- 2 -
목차
코드 개발 환경
1. p.3
코드 진행 과정
2. p.3
가 플로우 차트
. p.3
나 이론적 배경과 동작
. p.5
다 코드 설명
. p.8
결과 분석 평가
3. p.17
코드 동작 과정
4. p.22
3.
- 3 -
1.코드 개발 환경
가. 개발 언어 파이썬
: 3.7
나. 사용 라이브러리: cv2, numpy, os, itertools, math
다. 통합 개발 환경 파이참
: 2020
라. 동영상 캡쳐 도구: Screen Recorder Pro
마. 영상 축소 도구 그림판
:
2. 코드 진행 과정
가. 플로우차트
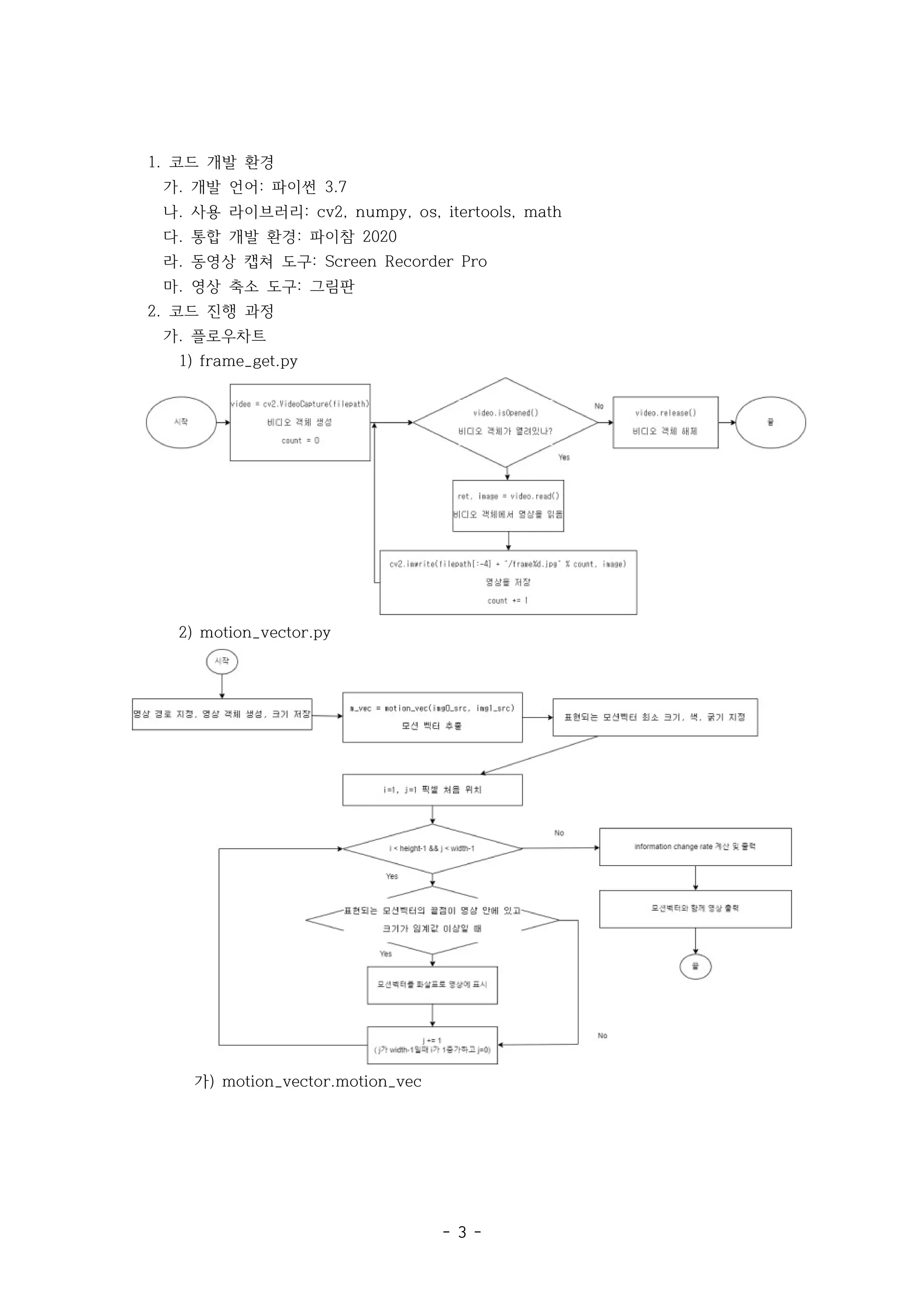
1) frame_get.py
2) motion_vector.py
가) motion_vector.motion_vec
- 5 -
4)mean_shift.py
가) mean_shift.sd_change_rate_mean_shift
나. 이론적 배경과 동작
1) Optical Flow
가) 다변수 함수의 선형근사식
고차항무시
원래 이미지 에 를 적용하여 타입에서
(img0_src, img1_src) cv2.cvtColor BGR
로 바꾼 다음 값을
YCbCr(img0, img1) Y 값으로 한다.(img0= img0[:,
:, 0]).
나) 밝기의 시간 불변성
Brightness Consistency ( )
6.
- 6 -
다)광류 조건식
,
는 에 를 적용하고 각
img0 numpy.gradient ( axis=0, 1) numpy.stack
으로 각 픽셀에 대하여 하나의 그래디언트 벡터를 대응시킨 텐서 를 구성한
grad
다.
는 과 의 차이를 를 적용하고 행렬 를
img1 img0 numpy.subtract grad_t
구한다.
2) 알고리즘
Lucas-Kanade
가) 이웃 픽셀의 모션 벡터는 동일
나) Overdetermined system
행렬 는 텐서 의 부분 텐서에 을 적용하여 텐서 를 구
grad numpy.stack mat_A
하고 벡터
, 는 행렬 의 부분 텐서에 을 적용하여 텐서
grad_t numpy.stack
를 구한다
vec_b .
를 구할 때는 에 텐서 와 텐서
numpy.linalg.lstsq mat_A
의 각 원소를 인수로 넣어 구하고 다시 으로 모션 벡터를 의
vec_b numpy.stack
미하는 텐서 을 구한다 은 각 픽셀에 대응하는 모션벡터를 최저차
m_vec . m_vec
원의 원소로 가진다.
3) K-means Clustering
가) 초기 중심점들을 랜덤하게 선택 이 보고서에서는 영상에 평면적으로 균등하게 분
:
포하도록 설정한다 중심점 개수가 이면 가로를
. n
등분 세로를
,
등
분하는 픽셀을 선택한다.
나) 각 객체를 가장 가까운 중심점에 배정 피쳐의 거리 개념은 유클리드 거리인
: L2
노름을 사용한다 노름은 피쳐의 차이 를 구하여
. feature_diff numpy.linalg.norm
에 넣어서 구한다 각 피처의 각 중심점과의 노름을 구해서 행렬 를 구
. norm_mat
성하고 으로 각 픽셀의 소속 중심점을 표현하는 행렬 를
np.argmin belonged_to
7.
- 7 -
구하고으로 소속 중심점과의 거리 표현하는 행렬 를 구한
, np.min diff_from_cent
다 는 제곱하여 로 만들고 이것을 픽셀
. diff_from_cent squared_diff_from_cent
에 대해 평균을 내서 를 구한다 그것의 이전 반복에서의 값
mean_sd_from_cent .
과의 변화량 이 수렴임계값 이하가 되면 반복을
epsilon (convergence_threshold)
멈춘다.
다) 배정된 객체의 평균으로 새로운 중심점 계산 행렬을 조사하여 각
: belonged_to
중심점에 소속되는 픽셀들의 좌표를 로 찾는다 픽셀들의 좌표로 피쳐들
np.where .
을 구하여 를 구성하고 여기에 을 적용하여 새로운 중
belonged_features np.mean
심점 를 구한다 이것들을 각 클러스터에 대해서 모아서 텐서 를 구
temp_cent . cent
성한다.
라) 특정 조건을 만족할 때까지 나 다를 반복 이 보고서에서는 나 에서 구한 각 객체
, : )
의 해당 중심점과의 거리제곱 평균의 변화량 이 수렴 임계값 이하가 되면
epsilon
반복을 멈춘다.
4) 알고리즘
Mean Shift
가) 모든 샘플의 피쳐 벡터를 구성 영상 로 모션벡터 를
: img0_src, img1_src m_vec
구하고 영상의 값과 픽셀의 인덱스값을 여기에 시켜 텐서
BGR concatenate
를 구성한다
feature_vec .
나) 각 샘플의 수렴점 계산 초기값
(convergence point) : 은 각 샘플의 피쳐
로 놓는다 다음 점화식을 통해
feature_vec[i] . 의 수렴값을 구한다.
단, exp
≤
, , 는 각각 샘플의 공간 모션벡터 성분
BGR, ,
위 식은 에 대해 함수를 정의하고 모든
gaussian_kernel 의 공간
BGR, ,
모션벡터 성분을 입력하여 각각의 커널 값을 구한 뒤 하나로 곱하여 텐서
,
을 만든다 그것을 차원의 로 중복시킨 다음
kernel . 7 kernel_augmented
와 곱하고 합계를 구해서 분자로 만들고 다시 의 합계를 구하
feature_vec kernel
여 분모로 해서 을 구한다 프로그램 상에서는 함수로 구현했다 와
. y_next . y
의 노름이 이하이면 를 구하는 반복을
y_next L2 convergence_threshold y_next
멈추고 를 수렴값의 리스트 에 추가한다 이 과정을 모든 샘플에 대해 반
y_next v .
복한다.
8.
- 8 -
다)군집화 군집화를 위해 두 개의 딕셔너리를 정의한다 클러스터를
(Clustering) : .
수집하는 와 클러스터의 중심을 수집하는 가 그것이
clusters cluster_centers
다 각 샘플이 어느 클러스터에 속하는지 기록하는 배열도 정의한
. belongs_to
다 수렴값 리스트에서 원소를 하나씩 꺼내어 각 클러스터 센터와의 공간
. BGR, ,
모션벡터의 편차를 구한다 이 계산은 이라는 함수로 정의하였다 그
. dist_tuple .
래서 모든 편차가 각 커널 스케일인 이하이면 수렴값은 그 클러스터
에 소속된다 만약 소속되는 클러스터가 없다면 새로운 클러스터를 딕셔너리에
.
추가하고 그 클러스터에 수렴값을 넣고 수렴값을 새 클러스터의 중심으로 한다.
라) 작은 분할 제거 를 탐색하여 보다 적은 샘플을 보유
: cluster_center min_area
하는 클러스터를 클러스터 중심과 가장 가까운 클러스터 중심을 가진 클러스터
,
에 병합시킨다 병합은 클러스터를 표현하는 리스트 간에 덧셈 연산을 적용한
.
다 이때 병합되는 클러스터의 모든 샘플이 소속되는 클러스터를 병합하는 클러
.
스터로 바꾼다 병합 후에는 작은 클러스터와 클러스터 센터를 삭제한다
. .
다. 코드 설명
1) 알고리즘
Optical Flow(Lucas-Kanade ) : motion_vector.py
img0_path = './dataset/hop_far/frame19.jpg'
img1_path = './dataset/hop_far/frame20.jpg'
img0_src = cv2.imread(img0_path)
img1_src = cv2.imread(img1_path)
height = len(img0_src)
width = len(img0_src[0])
m_vec = motion_vec(img0_src, img1_src)
threshold = 16
color = (255, 0, 0)
thickness = 1
이미지의 경로를 지정하고 이미지를 읽는다 이미지의 크기를 저장한다
. .
와 에 대응하는 이미지 를 입력으로 모션 벡터를 구한다 출력 가능
t t+1 img0_src, img1_src .
한 모션벡터의 최소 크기를 에 저장하고 모션 벡터의 색과 굵기를 지정한다
threshold .
for i in range(1, height-1):
for j in range(1, width-1):
if 0 <= i + m_vec[i, j, 0] < height and 0 <= j + m_vec[i, j, 1] < width:
if np.linalg.norm(m_vec[i, j]) >= threshold:
img_result = cv2.arrowedLine(img0_src, (i, j), (int(i + m_vec[i, j,
0]), int(j + m_vec[i, j, 1])), color, thickness)
모든 이미지의 픽셀 단 모션 벡터를 구할 수 없는 이미지의 경계는 제외 에 대해 모션 벡터가
( , )
이미지 상에 표현될 수 있는 끝점을 가질 때 모션 벡터의 크기가 임계값 이상이라면 이미지
,
위에 모션벡터를 화살표로 그린다.
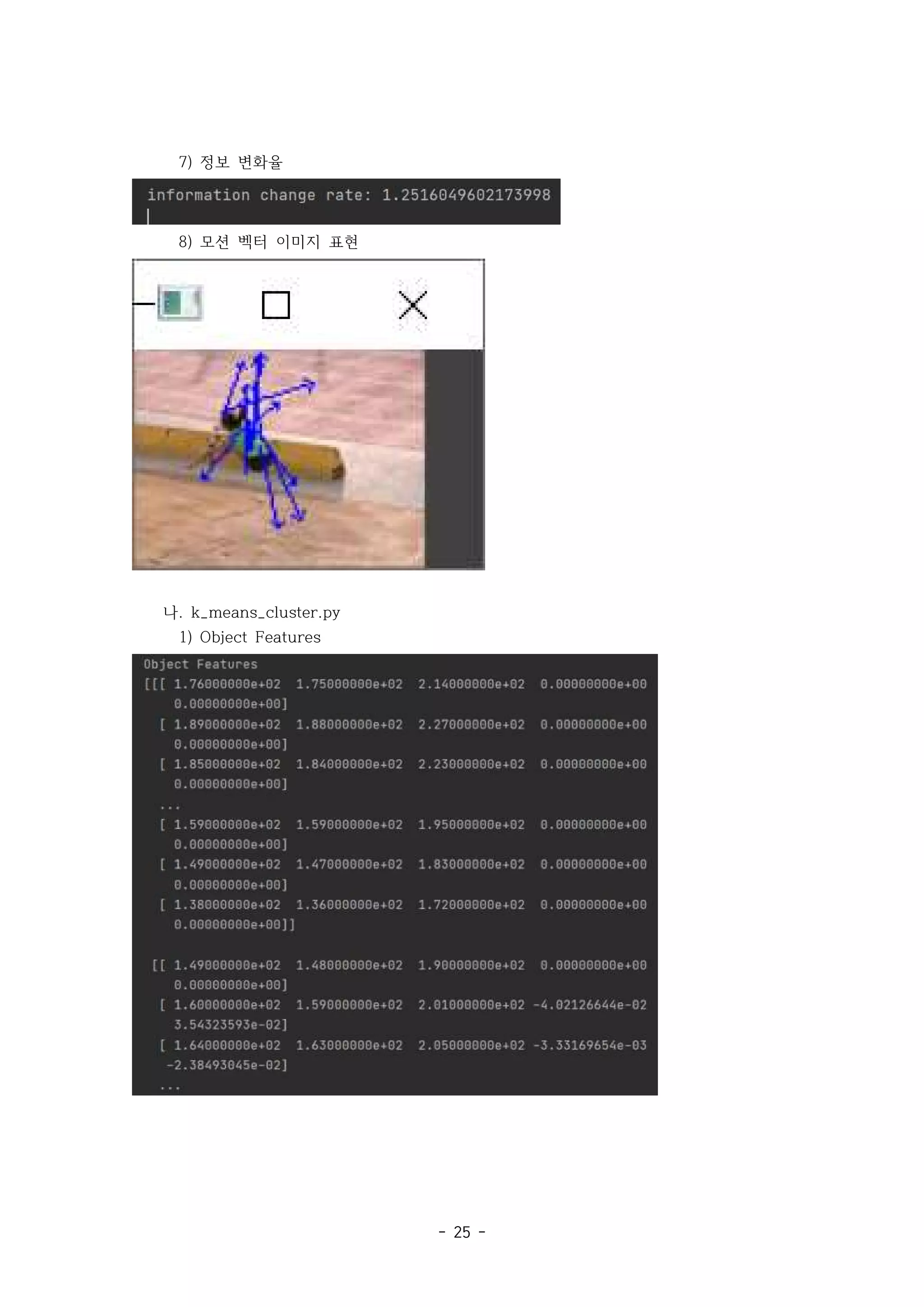
information_change_rate = info_change_rate_m_vec(img0_src, img1_src, m_vec)
print('information change rate:', information_change_rate)
cv2.imshow('motion vector', img_result)
cv2.waitKey()
정보 변화량을 구하여 출력하고 모션벡터를 가진 이미지를 출력한다.
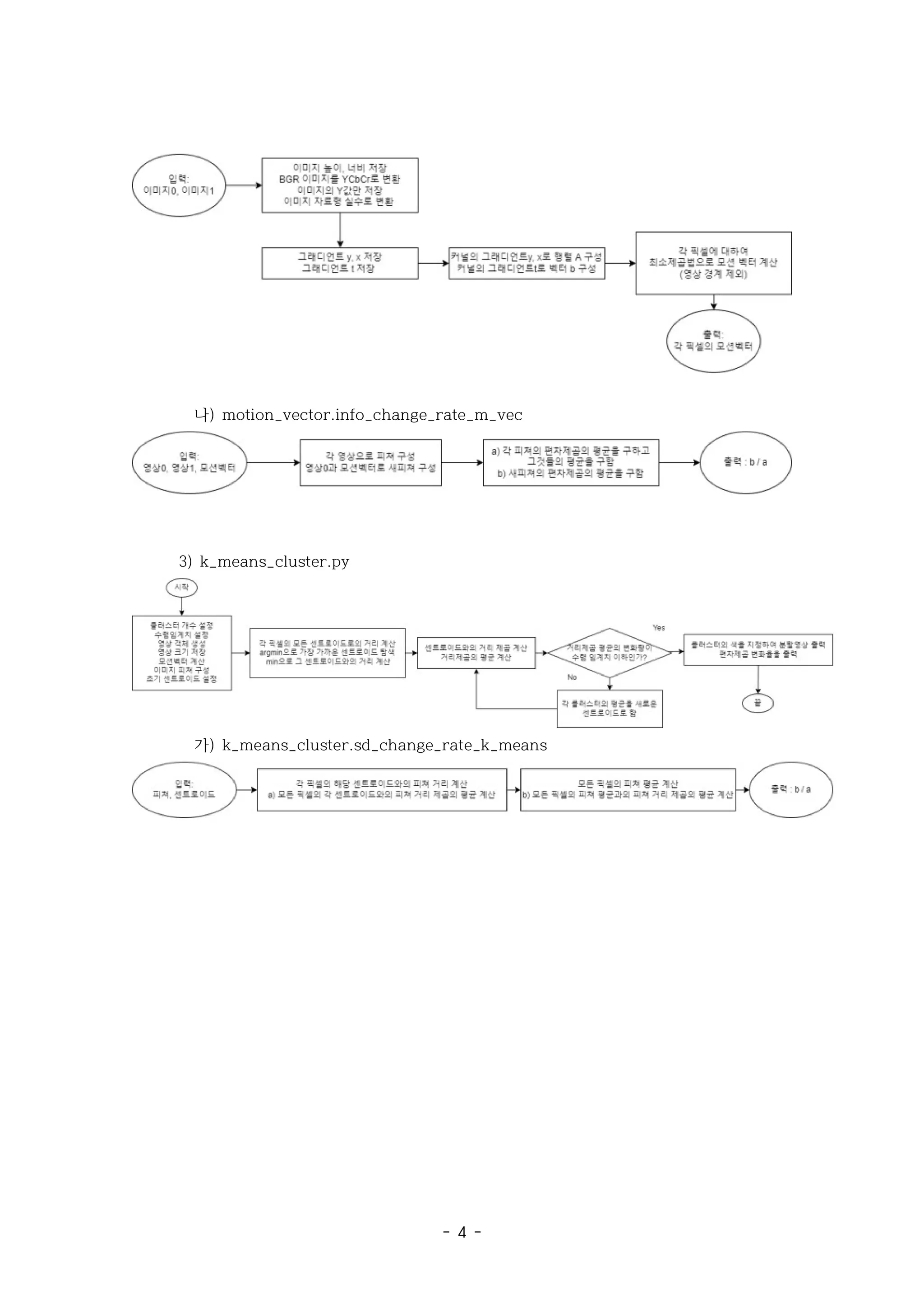
가) motion_vector.motion_vec
height = len(img0_src)
width = len(img0_src[0])
9.
- 9 -
img0= cv2.cvtColor(img0_src, cv2.COLOR_BGR2YCR_CB)
img1 = cv2.cvtColor(img1_src, cv2.COLOR_BGR2YCR_CB)
img0 = img0[:, :, 0]
img1 = img1[:, :, 0]
img0 = np.array(img0).astype(np.float)
img1 = np.array(img1).astype(np.float)
grad_y = np.gradient(img0, axis=0)
grad_x = np.gradient(img0, axis=1)
grad = np.stack([grad_y, grad_x], axis=-1)
grad_t = np.subtract(img1, img0)
이미지의 높이와 너비를 저장한다 픽셀 값의 타입을 로 바꾸고 값만을 저장한다
. YCR_CB Y .
데이터 타입을 실수로 바꾼다 그래디언트 와 를 구한다
. y x, t .
if neighbor_type == 0:
grad_list = [
grad[:-2, :-2], grad[:-2, 1:-1], grad[:-2, 2:],
grad[1:-1, :-2], grad[1:-1, 1:-1], grad[1:-1, 2:],
grad[2:, :-2], grad[2:, 1:-1], grad[2:, 2:]
]
elif neighbor_type == 1:
grad_list = [
grad[:-2, 1:-1],
grad[1:-1, :-2], grad[1:-1, 1:-1], grad[1:-1, 2:],
grad[2:, 1:-1]
]
mat_A = np.stack(grad_list, axis=2)
이웃 타입 상하 좌우 대각선 개의 이웃 상하 좌우 개의 이웃 에 따라 과결정 방정
(0: , , 8 , 1: , 4 )
식의 행렬 에 해당하는 성분을 결정한다 픽셀의 위치에 따라 다른 행렬 를 으로
A . A np.stack
텐서로 합친다.
if neighbor_type == 0:
grad_t_list = [
grad_t[:-2, :-2], grad_t[:-2, 1:-1], grad_t[:-2, 2:],
grad_t[1:-1, :-2], grad_t[1:-1, 1:-1], grad_t[1:-1, 2:],
grad_t[2:, :-2], grad_t[2:, 1:-1], grad_t[2:, 2:]
]
elif neighbor_type == 1:
grad_t_list = [
grad_t[:-2, 1:-1],
grad_t[1:-1, :-2], grad_t[1:-1, 1:-1], grad_t[1:-1, 2:],
grad_t[2:, 1:-1]
]
vec_b = np.stack(grad_t_list, axis=2)
vec_b = -vec_b
이웃 타입 상하 좌우 대각선 개의 이웃 상하 좌우 개의 이웃 에 따라 과결정 방정
(0: , , 8 , 1: , 4 )
식의 벡터 에 해당하는 성분을 결정한다 픽셀의 위치에 따라 다른 벡터 를 으로
b . b np.stack
텐서로 합치고 부호를 바꿔준다.
m_vec_v = []
m_vec_u = []
for i in range(0, height-2):
for j in range(0, width-2):
v, u = np.linalg.lstsq(mat_A[i, j], vec_b[i, j], rcond=None)[0]
m_vec_v.append(v)
m_vec_u.append(u)
m_vec_v = np.array(m_vec_v)
m_vec_u = np.array(m_vec_u)
m_vec_v = np.reshape(m_vec_v, (height-2, width-2))
m_vec_u = np.reshape(m_vec_u, (height-2, width-2))
10.
- 10 -
m_vec_v= np.pad(m_vec_v, ((1, 1), (1, 1)), 'constant', constant_values=(0, 0))
m_vec_u = np.pad(m_vec_u, ((1, 1), (1, 1)), 'constant', constant_values=(0, 0))
m_vec = np.stack([m_vec_v, m_vec_u], axis=2)
return m_vec
모션 벡터의 성분 를 저장할 리스트를 만든다
v, u .
텐서 와 의 픽셀 위치에 해당하는 성분으로 과결정방정식을 구성하고
mat_A vec_b
에 대입하여 모션 벡터의 성분 를 구한다 리스트에 성분들을 저장한다
np.linalg.lstsq v, u . .
리스트를 배열로 바꾸고 이미지의 픽셀에 대응하도록 형태를 바꾼다 이미지 테두리
numpy .
에 모션벡터가 구해지지 않는 픽셀의 그래디언트를 패딩을 통해 으로 만든다 모션 벡터의
0 .
각 성분을 을 통해 하나의 순서쌍으로 합치고 반환한다
np.stack .
나) motion_vector.info_change_rate_m_vec
def info_change_rate_m_vec(img0_src, img1_src, m_vec):
feat0 = np.reshape(img0_src, (-1, 3))
feat1 = np.reshape(img1_src, (-1, 3))
new_feat = np.concatenate([img0_src, m_vec], axis=-1)
new_feat = np.reshape(new_feat, (-1, 5))
mean_feat0 = np.mean(feat0, axis=0)
mean_feat1 = np.mean(feat1, axis=0)
mean_new_feat = np.mean(new_feat, axis=0)
mean_squared_diff0 = np.mean(np.square(np.linalg.norm(feat0 -
mean_feat0)))
mean_squared_diff1 = np.mean(np.square(np.linalg.norm(feat1 -
mean_feat1)))
mean_mean_sd = (mean_squared_diff0+mean_squared_diff1)/2
mean_squared_diff_new = np.mean(np.square(np.linalg.norm(new_feat -
mean_new_feat)))
return mean_squared_diff_new/mean_mean_sd
모션 벡터를 구하기 전의 두 이미지 를 픽셀 순서로 일렬로 만들어
img0_src, img1_src
과 을 구성한다 모션벡터와 를 하여 마찬가지로 일렬로 만들어
feat0 feat1 . img0_src concat
을 구성한다 과 각각의 평균
new_feat . feat0 feat1, new_feat mean_feat0, mean_feat1,
을 구하고 각 피쳐가 평균과 이루는 거리의 평균을 제곱하여
mean_new_feat
을 구한다 그것들의 이미지 장에 대한 평균인 를
mean_squared_diff0, 1 . 2 mean_mean_sd
구한다 마찬가지로 새롭게 구성된 피쳐가 평균과 이루는 거리의 평균을 제곱하여
.
를 구한다 와 의 비율을
mean_squared_diff_new . mean_mean_sd mean_squared_diff_new
계산하여 정보량의 변화를 구하여 반환한다.
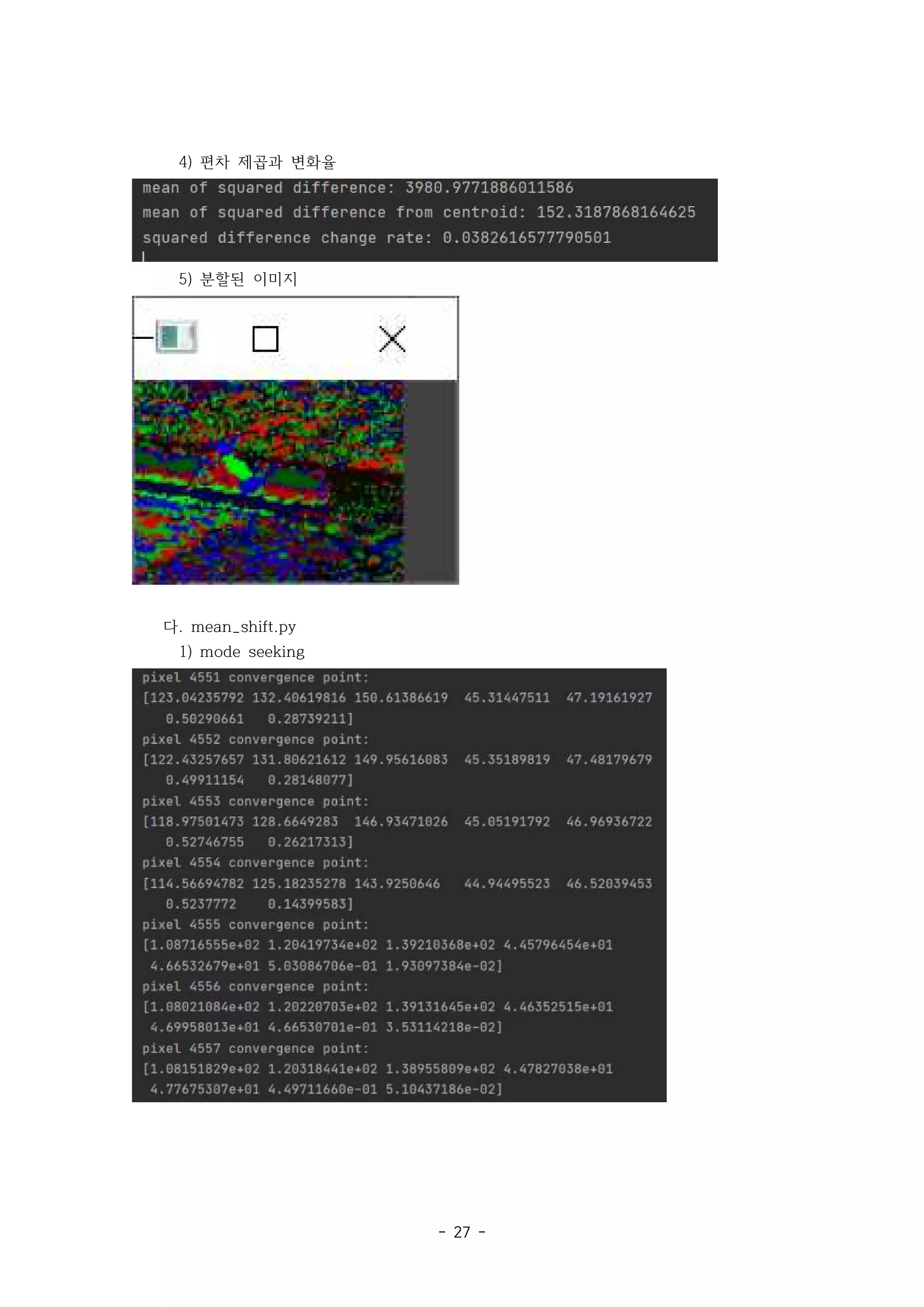
2) K-means Clustering : k_means_cluster.py
num_clusters = 16
convergence_threshold = 8
img0_path = './dataset/hop_far/frame19.jpg'
img1_path = './dataset/hop_far/frame20.jpg'
img0_src = cv2.imread(img0_path, cv2.IMREAD_COLOR)
img1_src = cv2.imread(img1_path, cv2.IMREAD_COLOR)
height = len(img0_src)
width = len(img0_src[0])
m_vec = motion_vec(img0_src, img1_src)
img_feature = np.concatenate([img0_src, m_vec], axis=2)
클러스터 개수 수렴 임계값 이미지 경로를 설정한다 이미지를 생성하고 그 높이와 너비를
, , .
저장한다 모션벡터를 추출하고 이미지의 값과 한다
. BGR concat .
square_root = int(math.sqrt(num_clusters))
cent_y = [(i+1)*height//square_root for i in range(square_root-1)]
11.
- 11 -
cent_x= [(i+1)*width//square_root for i in range(square_root-1)]
cent = np.stack([img_feature[i, j] for j in cent_x for i in cent_y], axis=0)
num_cents = len(cent)
초기 클러스터 중심을 설정한다 원래의 알고리즘은 순수하게 랜덤으로 설정하지만 이 보고서
.
에서는 이미지 상에서 공간적으로 클러스터 개수만큼 등분하는 점의 피쳐를 초기 클러스터 중
심으로 설정했다.
iter = -1
epsilon = 0
prev_mean_sd_from_center = 0
클러스터 중심을 변화시키는 반복을 하기 위해 제어 변수를 초기화한다 는 반복회수
. iter ,
은 평균적인 중심으로부터의 편차제곱의 차를 의미하고
epsilon prev_mean_sd_from_center
는 반복시점 직전의 중심으로부터의 편차제곱을 의미한다.
while True:
iter += 1
print('iter:', iter)
norm_mat_list = []
for i in range(num_cents):
feature_diff = img_feature - cent[i]
norm_mat_list.append(np.linalg.norm(feature_diff, axis=-1))
norm_mat = np.stack(norm_mat_list, axis=-1)
belongs_to = np.argmin(norm_mat, axis=-1)
diff_from_cent = np.min(norm_mat, axis=-1)
squared_diff_from_cent = diff_from_cent * diff_from_cent
mean_sd_from_cent = np.sum(squared_diff_from_cent) / (height * width)
if iter == 0:
epsilon = mean_sd_from_cent
else:
epsilon = abs(prev_mean_sd_from_center - mean_sd_from_cent)
if epsilon <= convergence_threshold:
break
prev_mean_sd_from_center = mean_sd_from_cent
new_cent = []
for i in range(num_cents):
y_cords, x_cords = np.where(belongs_to == iI
belonged_features = np.stack([img_feature[y_cords[i], x_cords[i]] for
i in range(len(y_cords))], axis=0)
temp_cent = np.mean(belonged_features, axis=0)
new_cent.append(temp_cent)
cent = np.stack(new_cent, axis=0)
반복횟수를 증가시키고 그것을 출력한다 각 피쳐 객체들의 각 센터와의 피쳐값의 차이를 구
.
해서 에 넣어 피쳐 거리를 구한다 이것을 으로 배열 로
np.linalg.norm . np.stack norm_mat
만든다 여기에 과 을 적용하여 객체가 속하는 클러스터와 그 클러스터의 중심과
. argmin min
의 거리 를 구한다 를 제곱하고 평균을 구하여 중심으로부터
diff_from_cent . diff_from_cent
의 평균 편차제곱 을 구한다 반복의 처음이라면 을
mean_sd_from_cent . epsilon
로 하고 아니면 이전 평균 편차제곱과 현재 평균 편차제곱의 합으로 한
mean_sd_from_cent
다 이 수렴 임계값 이하라면 반복을 멈춘다
. epsilon .
새로운 클러스터 중심을 찾기 위해 각 클러스터에 속한 객체를 로 탐색하고 그것
np.where
의 피쳐를 에 저장한다 그것에 을 적용하여 클러스터 중심을 구
beloned_features . np.mean
하고 에 저장한 뒤 배열 를 최신화한다
new_cent , cent .
img = np.zeros((3, belongs_to.shape[0], belongs_to.shape[1]))
img[0][belongs_to % 3 == 0] = (num_cents - belongs_to[belongs_to % 3 ==
12.
- 12 -
0])*255//num_cents
img[2][belongs_to% 3 == 1] = (num_cents - belongs_to[belongs_to % 3 ==
1])*255//num_cents
img[1][belongs_to % 3 == 2] = (num_cents - belongs_to[belongs_to % 3 ==
2])*255//num_cents
img = np.transpose(img, (1, 2, 0))
img = img.astype(np.uint8)
sd_change_rate = sd_change_rate_k_means(img_feature, cent)
cv2.imshow('segmented image', img)
cv2.waitKey()
출력할 이미지를 로 초기화한다 클러스터 번호가 의 배수인 객체의 값으로
np.zeros . 3 blue
클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈 나머지가 인 객체
. 3 1
의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈
green . 3
나머지가 인 객체의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 이미지의 형태
2 red .
를 변형하고 자료형을 변형한다 평균 편차의 변화율을 계산한 다음 결과 이미지를 출력한다
. .
가) k_means_cluster.sd_change_rate_k_means
def sd_change_rate_k_means(feat, cent):
num_cents = len(cent)
norm_mat_list = []
for i in range(num_cents):
feature_diff = feat - cent[i]
norm_mat_list.append(np.linalg.norm(feature_diff, axis=-1))
norm_mat = np.stack(norm_mat_list, axis=-1)
diff_from_cent = np.min(norm_mat, axis=-1)
squared_diff_from_cent = diff_from_cent * diff_from_cent
mean_sd_from_cent = np.mean(squared_diff_from_cent)
feat = np.reshape(feat, (-1, feat.shape[-1]))
mean_feat = np.mean(feat, axis=0)
feature_diff = feat - mean_feat
norm_arr = np.linalg.norm(feature_diff, axis=-1)
squared_diff = norm_arr*norm_arr
mean_sd = np.mean(squared_diff)
print('mean of squared difference:', mean_sd)
print('mean of squared difference from centroid:', mean_sd_from_cent)
print('squared difference change rate:', mean_sd_from_cent/mean_sd)
return mean_sd_from_cent/mean_sd
피쳐들과 클러스터 중심을 이용해 클러스터링 전후의 편차제곱 평균의 변화율을 구한다.
먼저 클러스터 개수를 저장하고 빈 거리 리스트를 만든다 클러스터 개수만큼 반복하여 각 피
.
쳐가 각 클러스터 중심과 이루는 거리를 계산하여 리스트에 저장한다 으로 리스트를
. np.stack
넘파이 배열로 만들고 으로 소속된 클러스터의 중심과의 거리 를 구한
np.min diff_from_cent
다 를 제곱하고 평균 을 구한다 다시 피쳐들 전체의 평
. diff_from_cent mean_sd_from_cent .
균 피쳐 를 구하고 각 피쳐가 평균 피쳐와 이루는 거리를 제곱하여 평균 편차제곱
mean_feat
를 구한다 와 의 비율을 구하여 반환한다
mean_sd . mean_sd_from_cent mean_sd .
3) Mean Shift : mean_shift.py
hr = 64
hs = 64
hm = 64
convergence_threshold = 32
img0_path = './dataset/hop_far/frame19.jpg'
13.
- 13 -
img1_path= './dataset/hop_far/frame20.jpg'
min_area = 256
img0_src = cv2.imread(img0_path, cv2.IMREAD_COLOR)
img1_src = cv2.imread(img1_path, cv2.IMREAD_COLOR)
height = len(img0_src)
width = len(img0_src[0])
coord = np.array(list(itertools.product(range(height), range(width))))
coord = np.reshape(coord, (height, width, 2))
m_vec = motion_vec(img0_src, img1_src)
feature_mat = np.concatenate([img0_src, coord, m_vec], axis=-1)
feature_vec = np.reshape(feature_mat, (height*width, 7))
커널 스케일 수렴 임계값 이미지 경로 클러스터 최소 픽셀 개수를 설정한다 이미지를 읽어
, , , .
오고 그 높이와 너비를 저장한다 이미지의 좌표를 피쳐로 만든다 모션벡터를 계산한다
. . . BGR
과 좌표 모션벡터를 하여 하나의 피쳐맵으로 만든다 피쳐맵을 하나의 열
, concat .
로 만든다
feature_vec .
print('mode seeking')
v = []
for i in range(height*width):
y = feature_vec[i]
while True:
y_n = y_next(feature_vec, y)
if np.linalg.norm(y_n-y) <= convergence_threshold:
print('pixel'+str(i)+': break')
break
y = y_n
v.append(y_n)
모드 탐색을 시작한다 모드를 저장할 빈 리스트를 만든다 피쳐 벡터 전체를 돌면서 다음을
. .
반복한다 각 피쳐 에 대하여 윈도우 안의 주변 피쳐들과의 평균을 구하여 로 한다
. y y_next . y
와 의 거리가 수렴 임계값 이하면 반복을 중단한다 그렇지 않으면 를 로 하고
y_next . y_next y
같은 과정을 반복한다 반복이 끝날 때의 를 리스트에 저장한다
. y_next .
print('clustering')
num_clusters = 0
clusters = {}
cluster_centers = {}
belongs_to = np.zeros((height*width,), dtype=np.int)
for i in range(len(v)):
print('convergence point', str(i), 'clustering')
new_cluster_flag = True
for j in range(num_clusters):
bgr_d, spatial_d, motion_d = dist_tuple(v[i], cluster_centers[j])
if bgr_d <= hr and spatial_d <= hs and motion_d <= hm:
new_cluster_flag = False
clusters[j].append(v[i])
belongs_to[i] = j
break
if new_cluster_flag:
clusters[num_clusters] = []
clusters[num_clusters].append(v[i])
cluster_centers[num_clusters] = v[i]
belongs_to[i] = num_clusters
num_clusters += 1
수렴점들의 군집화를 시작한다 클러스터의 개수 클러스터 딕셔너리 크러스터 중심 딕셔너
. , ,
14.
- 14 -
리소속 클러스터 저장 배열을 초기화한다 모드 리스트의 각 수렴점에 대하여 반복문을 처
, .
리한다 새로운 클러스터를 만들어야하는지 체크하는 플래그 를 로 초
. new_cluster_flag True
기화한다 수렴점과 각 클러스터의 공간 모션 피쳐 거리를 구하는 것을 반복하면서 각
. BGR, ,
각 커널 스케일 이하면 를 로 하고 그 때의 클러스터에 수렴점을 넣는
new_cluster_flag False
다 해당 수렴점을 가진 픽셀의 소속을 그 클러스터로 하고 반복을 멈춘다
. .
가 변하지 않고 이면 딕셔너리에 새 클러스터의 빈 리스트를 만들고
new_cluster_flag True
거기에 수렴점을 넣는다 클러스터의 중심은 최초로 소속되는 수렴점으로 한다 해당 수렴점
. .
을 가진 픽셀의 소속도 그 클러스터로 한다 클러스터 전체의 개수도 증가시킨다
. .
print('small segment removal')
for i in range(num_clusters):
if i not in clusters.keys():
continue
if len(clusters[i]) < min_area:
min_dist = 10000000000000
nearest_cluster = -1
for j in range(num_clusters):
if j not in clusters.keys():
continue
if j != i
center_diff = np.linalg.norm( cluster_centers[j] -
cluster_centers[i])
if center_diff < min_dist:
min_dist = center_diff
nearest_cluster = j
for feat in clusters[i]:
belongs_to[int(feat[3])*height+int(feat[4])] = nearest_cluster
clusters[nearest_cluster] = clusters[nearest_cluster] + clusters[i]
del(clusters[i])
del(cluster_centers[i])
작은 분할을 제거하기 시작한다 모든 클러스터에 대해 반복문을 돈다 단 클러스터 번호가
. . ,
클러스터 딕셔너리의 유효한 킷값일 때만 반복한다 클러스터의 원소 개수가 최소 픽셀 개수
.
인 미만이면 최근접 클러스터 중심을 찾는다 최소 거리 를 매우 큰 값으
min_area . min_dist
로 초기화한다 모든 클러스터에 대해 반복문을 돈다 유효한 클러스터 번호에 대하여 클러스
. .
터 번호에 해당하는 클러스터의 중심과 작은 클러스터 중심과의 거리를 구하여 보다
min_dist
작으면 그것을 로 하고 최근접 클러스터를 해당 클러스터로 해서 최근접 클러스터를
min_dist
구한다 작은 클러스터에 속하는 모든 픽셀의 소속을 최근접 클러스터로 바꾸고 최근접 클러
.
스터에 작은 클러스터를 병합한다 작은 클러스터와 그 중심은 딕셔너리에서 제거한다
. .
belongs_to = np.reshape(belongs_to, (height, width))
img = np.zeros((3, belongs_to.shape[0], belongs_to.shape[1]))
img[0][belongs_to % 3 == 0] = (num_clusters - belongs_to[belongs_to % 3 ==
0])*255//num_clusters
img[2][belongs_to % 3 == 1] = (num_clusters - belongs_to[belongs_to % 3 ==
1])*255//num_clusters
img[1][belongs_to % 3 == 2] = (num_clusters - belongs_to[belongs_to % 3 ==
2])*255//num_clusters
img = np.transpose(img, (1, 2, 0))
img = img.astype(np.uint8)
sd_change_rate = sd_change_rate_mean_shift(feature_mat, cluster_centers)
cv2.imshow('segmented image', img)
15.
- 15 -
cv2.waitKey()
픽셀의소속 클러스터를 나타내는 배열을 매트릭스로 바꾼다
belongs_to .
출력할 이미지를 로 초기화한다 클러스터 번호가 의 배수인 객체의 값으로
np.zeros . 3 blue
클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈 나머지가 인 객체
. 3 1
의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈
green . 3
나머지가 인 객체의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 이미지의 형태
2 red .
를 변형하고 자료형을 변형한다 평균 편차의 변화율을 계산한 다음 결과 이미지를 출력한다
. .
가) mean_shift.sd_change_rate_mean_shift
def sd_change_rate_mean_shift(feat, cent):
height = len(feat)
width = len(feat[0])
norm_mat_list = []
for i in cent.keys():
feature_diff = feat - feat[int(cent[i][3])][int(cent[i][4])]
norm_mat_list.append(np.linalg.norm(feature_diff, axis=-1))
norm_mat = np.stack(norm_mat_list, axis=-1)
diff_from_cent = np.min(norm_mat, axis=-1)
squared_diff_from_cent = diff_from_cent * diff_from_cent
mean_sd_from_cent = np.sum(squared_diff_from_cent)/(height*width)
feat = np.reshape(feat, (-1, feat.shape[-1]))
mean_feat = np.mean(feat, axis=0)
feature_diff = feat - mean_feat
norm_arr = np.linalg.norm(feature_diff, axis=-1)
squared_diff = norm_arr*norm_arr
mean_sd = np.mean(squared_diff)
print('mean of squared difference:', mean_sd)
print('mean of squared difference from cluster center:',
mean_sd_from_cent)
print('squared difference change rate:', mean_sd_from_cent/mean_sd)
return mean_sd_from_cent/mean_sd
피쳐들과 클러스터 중심을 이용해 클러스터링 전후의 편차제곱 평균의 변화율을 구한다.
먼저 피쳐 매트릭스의 높이 너비를 저장한다 피쳐와 클러스터 중심간의 노름을 저장할 빈
, .
리스트 를 만든다 클러스터 중심의 킷값들에 대하여 피쳐와 중심의 거리를 구
norm_mat_list .
해 에 넣는다 를 으로 텐서인 으로 만든
norm_mat_list . norm_mat_list np.stack norm_mat
다 으로 클러스터 중심으로부터의 거리인 를 구한다 이것을 제곱하고
. np.min diff_from_cent .
평균을 구하여 로 한다 피쳐 텐서를 일렬로 만든다 피쳐들의 평균
mean_sd_from_cent . .
을 구하고 각 피쳐의 평균과의 거리를 구해서 제곱하여 평균을 내서 로
mean_feat mean_sd
한다 를 출력하고 그것의 비율도 출력하고 반환한다
. mean_sd, mean_sd_from_cent .
나) mean_shift.gaussian_kernel
def gaussian_kernel(x):
norm = np.linalg.norm(x, axis=-1)
gk = np.zeros_like(norm)
gk[norm <= 1] = np.exp(-norm[norm <= 1]*norm[norm <= 1])
return gk
인수의 크기를 구하고 그것이 이하면 제곱을 해서 음수를 취하고 오일러상수의 지수로하여
1
반환한다.
다) mean_shift.y_next
16.
- 16 -
defy_next(feature_vec, y):
kernel = gaussian_kernel((feature_vec[:, 0:3]-y[0:3])/hr)
*gaussian_kernel((feature_vec[:, 3:5]-y[3:5])/hs)
*gaussian_kernel((feature_vec[:, 5:7]-y[5:7])/hm)
kernel_augmented = np.stack([kernel]*7, axis=-1)
return np.sum(feature_vec*kernel_augmented, axis=0) / np.sum(kernel)
각 피쳐 벡터와 이전 의 공간 모션 성분의 차이를 스케일로 나누어 가우시안 커널에
y BGR, ,
넣은 값들의 곱을 로 한다 을 피쳐의 성분 개수만큼 복사하여
kernel . kernel
텐서를 만든다 피쳐와 의 곱의 평균을 구해 반환한다
kenel_augmentd . kenel_augmented .
라) mean_shift.dist_tuple
def dist_tuple(z, v):
bgr_dist = np.linalg.norm(z[0:3]-v[0:3])
spatial_dist = np.linalg.norm(z[3:5]-v[3:5])
motion_dist = np.linalg.norm(z[5:7] - v[5:7])
return bgr_dist, spatial_dist, motion_dist
두 피쳐의 공간 모션벡터 성분의 차이를 각각 구해 튜플로 반환한다
BGR, , .
17.
- 17 -
3.결과 분석 평가
가. 알고리즘
Optical Flow(Lucas-Kande )
1) 평가 기준 이 알고리즘은 두 장의 연속 이미지 를 한 장의 이미지
: img0, img1 img0
과 그 위의 모션 벡터 으로 나타낸다 그러므로 두 장의 이미지가 가지고
motion_vec .
있던 정보량과 알고리즘이 실행된 후의 모션벡터와 가 가지고 있는 정보량을 비
img0
교하는 것이 의미가 있다 이를 위해 라는 함수를 정의하
. info_change_rate_m_vec
여 알고리즘 적용 전후의 피쳐들의 분산을 계산하였다 이때 적용 전 분산은 과
. img0
의 값의 분산의 평균으로 하였고 적용 후 분산은 과 모션벡터를 하나의
img1 BGR , img0
피쳐로 합쳐 분산을 계산하였다.
2) 조정 가능한 파라미터 이 알고리즘에서 이웃 픽셀의 모션벡터가 동일하다는 조건으
:
로부터 과결정 방정식을 유도했다 이 때 이웃 픽셀을 무엇으로 볼 것인가는 조정이
.
가능하다 즉 거리 이내인 상하좌우의 이웃과 거리
. , 1 4-
이내인 상하좌우대각선
의 이웃으로 조정이 가능하다
8- .
3) 결과 이웃으로 할 때보다 이웃으로 할 때 정보 변화량이 증가했다 이것은 적은
: 8- 4- .
이웃 픽셀을 가운데 픽셀과 모션벡터가 동일하다고 가정하는 것이 더 많은 정보를 만
들어 낼 수 있다는 것으로 해석된다 그 이유는 엄밀하게는 가운데 픽셀과 모션벡터가
.
다를 수밖에 없는 이웃 픽셀을 더 많이 같다고 가정하는 것이 결과로 나오는 모션벡터
의 형태를 비슷하게 만들어 분산을 줄이는 결과를 가져오기 때문으로 판단된다 또한
.
모션벡터의 이미지 표현에서도 적은 이웃에서 더 많은 임계값 이상의 길이를 가진 벡
터들이 이동하는 물체로부터 얻어지는 것을 확인할 수 있다.
이웃 형태 information change rate 모션 벡터 이미지 표현
이웃
4- 1.492200884162501
이웃
8- 1.2516049602173998
18.
- 18 -
나.K-means Clustering
1) 평가 기준 이 알고리즘은 이미지 의 픽셀이 가지는 피쳐를 가지고 적절하게 분
: img0
할하는 것을 목적으로 한다 이 때 적절한 분할이 무엇인가를 정의하는 것이 필요하다
. .
이것 역시 분산을 이용하여 측정이 가능하다 분할의 가장 단순한 예인 오츄 알고리즘
.
에서 이미지를 둘로 분할하는 과정에서 두 영역의 분산에 가중치를 부여하여 평균을
내서 가장 분산이 적은 분할을 선택하였다 이것을 으로 확장하
. K-means Clustering
여 여러 개의 분할이 각 중심점으로부터 가지는 분산에 가중치를 부여하여 평균을 내
어 가중 분산을 구하면 분할이 적절히 이루어졌는지 판단할 수 있다 가중 분산 을
. (WV)
수식으로 나타내면 다음과 같다.
은 이미지 전체의 픽셀 개수 은 클러스터의 개수
(n , m 는 번 클러스터의 픽셀 개수
i , 는
클러스터 내부 분산)
(는 번 클러스터의 번 픽셀의 피쳐
i j , 는 클러스터의 중심)
그러므로 가중분산은 다음과 같이 간단해진다.
이것을 안에서 계산하고 가 가지고 있던 피쳐들의 분산과의
sd_change_rate_k_means img0
비율을 구해서 반환하도록 했다.
2) 조정 가능한 파라미터 클러스터의 개수와 수렴 임계값을 조정할 수 있다 그러므로
: .
같은 클러스터 개수에 대하여 수렴 임계값을 조정하면서 가중 분산을 측정하고 다시
클러스터 개수를 늘려 임계값을 조정한다 클러스터의 개수가 개인 경우 오츄 알고리
. 2
즘과 다르지 않기 때문에 클러스터 개수를 부터 측정하고
4
꼴 로
(4, 9, 16, 25, 36)
변화시켰다 수렴 임계값은 부터 씩 곱하여 변화시켰다
. 1 2 .
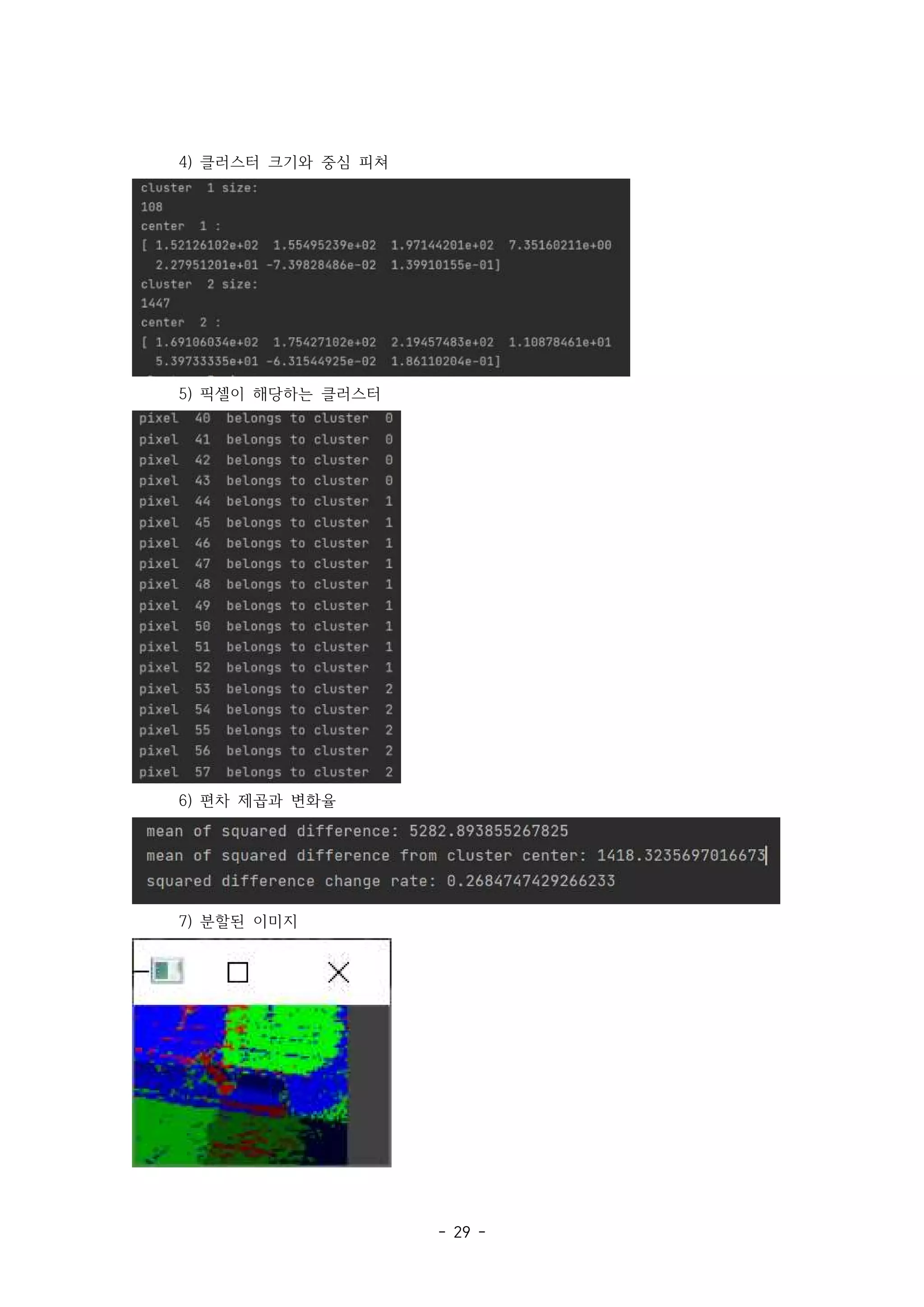
클러스터 개 수렴 임계값
9 , 1 클러스터 개 수렴 임계값
36 , 16
19.
- 19 -
3)결과 분산의 클러스터링 전후 비율은 클러스터 수가 적을수록 수렴 임계값이 클수록
: ,
컸다 이것은 클러스터 수가 많으면 클러스터 중심이 같은 피쳐 공간 안에 더 많이 분
.
포하여 클러스터에 소속되는 피쳐와의 거리가 줄어들어 분산이 작아지기 때문인 것으
로 해석된다 또한 수렴 임계값이 작을수록 분산의 변화가 거의 없을 때까지 중심점을
.
찾기 때문에 중심점이 고르게 퍼짐으로써 분산이 더 작게 나타나는 것으로 해석된다.
수렴 임계값
클러스터 수 1 2 4 8 16
4 1.0 1.0 1.0 1.0 1.0
9 0.1678 0.1678 0.1681 0.1681 0.1689
16 0.0734 0.0740 0.0761 0.0779 0.0798
25 0.0396 0.0401 0.0405 0.0475 0.0492
36 0.0279 0.0281 0.0365 0.0382 0.0382
다. Mean Shift
1) 평가 기준 이 알고리즘 역시 과 같이 이미지 의 픽셀이 가
: K-means Clustering img0
지는 피쳐를 가지고 적절하게 분할하는 것을 목적으로 한다 그러므로 분산의 변화 비
.
율을 측정한다 과 다른 점은 분할의 중심이 수렴점의 클러스터
. K-means Clustering
의 중심점이라는 것이다.
2) 조정 가능한 파라미터 공간 모션벡터 커널의 스케일 과 수렴점을
: BGR, , hr, hs, hm
구하기 위한 수렴 임계값 그리고 분할의 최소 픽셀 개수인
convergence_threshold
를 조정할 수 있다 커널 스케일은 부터 까지 배씩 증가시켰고 수렴
min_area . 16 64 2 ,
임계값 분할 최소 픽셀개수는 일 때와 일 때를 비교하였다
, 16 32 .
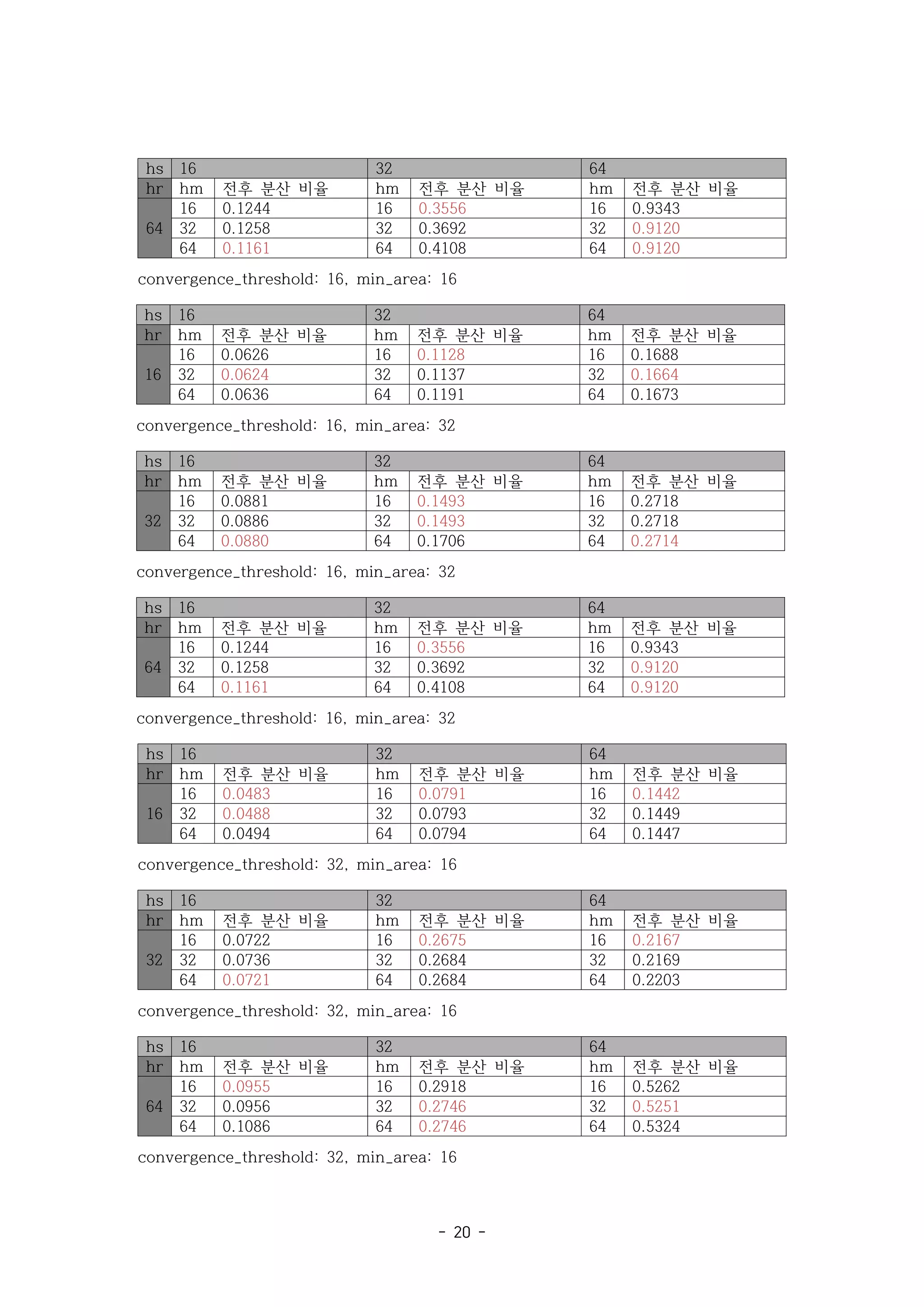
3) 결과 수렴 임계값 과 최소 픽셀수 가
: (convergence threshold, CTH) (min area, MA)
고정될 때 과 는 작을수록 알고리즘 적용 후 분산이 더 많이 줄어들었다 은
hr hs . hm
와 에 따라 분산이 변화하는 비율이 달랐다 또는
CTH MA . CTH=16, MA=16 CTH=16,
일 때는 같은 에서 에 따라 전후 분산 비율의 최소가 나타나는 값이 달
MA=32 hr hs hm
랐다 으로 작을 때나 로 매우 클 때는 이 클수록 전후 분산 비율이 작지
. hs 16 64 hm
만 가 일 때는 반대 경향이 나타났다 일 때는 전후 분산 비율
, hs 32 . CTH=32, MA=16
이 최소가 되는 의 경향성이 뚜렷하게 나타나지 않았다 에서는
hm . CTH=32, MA=32
대체로 이 작은 값에서 작은 분산 비율을 나타냈다 일 때 제외
hm (hr=64, hs=32 ).
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
16
16 0.0483 16 0.0942 16 0.167
32 0.0488 32 0.0913 32 0.162
64 0.0496 64 0.0913 64 0.163
convergence_threshold: 16, min_area: 16
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
32
16 0.0824 16 0.1481 16 0.2706
32 0.0827 32 0.1481 32 0.2706
64 0.0822 64 0.1644 64 0.2702
convergence_threshold: 16, min_area: 16
20.
- 20 -
hs16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
64
16 0.1244 16 0.3556 16 0.9343
32 0.1258 32 0.3692 32 0.9120
64 0.1161 64 0.4108 64 0.9120
convergence_threshold: 16, min_area: 16
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
16
16 0.0626 16 0.1128 16 0.1688
32 0.0624 32 0.1137 32 0.1664
64 0.0636 64 0.1191 64 0.1673
convergence_threshold: 16, min_area: 32
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
32
16 0.0881 16 0.1493 16 0.2718
32 0.0886 32 0.1493 32 0.2718
64 0.0880 64 0.1706 64 0.2714
convergence_threshold: 16, min_area: 32
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
64
16 0.1244 16 0.3556 16 0.9343
32 0.1258 32 0.3692 32 0.9120
64 0.1161 64 0.4108 64 0.9120
convergence_threshold: 16, min_area: 32
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
16
16 0.0483 16 0.0791 16 0.1442
32 0.0488 32 0.0793 32 0.1449
64 0.0494 64 0.0794 64 0.1447
convergence_threshold: 32, min_area: 16
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
32
16 0.0722 16 0.2675 16 0.2167
32 0.0736 32 0.2684 32 0.2169
64 0.0721 64 0.2684 64 0.2203
convergence_threshold: 32, min_area: 16
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
64
16 0.0955 16 0.2918 16 0.5262
32 0.0956 32 0.2746 32 0.5251
64 0.1086 64 0.2746 64 0.5324
convergence_threshold: 32, min_area: 16
21.
- 21 -
hs16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
16
16 0.0626 16 0.0952 16 0.1412
32 0.0624 32 0.0959 32 0.1441
64 0.0636 64 0.0956 64 0.1438
convergence_threshold: 32, min_area: 32
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
32
16 0.0763 16 0.2732 16 0.2507
32 0.0781 32 0.2741 32 0.2510
64 0.0768 64 0.2741 64 0.2550
convergence_threshold: 32, min_area: 32
hs 16 32 64
hr hm 전후 분산 비율 hm 전후 분산 비율 hm 전후 분산 비율
64
16 0.1095 16 0.2918 16 0.5262
32 0.1098 32 0.2746 32 0.5251
64 0.1135 64 0.2746 64 0.5324
convergence_threshold: 32, min_area: 32
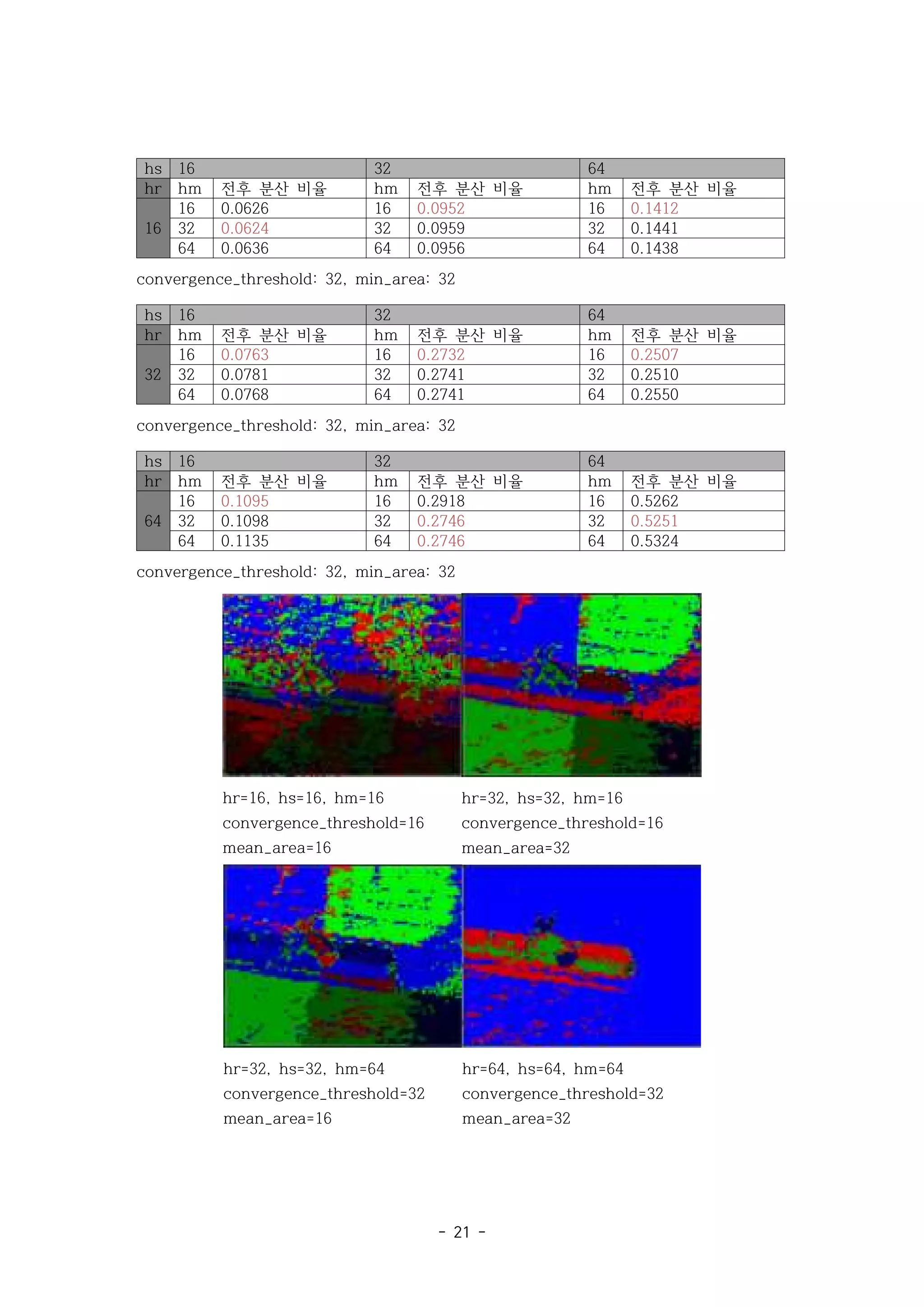
hr=16, hs=16, hm=16
convergence_threshold=16
mean_area=16
hr=32, hs=32, hm=16
convergence_threshold=16
mean_area=32
hr=32, hs=32, hm=64
convergence_threshold=32
mean_area=16
hr=64, hs=64, hm=64
convergence_threshold=32
mean_area=32
22.
- 22 -
4.코드 동작 과정
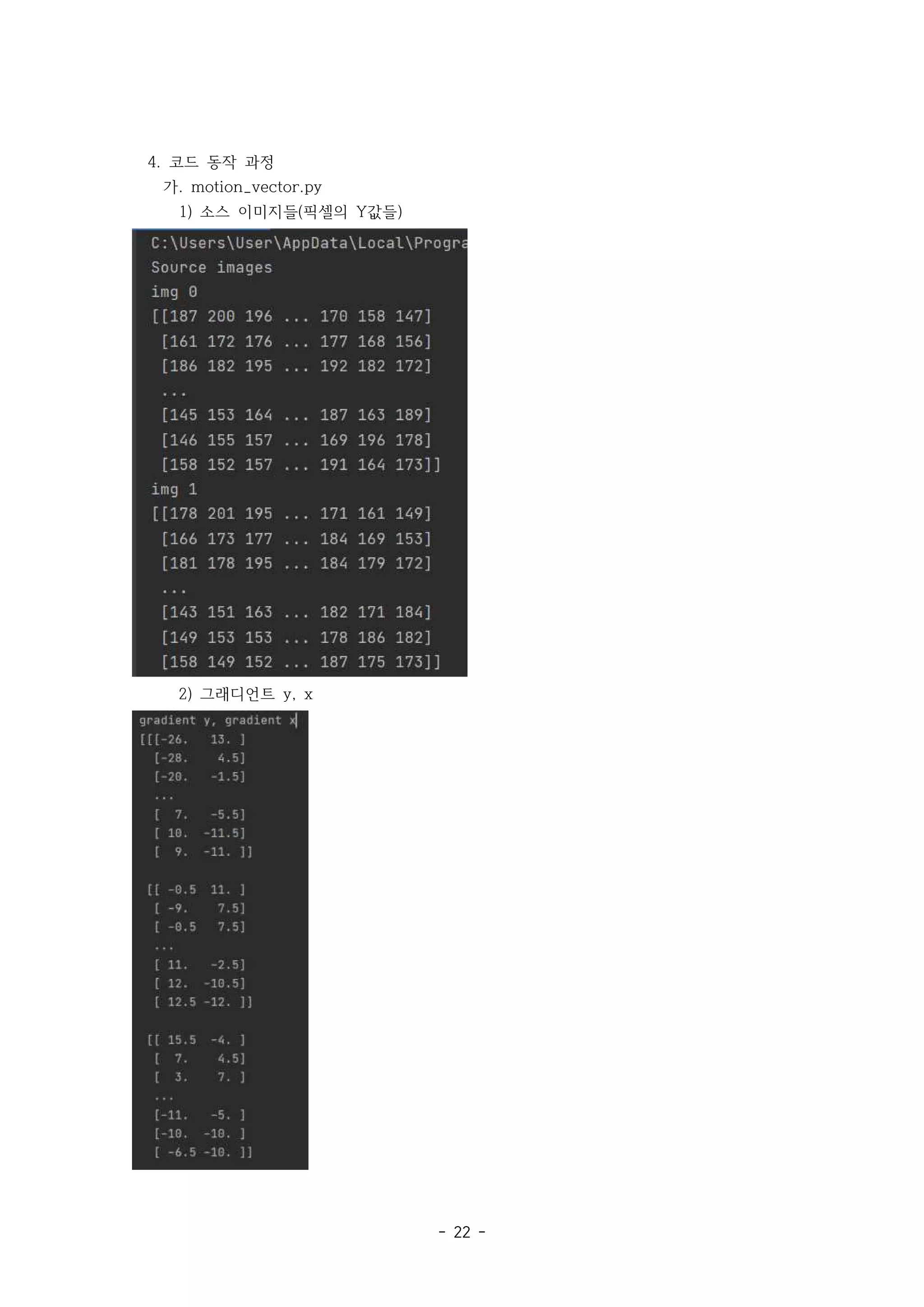
가. motion_vector.py
1) 소스 이미지들 픽셀의 값들
( Y )
2) 그래디언트 y, x


![- 5 -
4) mean_shift.py
가) mean_shift.sd_change_rate_mean_shift
나. 이론적 배경과 동작
1) Optical Flow
가) 다변수 함수의 선형근사식
고차항무시
원래 이미지 에 를 적용하여 타입에서
(img0_src, img1_src) cv2.cvtColor BGR
로 바꾼 다음 값을
YCbCr(img0, img1) Y 값으로 한다.(img0= img0[:,
:, 0]).
나) 밝기의 시간 불변성
Brightness Consistency ( )
](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-5-2048.jpg)

![- 7 -
구하고 으로 소속 중심점과의 거리 표현하는 행렬 를 구한
, np.min diff_from_cent
다 는 제곱하여 로 만들고 이것을 픽셀
. diff_from_cent squared_diff_from_cent
에 대해 평균을 내서 를 구한다 그것의 이전 반복에서의 값
mean_sd_from_cent .
과의 변화량 이 수렴임계값 이하가 되면 반복을
epsilon (convergence_threshold)
멈춘다.
다) 배정된 객체의 평균으로 새로운 중심점 계산 행렬을 조사하여 각
: belonged_to
중심점에 소속되는 픽셀들의 좌표를 로 찾는다 픽셀들의 좌표로 피쳐들
np.where .
을 구하여 를 구성하고 여기에 을 적용하여 새로운 중
belonged_features np.mean
심점 를 구한다 이것들을 각 클러스터에 대해서 모아서 텐서 를 구
temp_cent . cent
성한다.
라) 특정 조건을 만족할 때까지 나 다를 반복 이 보고서에서는 나 에서 구한 각 객체
, : )
의 해당 중심점과의 거리제곱 평균의 변화량 이 수렴 임계값 이하가 되면
epsilon
반복을 멈춘다.
4) 알고리즘
Mean Shift
가) 모든 샘플의 피쳐 벡터를 구성 영상 로 모션벡터 를
: img0_src, img1_src m_vec
구하고 영상의 값과 픽셀의 인덱스값을 여기에 시켜 텐서
BGR concatenate
를 구성한다
feature_vec .
나) 각 샘플의 수렴점 계산 초기값
(convergence point) : 은 각 샘플의 피쳐
로 놓는다 다음 점화식을 통해
feature_vec[i] . 의 수렴값을 구한다.
단, exp
≤
, , 는 각각 샘플의 공간 모션벡터 성분
BGR, ,
위 식은 에 대해 함수를 정의하고 모든
gaussian_kernel 의 공간
BGR, ,
모션벡터 성분을 입력하여 각각의 커널 값을 구한 뒤 하나로 곱하여 텐서
,
을 만든다 그것을 차원의 로 중복시킨 다음
kernel . 7 kernel_augmented
와 곱하고 합계를 구해서 분자로 만들고 다시 의 합계를 구하
feature_vec kernel
여 분모로 해서 을 구한다 프로그램 상에서는 함수로 구현했다 와
. y_next . y
의 노름이 이하이면 를 구하는 반복을
y_next L2 convergence_threshold y_next
멈추고 를 수렴값의 리스트 에 추가한다 이 과정을 모든 샘플에 대해 반
y_next v .
복한다.](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-7-2048.jpg)
![- 8 -
다) 군집화 군집화를 위해 두 개의 딕셔너리를 정의한다 클러스터를
(Clustering) : .
수집하는 와 클러스터의 중심을 수집하는 가 그것이
clusters cluster_centers
다 각 샘플이 어느 클러스터에 속하는지 기록하는 배열도 정의한
. belongs_to
다 수렴값 리스트에서 원소를 하나씩 꺼내어 각 클러스터 센터와의 공간
. BGR, ,
모션벡터의 편차를 구한다 이 계산은 이라는 함수로 정의하였다 그
. dist_tuple .
래서 모든 편차가 각 커널 스케일인 이하이면 수렴값은 그 클러스터
에 소속된다 만약 소속되는 클러스터가 없다면 새로운 클러스터를 딕셔너리에
.
추가하고 그 클러스터에 수렴값을 넣고 수렴값을 새 클러스터의 중심으로 한다.
라) 작은 분할 제거 를 탐색하여 보다 적은 샘플을 보유
: cluster_center min_area
하는 클러스터를 클러스터 중심과 가장 가까운 클러스터 중심을 가진 클러스터
,
에 병합시킨다 병합은 클러스터를 표현하는 리스트 간에 덧셈 연산을 적용한
.
다 이때 병합되는 클러스터의 모든 샘플이 소속되는 클러스터를 병합하는 클러
.
스터로 바꾼다 병합 후에는 작은 클러스터와 클러스터 센터를 삭제한다
. .
다. 코드 설명
1) 알고리즘
Optical Flow(Lucas-Kanade ) : motion_vector.py
img0_path = './dataset/hop_far/frame19.jpg'
img1_path = './dataset/hop_far/frame20.jpg'
img0_src = cv2.imread(img0_path)
img1_src = cv2.imread(img1_path)
height = len(img0_src)
width = len(img0_src[0])
m_vec = motion_vec(img0_src, img1_src)
threshold = 16
color = (255, 0, 0)
thickness = 1
이미지의 경로를 지정하고 이미지를 읽는다 이미지의 크기를 저장한다
. .
와 에 대응하는 이미지 를 입력으로 모션 벡터를 구한다 출력 가능
t t+1 img0_src, img1_src .
한 모션벡터의 최소 크기를 에 저장하고 모션 벡터의 색과 굵기를 지정한다
threshold .
for i in range(1, height-1):
for j in range(1, width-1):
if 0 <= i + m_vec[i, j, 0] < height and 0 <= j + m_vec[i, j, 1] < width:
if np.linalg.norm(m_vec[i, j]) >= threshold:
img_result = cv2.arrowedLine(img0_src, (i, j), (int(i + m_vec[i, j,
0]), int(j + m_vec[i, j, 1])), color, thickness)
모든 이미지의 픽셀 단 모션 벡터를 구할 수 없는 이미지의 경계는 제외 에 대해 모션 벡터가
( , )
이미지 상에 표현될 수 있는 끝점을 가질 때 모션 벡터의 크기가 임계값 이상이라면 이미지
,
위에 모션벡터를 화살표로 그린다.
information_change_rate = info_change_rate_m_vec(img0_src, img1_src, m_vec)
print('information change rate:', information_change_rate)
cv2.imshow('motion vector', img_result)
cv2.waitKey()
정보 변화량을 구하여 출력하고 모션벡터를 가진 이미지를 출력한다.
가) motion_vector.motion_vec
height = len(img0_src)
width = len(img0_src[0])](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-8-2048.jpg)
![- 9 -
img0 = cv2.cvtColor(img0_src, cv2.COLOR_BGR2YCR_CB)
img1 = cv2.cvtColor(img1_src, cv2.COLOR_BGR2YCR_CB)
img0 = img0[:, :, 0]
img1 = img1[:, :, 0]
img0 = np.array(img0).astype(np.float)
img1 = np.array(img1).astype(np.float)
grad_y = np.gradient(img0, axis=0)
grad_x = np.gradient(img0, axis=1)
grad = np.stack([grad_y, grad_x], axis=-1)
grad_t = np.subtract(img1, img0)
이미지의 높이와 너비를 저장한다 픽셀 값의 타입을 로 바꾸고 값만을 저장한다
. YCR_CB Y .
데이터 타입을 실수로 바꾼다 그래디언트 와 를 구한다
. y x, t .
if neighbor_type == 0:
grad_list = [
grad[:-2, :-2], grad[:-2, 1:-1], grad[:-2, 2:],
grad[1:-1, :-2], grad[1:-1, 1:-1], grad[1:-1, 2:],
grad[2:, :-2], grad[2:, 1:-1], grad[2:, 2:]
]
elif neighbor_type == 1:
grad_list = [
grad[:-2, 1:-1],
grad[1:-1, :-2], grad[1:-1, 1:-1], grad[1:-1, 2:],
grad[2:, 1:-1]
]
mat_A = np.stack(grad_list, axis=2)
이웃 타입 상하 좌우 대각선 개의 이웃 상하 좌우 개의 이웃 에 따라 과결정 방정
(0: , , 8 , 1: , 4 )
식의 행렬 에 해당하는 성분을 결정한다 픽셀의 위치에 따라 다른 행렬 를 으로
A . A np.stack
텐서로 합친다.
if neighbor_type == 0:
grad_t_list = [
grad_t[:-2, :-2], grad_t[:-2, 1:-1], grad_t[:-2, 2:],
grad_t[1:-1, :-2], grad_t[1:-1, 1:-1], grad_t[1:-1, 2:],
grad_t[2:, :-2], grad_t[2:, 1:-1], grad_t[2:, 2:]
]
elif neighbor_type == 1:
grad_t_list = [
grad_t[:-2, 1:-1],
grad_t[1:-1, :-2], grad_t[1:-1, 1:-1], grad_t[1:-1, 2:],
grad_t[2:, 1:-1]
]
vec_b = np.stack(grad_t_list, axis=2)
vec_b = -vec_b
이웃 타입 상하 좌우 대각선 개의 이웃 상하 좌우 개의 이웃 에 따라 과결정 방정
(0: , , 8 , 1: , 4 )
식의 벡터 에 해당하는 성분을 결정한다 픽셀의 위치에 따라 다른 벡터 를 으로
b . b np.stack
텐서로 합치고 부호를 바꿔준다.
m_vec_v = []
m_vec_u = []
for i in range(0, height-2):
for j in range(0, width-2):
v, u = np.linalg.lstsq(mat_A[i, j], vec_b[i, j], rcond=None)[0]
m_vec_v.append(v)
m_vec_u.append(u)
m_vec_v = np.array(m_vec_v)
m_vec_u = np.array(m_vec_u)
m_vec_v = np.reshape(m_vec_v, (height-2, width-2))
m_vec_u = np.reshape(m_vec_u, (height-2, width-2))](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-9-2048.jpg)
![- 10 -
m_vec_v = np.pad(m_vec_v, ((1, 1), (1, 1)), 'constant', constant_values=(0, 0))
m_vec_u = np.pad(m_vec_u, ((1, 1), (1, 1)), 'constant', constant_values=(0, 0))
m_vec = np.stack([m_vec_v, m_vec_u], axis=2)
return m_vec
모션 벡터의 성분 를 저장할 리스트를 만든다
v, u .
텐서 와 의 픽셀 위치에 해당하는 성분으로 과결정방정식을 구성하고
mat_A vec_b
에 대입하여 모션 벡터의 성분 를 구한다 리스트에 성분들을 저장한다
np.linalg.lstsq v, u . .
리스트를 배열로 바꾸고 이미지의 픽셀에 대응하도록 형태를 바꾼다 이미지 테두리
numpy .
에 모션벡터가 구해지지 않는 픽셀의 그래디언트를 패딩을 통해 으로 만든다 모션 벡터의
0 .
각 성분을 을 통해 하나의 순서쌍으로 합치고 반환한다
np.stack .
나) motion_vector.info_change_rate_m_vec
def info_change_rate_m_vec(img0_src, img1_src, m_vec):
feat0 = np.reshape(img0_src, (-1, 3))
feat1 = np.reshape(img1_src, (-1, 3))
new_feat = np.concatenate([img0_src, m_vec], axis=-1)
new_feat = np.reshape(new_feat, (-1, 5))
mean_feat0 = np.mean(feat0, axis=0)
mean_feat1 = np.mean(feat1, axis=0)
mean_new_feat = np.mean(new_feat, axis=0)
mean_squared_diff0 = np.mean(np.square(np.linalg.norm(feat0 -
mean_feat0)))
mean_squared_diff1 = np.mean(np.square(np.linalg.norm(feat1 -
mean_feat1)))
mean_mean_sd = (mean_squared_diff0+mean_squared_diff1)/2
mean_squared_diff_new = np.mean(np.square(np.linalg.norm(new_feat -
mean_new_feat)))
return mean_squared_diff_new/mean_mean_sd
모션 벡터를 구하기 전의 두 이미지 를 픽셀 순서로 일렬로 만들어
img0_src, img1_src
과 을 구성한다 모션벡터와 를 하여 마찬가지로 일렬로 만들어
feat0 feat1 . img0_src concat
을 구성한다 과 각각의 평균
new_feat . feat0 feat1, new_feat mean_feat0, mean_feat1,
을 구하고 각 피쳐가 평균과 이루는 거리의 평균을 제곱하여
mean_new_feat
을 구한다 그것들의 이미지 장에 대한 평균인 를
mean_squared_diff0, 1 . 2 mean_mean_sd
구한다 마찬가지로 새롭게 구성된 피쳐가 평균과 이루는 거리의 평균을 제곱하여
.
를 구한다 와 의 비율을
mean_squared_diff_new . mean_mean_sd mean_squared_diff_new
계산하여 정보량의 변화를 구하여 반환한다.
2) K-means Clustering : k_means_cluster.py
num_clusters = 16
convergence_threshold = 8
img0_path = './dataset/hop_far/frame19.jpg'
img1_path = './dataset/hop_far/frame20.jpg'
img0_src = cv2.imread(img0_path, cv2.IMREAD_COLOR)
img1_src = cv2.imread(img1_path, cv2.IMREAD_COLOR)
height = len(img0_src)
width = len(img0_src[0])
m_vec = motion_vec(img0_src, img1_src)
img_feature = np.concatenate([img0_src, m_vec], axis=2)
클러스터 개수 수렴 임계값 이미지 경로를 설정한다 이미지를 생성하고 그 높이와 너비를
, , .
저장한다 모션벡터를 추출하고 이미지의 값과 한다
. BGR concat .
square_root = int(math.sqrt(num_clusters))
cent_y = [(i+1)*height//square_root for i in range(square_root-1)]](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-10-2048.jpg)
![- 11 -
cent_x = [(i+1)*width//square_root for i in range(square_root-1)]
cent = np.stack([img_feature[i, j] for j in cent_x for i in cent_y], axis=0)
num_cents = len(cent)
초기 클러스터 중심을 설정한다 원래의 알고리즘은 순수하게 랜덤으로 설정하지만 이 보고서
.
에서는 이미지 상에서 공간적으로 클러스터 개수만큼 등분하는 점의 피쳐를 초기 클러스터 중
심으로 설정했다.
iter = -1
epsilon = 0
prev_mean_sd_from_center = 0
클러스터 중심을 변화시키는 반복을 하기 위해 제어 변수를 초기화한다 는 반복회수
. iter ,
은 평균적인 중심으로부터의 편차제곱의 차를 의미하고
epsilon prev_mean_sd_from_center
는 반복시점 직전의 중심으로부터의 편차제곱을 의미한다.
while True:
iter += 1
print('iter:', iter)
norm_mat_list = []
for i in range(num_cents):
feature_diff = img_feature - cent[i]
norm_mat_list.append(np.linalg.norm(feature_diff, axis=-1))
norm_mat = np.stack(norm_mat_list, axis=-1)
belongs_to = np.argmin(norm_mat, axis=-1)
diff_from_cent = np.min(norm_mat, axis=-1)
squared_diff_from_cent = diff_from_cent * diff_from_cent
mean_sd_from_cent = np.sum(squared_diff_from_cent) / (height * width)
if iter == 0:
epsilon = mean_sd_from_cent
else:
epsilon = abs(prev_mean_sd_from_center - mean_sd_from_cent)
if epsilon <= convergence_threshold:
break
prev_mean_sd_from_center = mean_sd_from_cent
new_cent = []
for i in range(num_cents):
y_cords, x_cords = np.where(belongs_to == iI
belonged_features = np.stack([img_feature[y_cords[i], x_cords[i]] for
i in range(len(y_cords))], axis=0)
temp_cent = np.mean(belonged_features, axis=0)
new_cent.append(temp_cent)
cent = np.stack(new_cent, axis=0)
반복횟수를 증가시키고 그것을 출력한다 각 피쳐 객체들의 각 센터와의 피쳐값의 차이를 구
.
해서 에 넣어 피쳐 거리를 구한다 이것을 으로 배열 로
np.linalg.norm . np.stack norm_mat
만든다 여기에 과 을 적용하여 객체가 속하는 클러스터와 그 클러스터의 중심과
. argmin min
의 거리 를 구한다 를 제곱하고 평균을 구하여 중심으로부터
diff_from_cent . diff_from_cent
의 평균 편차제곱 을 구한다 반복의 처음이라면 을
mean_sd_from_cent . epsilon
로 하고 아니면 이전 평균 편차제곱과 현재 평균 편차제곱의 합으로 한
mean_sd_from_cent
다 이 수렴 임계값 이하라면 반복을 멈춘다
. epsilon .
새로운 클러스터 중심을 찾기 위해 각 클러스터에 속한 객체를 로 탐색하고 그것
np.where
의 피쳐를 에 저장한다 그것에 을 적용하여 클러스터 중심을 구
beloned_features . np.mean
하고 에 저장한 뒤 배열 를 최신화한다
new_cent , cent .
img = np.zeros((3, belongs_to.shape[0], belongs_to.shape[1]))
img[0][belongs_to % 3 == 0] = (num_cents - belongs_to[belongs_to % 3 ==](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-11-2048.jpg)
![- 12 -
0])*255//num_cents
img[2][belongs_to % 3 == 1] = (num_cents - belongs_to[belongs_to % 3 ==
1])*255//num_cents
img[1][belongs_to % 3 == 2] = (num_cents - belongs_to[belongs_to % 3 ==
2])*255//num_cents
img = np.transpose(img, (1, 2, 0))
img = img.astype(np.uint8)
sd_change_rate = sd_change_rate_k_means(img_feature, cent)
cv2.imshow('segmented image', img)
cv2.waitKey()
출력할 이미지를 로 초기화한다 클러스터 번호가 의 배수인 객체의 값으로
np.zeros . 3 blue
클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈 나머지가 인 객체
. 3 1
의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈
green . 3
나머지가 인 객체의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 이미지의 형태
2 red .
를 변형하고 자료형을 변형한다 평균 편차의 변화율을 계산한 다음 결과 이미지를 출력한다
. .
가) k_means_cluster.sd_change_rate_k_means
def sd_change_rate_k_means(feat, cent):
num_cents = len(cent)
norm_mat_list = []
for i in range(num_cents):
feature_diff = feat - cent[i]
norm_mat_list.append(np.linalg.norm(feature_diff, axis=-1))
norm_mat = np.stack(norm_mat_list, axis=-1)
diff_from_cent = np.min(norm_mat, axis=-1)
squared_diff_from_cent = diff_from_cent * diff_from_cent
mean_sd_from_cent = np.mean(squared_diff_from_cent)
feat = np.reshape(feat, (-1, feat.shape[-1]))
mean_feat = np.mean(feat, axis=0)
feature_diff = feat - mean_feat
norm_arr = np.linalg.norm(feature_diff, axis=-1)
squared_diff = norm_arr*norm_arr
mean_sd = np.mean(squared_diff)
print('mean of squared difference:', mean_sd)
print('mean of squared difference from centroid:', mean_sd_from_cent)
print('squared difference change rate:', mean_sd_from_cent/mean_sd)
return mean_sd_from_cent/mean_sd
피쳐들과 클러스터 중심을 이용해 클러스터링 전후의 편차제곱 평균의 변화율을 구한다.
먼저 클러스터 개수를 저장하고 빈 거리 리스트를 만든다 클러스터 개수만큼 반복하여 각 피
.
쳐가 각 클러스터 중심과 이루는 거리를 계산하여 리스트에 저장한다 으로 리스트를
. np.stack
넘파이 배열로 만들고 으로 소속된 클러스터의 중심과의 거리 를 구한
np.min diff_from_cent
다 를 제곱하고 평균 을 구한다 다시 피쳐들 전체의 평
. diff_from_cent mean_sd_from_cent .
균 피쳐 를 구하고 각 피쳐가 평균 피쳐와 이루는 거리를 제곱하여 평균 편차제곱
mean_feat
를 구한다 와 의 비율을 구하여 반환한다
mean_sd . mean_sd_from_cent mean_sd .
3) Mean Shift : mean_shift.py
hr = 64
hs = 64
hm = 64
convergence_threshold = 32
img0_path = './dataset/hop_far/frame19.jpg'](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-12-2048.jpg)
![- 13 -
img1_path = './dataset/hop_far/frame20.jpg'
min_area = 256
img0_src = cv2.imread(img0_path, cv2.IMREAD_COLOR)
img1_src = cv2.imread(img1_path, cv2.IMREAD_COLOR)
height = len(img0_src)
width = len(img0_src[0])
coord = np.array(list(itertools.product(range(height), range(width))))
coord = np.reshape(coord, (height, width, 2))
m_vec = motion_vec(img0_src, img1_src)
feature_mat = np.concatenate([img0_src, coord, m_vec], axis=-1)
feature_vec = np.reshape(feature_mat, (height*width, 7))
커널 스케일 수렴 임계값 이미지 경로 클러스터 최소 픽셀 개수를 설정한다 이미지를 읽어
, , , .
오고 그 높이와 너비를 저장한다 이미지의 좌표를 피쳐로 만든다 모션벡터를 계산한다
. . . BGR
과 좌표 모션벡터를 하여 하나의 피쳐맵으로 만든다 피쳐맵을 하나의 열
, concat .
로 만든다
feature_vec .
print('mode seeking')
v = []
for i in range(height*width):
y = feature_vec[i]
while True:
y_n = y_next(feature_vec, y)
if np.linalg.norm(y_n-y) <= convergence_threshold:
print('pixel'+str(i)+': break')
break
y = y_n
v.append(y_n)
모드 탐색을 시작한다 모드를 저장할 빈 리스트를 만든다 피쳐 벡터 전체를 돌면서 다음을
. .
반복한다 각 피쳐 에 대하여 윈도우 안의 주변 피쳐들과의 평균을 구하여 로 한다
. y y_next . y
와 의 거리가 수렴 임계값 이하면 반복을 중단한다 그렇지 않으면 를 로 하고
y_next . y_next y
같은 과정을 반복한다 반복이 끝날 때의 를 리스트에 저장한다
. y_next .
print('clustering')
num_clusters = 0
clusters = {}
cluster_centers = {}
belongs_to = np.zeros((height*width,), dtype=np.int)
for i in range(len(v)):
print('convergence point', str(i), 'clustering')
new_cluster_flag = True
for j in range(num_clusters):
bgr_d, spatial_d, motion_d = dist_tuple(v[i], cluster_centers[j])
if bgr_d <= hr and spatial_d <= hs and motion_d <= hm:
new_cluster_flag = False
clusters[j].append(v[i])
belongs_to[i] = j
break
if new_cluster_flag:
clusters[num_clusters] = []
clusters[num_clusters].append(v[i])
cluster_centers[num_clusters] = v[i]
belongs_to[i] = num_clusters
num_clusters += 1
수렴점들의 군집화를 시작한다 클러스터의 개수 클러스터 딕셔너리 크러스터 중심 딕셔너
. , ,](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-13-2048.jpg)
![- 14 -
리 소속 클러스터 저장 배열을 초기화한다 모드 리스트의 각 수렴점에 대하여 반복문을 처
, .
리한다 새로운 클러스터를 만들어야하는지 체크하는 플래그 를 로 초
. new_cluster_flag True
기화한다 수렴점과 각 클러스터의 공간 모션 피쳐 거리를 구하는 것을 반복하면서 각
. BGR, ,
각 커널 스케일 이하면 를 로 하고 그 때의 클러스터에 수렴점을 넣는
new_cluster_flag False
다 해당 수렴점을 가진 픽셀의 소속을 그 클러스터로 하고 반복을 멈춘다
. .
가 변하지 않고 이면 딕셔너리에 새 클러스터의 빈 리스트를 만들고
new_cluster_flag True
거기에 수렴점을 넣는다 클러스터의 중심은 최초로 소속되는 수렴점으로 한다 해당 수렴점
. .
을 가진 픽셀의 소속도 그 클러스터로 한다 클러스터 전체의 개수도 증가시킨다
. .
print('small segment removal')
for i in range(num_clusters):
if i not in clusters.keys():
continue
if len(clusters[i]) < min_area:
min_dist = 10000000000000
nearest_cluster = -1
for j in range(num_clusters):
if j not in clusters.keys():
continue
if j != i
center_diff = np.linalg.norm( cluster_centers[j] -
cluster_centers[i])
if center_diff < min_dist:
min_dist = center_diff
nearest_cluster = j
for feat in clusters[i]:
belongs_to[int(feat[3])*height+int(feat[4])] = nearest_cluster
clusters[nearest_cluster] = clusters[nearest_cluster] + clusters[i]
del(clusters[i])
del(cluster_centers[i])
작은 분할을 제거하기 시작한다 모든 클러스터에 대해 반복문을 돈다 단 클러스터 번호가
. . ,
클러스터 딕셔너리의 유효한 킷값일 때만 반복한다 클러스터의 원소 개수가 최소 픽셀 개수
.
인 미만이면 최근접 클러스터 중심을 찾는다 최소 거리 를 매우 큰 값으
min_area . min_dist
로 초기화한다 모든 클러스터에 대해 반복문을 돈다 유효한 클러스터 번호에 대하여 클러스
. .
터 번호에 해당하는 클러스터의 중심과 작은 클러스터 중심과의 거리를 구하여 보다
min_dist
작으면 그것을 로 하고 최근접 클러스터를 해당 클러스터로 해서 최근접 클러스터를
min_dist
구한다 작은 클러스터에 속하는 모든 픽셀의 소속을 최근접 클러스터로 바꾸고 최근접 클러
.
스터에 작은 클러스터를 병합한다 작은 클러스터와 그 중심은 딕셔너리에서 제거한다
. .
belongs_to = np.reshape(belongs_to, (height, width))
img = np.zeros((3, belongs_to.shape[0], belongs_to.shape[1]))
img[0][belongs_to % 3 == 0] = (num_clusters - belongs_to[belongs_to % 3 ==
0])*255//num_clusters
img[2][belongs_to % 3 == 1] = (num_clusters - belongs_to[belongs_to % 3 ==
1])*255//num_clusters
img[1][belongs_to % 3 == 2] = (num_clusters - belongs_to[belongs_to % 3 ==
2])*255//num_clusters
img = np.transpose(img, (1, 2, 0))
img = img.astype(np.uint8)
sd_change_rate = sd_change_rate_mean_shift(feature_mat, cluster_centers)
cv2.imshow('segmented image', img)](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-14-2048.jpg)
![- 15 -
cv2.waitKey()
픽셀의 소속 클러스터를 나타내는 배열을 매트릭스로 바꾼다
belongs_to .
출력할 이미지를 로 초기화한다 클러스터 번호가 의 배수인 객체의 값으로
np.zeros . 3 blue
클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈 나머지가 인 객체
. 3 1
의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 클러스터 번호를 으로 나눈
green . 3
나머지가 인 객체의 값으로 클러스터 번호에 반비례하는 값을 넣어준다 이미지의 형태
2 red .
를 변형하고 자료형을 변형한다 평균 편차의 변화율을 계산한 다음 결과 이미지를 출력한다
. .
가) mean_shift.sd_change_rate_mean_shift
def sd_change_rate_mean_shift(feat, cent):
height = len(feat)
width = len(feat[0])
norm_mat_list = []
for i in cent.keys():
feature_diff = feat - feat[int(cent[i][3])][int(cent[i][4])]
norm_mat_list.append(np.linalg.norm(feature_diff, axis=-1))
norm_mat = np.stack(norm_mat_list, axis=-1)
diff_from_cent = np.min(norm_mat, axis=-1)
squared_diff_from_cent = diff_from_cent * diff_from_cent
mean_sd_from_cent = np.sum(squared_diff_from_cent)/(height*width)
feat = np.reshape(feat, (-1, feat.shape[-1]))
mean_feat = np.mean(feat, axis=0)
feature_diff = feat - mean_feat
norm_arr = np.linalg.norm(feature_diff, axis=-1)
squared_diff = norm_arr*norm_arr
mean_sd = np.mean(squared_diff)
print('mean of squared difference:', mean_sd)
print('mean of squared difference from cluster center:',
mean_sd_from_cent)
print('squared difference change rate:', mean_sd_from_cent/mean_sd)
return mean_sd_from_cent/mean_sd
피쳐들과 클러스터 중심을 이용해 클러스터링 전후의 편차제곱 평균의 변화율을 구한다.
먼저 피쳐 매트릭스의 높이 너비를 저장한다 피쳐와 클러스터 중심간의 노름을 저장할 빈
, .
리스트 를 만든다 클러스터 중심의 킷값들에 대하여 피쳐와 중심의 거리를 구
norm_mat_list .
해 에 넣는다 를 으로 텐서인 으로 만든
norm_mat_list . norm_mat_list np.stack norm_mat
다 으로 클러스터 중심으로부터의 거리인 를 구한다 이것을 제곱하고
. np.min diff_from_cent .
평균을 구하여 로 한다 피쳐 텐서를 일렬로 만든다 피쳐들의 평균
mean_sd_from_cent . .
을 구하고 각 피쳐의 평균과의 거리를 구해서 제곱하여 평균을 내서 로
mean_feat mean_sd
한다 를 출력하고 그것의 비율도 출력하고 반환한다
. mean_sd, mean_sd_from_cent .
나) mean_shift.gaussian_kernel
def gaussian_kernel(x):
norm = np.linalg.norm(x, axis=-1)
gk = np.zeros_like(norm)
gk[norm <= 1] = np.exp(-norm[norm <= 1]*norm[norm <= 1])
return gk
인수의 크기를 구하고 그것이 이하면 제곱을 해서 음수를 취하고 오일러상수의 지수로하여
1
반환한다.
다) mean_shift.y_next](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-15-2048.jpg)
![- 16 -
def y_next(feature_vec, y):
kernel = gaussian_kernel((feature_vec[:, 0:3]-y[0:3])/hr)
*gaussian_kernel((feature_vec[:, 3:5]-y[3:5])/hs)
*gaussian_kernel((feature_vec[:, 5:7]-y[5:7])/hm)
kernel_augmented = np.stack([kernel]*7, axis=-1)
return np.sum(feature_vec*kernel_augmented, axis=0) / np.sum(kernel)
각 피쳐 벡터와 이전 의 공간 모션 성분의 차이를 스케일로 나누어 가우시안 커널에
y BGR, ,
넣은 값들의 곱을 로 한다 을 피쳐의 성분 개수만큼 복사하여
kernel . kernel
텐서를 만든다 피쳐와 의 곱의 평균을 구해 반환한다
kenel_augmentd . kenel_augmented .
라) mean_shift.dist_tuple
def dist_tuple(z, v):
bgr_dist = np.linalg.norm(z[0:3]-v[0:3])
spatial_dist = np.linalg.norm(z[3:5]-v[3:5])
motion_dist = np.linalg.norm(z[5:7] - v[5:7])
return bgr_dist, spatial_dist, motion_dist
두 피쳐의 공간 모션벡터 성분의 차이를 각각 구해 튜플로 반환한다
BGR, , .](https://image.slidesharecdn.com/project-221003083723-4fe5c106/75/_project_-pdf-16-2048.jpg)










![[컴퓨터비전과 인공지능] 5. 신경망](https://cdn.slidesharecdn.com/ss_thumbnails/lec5neuralnetwork-210125014802-thumbnail.jpg?width=640&height=640&fit=bounds)


![[밑러닝] Chap06 학습관련기술들](https://cdn.slidesharecdn.com/ss_thumbnails/chap06-171119110341-thumbnail.jpg?width=640&height=640&fit=bounds)











![[KCC 2019] CNN 기반 물체 파지를 위한 위치 탐색 (CNN-based Grasping Box Detection)](https://cdn.slidesharecdn.com/ss_thumbnails/kcc2019-190701011353-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Paper Review] A Middlebury Benchmark & Context-Aware Synthesis for Video Fra...](https://cdn.slidesharecdn.com/ss_thumbnails/ctx-aware-180822041245-thumbnail.jpg?width=640&height=640&fit=bounds)








