create(objects)
bulk_create -> delete_and_create -> bulk_upsert](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-55-320.jpg)






![실행 과정
def execute_upsert(
model_class,
column_info_dict,
raw_objects,
update_keys=[]
):
64
예시는 Patient만 들었지만, 실제로 여러 모델에서 쓰인다.
여러 곳에서 쓰일 수 있도록 general한 함수를 만들자!
INSERT INTO … ( … ) VALUES ( … ) ON DUPLICATE KEY UPDATE ( … )
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-64-320.jpg)
![실행 과정
patients = execute_upsert(
Patient,
dict(
uid=(lambda x: x[‘uid’]),
first_name= …,
…
),
objs,
update_keys=[‘first_name’, …]
)
65
INSERT INTO
emr_patient
(uid, first_name, ..)
VALUES
(10110, ‘Soyoung Yoon’, …),
(11001, ‘Person Name’, …),
…
ON DUPLICATE
KEY UPDATE
uid=VALUES(uid),
first_name=VALUES(first_name),
… ;
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
parse.py](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-65-320.jpg)
![실행 과정
66
INSERT INTO
emr_patient
(uid, first_name, ..)
VALUES
(10110, ‘Soyoung Yoon’, …),
(11001, ‘Person Name’, …),
…
ON DUPLICATE
KEY UPDATE
uid=VALUES(uid),
first_name=VALUES(first_name),
… ;
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
patients = execute_upsert(
Patient,
dict(
uid=(lambda x: x[‘uid’]),
first_name= …,
…
),
objs,
update_keys=[‘first_name’, …]
)
parse.py](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-66-320.jpg)
![실행 과정
67
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
INSERT INTO
emr_patient
(uid, first_name, ..)
VALUES
(10110, ‘Soyoung Yoon’, …),
(11001, ‘Person Name’, …),
…
ON DUPLICATE
KEY UPDATE
uid=VALUES(uid),
first_name=VALUES(first_name),
… ;
patients = execute_upsert(
Patient,
dict(
uid=(lambda x: x[‘uid’]),
first_name= …,
…
),
objs,
update_keys=[‘first_name’, …]
)
parse.py](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-67-320.jpg)
![실행 과정
68
API로 들어온 대용량의 데이터를 빠르게 DB로 bulk_create -> delete_and_create -> bulk_upsert
INSERT INTO
emr_patient
(uid, first_name, ..)
VALUES
(10110, ‘Soyoung Yoon’, …),
(11001, ‘Person Name’, …),
…
ON DUPLICATE
KEY UPDATE
uid=VALUES(uid),
first_name=VALUES(first_name),
… ;
patients = execute_upsert(
Patient,
dict(
uid=(lambda x: x[‘uid’]),
first_name= …,
…
),
objs,
update_keys=[‘first_name’, …]
)
parse.py](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-68-320.jpg)

![1.기존 구현
def parse_patient(obj):
patient, _ = Patient.objects.get_or_create(uid=obj[‘uid’])
patient.gender = obj[‘GENDER’]
…
patient.save()
70
API로 들어온 대용량의 데이터를 빠르게 DB로 기존 구현 -> delete_and_create -> bulk_upsert](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-70-320.jpg)
![[{“Age": 21, "CalAge":21.34, "BIRTH_DAY_10":
"10/30/1997", "GENDER": "F", "DeadYmd": "",
"PatNm": "Soyoung Yoon", "UnitNo": “112310"}, …]
x 100
../patients/json
POST
71
API로 들어온 대용량의 데이터를 빠르게 DB로 기존 구현 -> delete_and_create -> bulk_upsert](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-71-320.jpg)















![Indexing - Application
성+이름으로 index_together도 가능
class Patient(models.Model):
first_name = models.TextField(db_index=True)
last_name= models.TextField(db_index=True)
class Meta:
index_together = [[‘first_name’, ‘last_name’]]
102
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
models.py](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-102-320.jpg)
![Batching
predictions = []
for result in results:
prediction = Prediction(
patient=result[‘patient’],
score=result[‘score’],
…
)
predictions.append(prediction)
if len(predictions) >= 1000:
Prediction.objects.bulk_create(predictions)
predictions = []
장점: 매 분마다 n개 이상의 Object를 생성해야 할 때
하나씩 저장하는 것 보다 I/O시간을 줄일 수 있어 효율적
103
DB의 데이터를 빠르게 ML model로 select/prefetch_related -> Indexing -> batching
요청을 n개씩 모아서 처리](https://image.slidesharecdn.com/pycon2019djangoqueryoptimization-190817205654/85/Pycon2019-django-query_optimization-103-320.jpg)



![[162] jpa와 모던 자바 데이터 저장 기술](https://cdn.slidesharecdn.com/ss_thumbnails/162jpa-150914054532-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Main Session] 미래의 Java 미리보기 - 앰버와 발할라 프로젝트를 중심으로](https://cdn.slidesharecdn.com/ss_thumbnails/java-180320135253-thumbnail.jpg?width=640&height=640&fit=bounds)










![[스마트스터디]스마트스터디처럼 Django 쓰지 마세요](https://cdn.slidesharecdn.com/ss_thumbnails/django-171107062547-thumbnail.jpg?width=640&height=640&fit=bounds)











![XECon2015 :: [2-1] 정광섭 - 처음 시작하는 laravel](https://cdn.slidesharecdn.com/ss_thumbnails/random-151116001443-lva1-app6892-2-160323043830-thumbnail.jpg?width=640&height=640&fit=bounds)