Download as PDF, PPTX








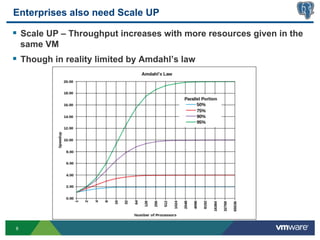





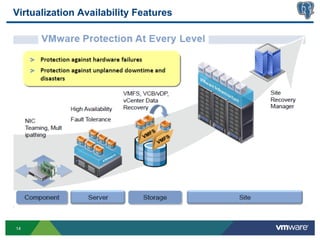

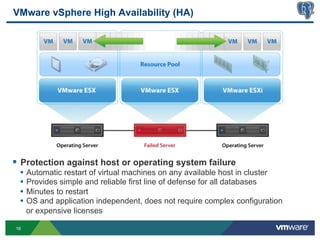
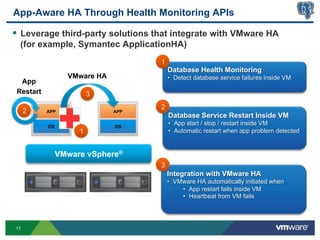
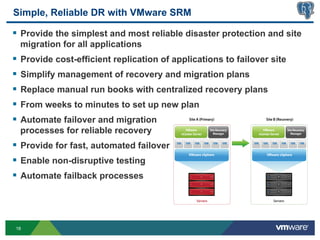



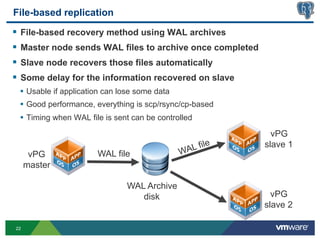
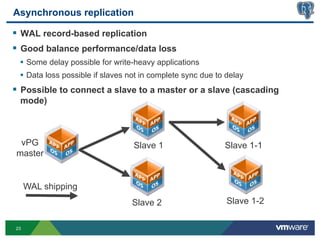
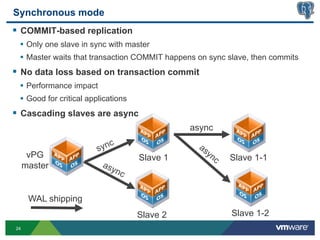

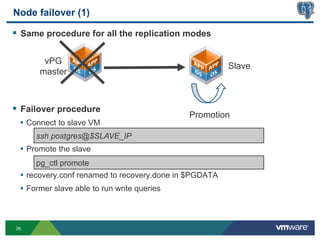

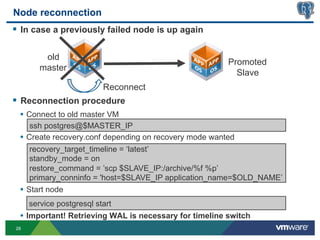


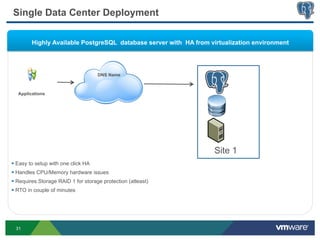

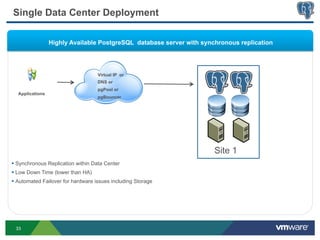
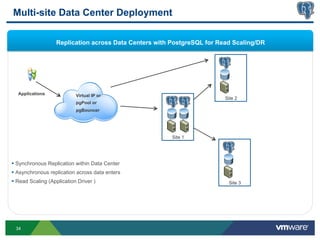
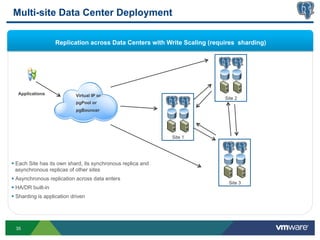
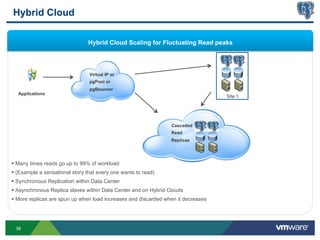
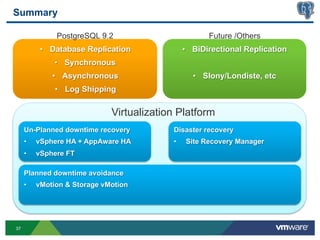



This document discusses best practices for high availability (HA) and replication of PostgreSQL databases in virtualized environments. It covers enterprise needs for HA, technologies like VMware HA and replication that can provide HA, and deployment blueprints for HA, read scaling, and disaster recovery within and across datacenters. The document also discusses PostgreSQL's different replication modes and how they can be used for HA, read scaling, and disaster recovery.











![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































