The
Problem
• Стандартен
BigData
проблем
• Голямо
количество
документи
-‐
милиони
• Големина
на
един
документ:
10KB
–
60MB
• Пускаме
informaEon
retrieval
алгоритми
на
всеки
от
тях
• Искаме
да
можем
да
ги
обработим
в
рамките
на
няколко
часа
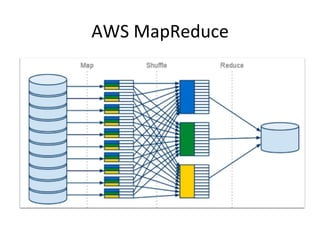
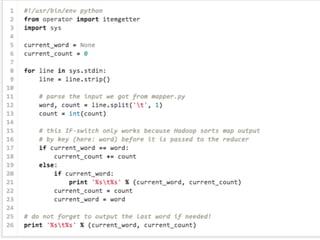
Trick
1:
Use
Streaming
Jobs
• Hadoop
е
базиран
на
Java
• Възможноста
за
прототипизиране
с
езици
като
python
и
ruby
е
много
ценна
• “Безкрайната”
паралелност
може
да
компенсира
по-‐бавната
обработка
• Много
лесна
имплементация
и
закачане
• Debugging:
може
да
се
пуска
от
CLI
Trick
2:
Skip
the
reducer
• Така
получаваме
опростен
worker
processor
• AWS
ще
се
грижи
за
сървърите
и
разпределянето
на
задачите
9.
Trick
3:
Пазим
всички
данни
в
S3
• Много
прост
key/value
storage
• Mного
евтин
• Скалира
“безкрайно”
четене
и
писане
• 99.999999999%
durable
• 99.99%
available
• High
latency
(100-‐200ms
per
request)
• Eventually
consistent
10.
Trick
4:
Instance
setup
• Не
може
да
се
ползват
custom
AMIs
• Времето
за
setup
се
заплаща
• 10
мин
setup
х
60
машини
=
10
часа
setup
• pythonbrew
и
RVM
са
вашите
приятели
• Компилиране
на
пакети
не
е
добра
идея
• Теглене
на
binary
packages
от
S3
FTW!
11.
Trick
5:
S3
paths
as
inputs
• Mapper-‐а
чете
всеки
един
URL
и
сваля
данните
от
S3
за
локална
обработка
• Накрая
запазва
резултата
обратно
в
S3
12.
Trick
6:
Always
use
compression
• S3
header
-‐
Content-‐type:
gzip
• За
текстови
данни
намалява
общия
обем
10
пъти
• CPU
Eme
is
cheaper
than
S3
storage
• Времето
за
сваляне
и
записване
на
данните
също
влиза
в
общото
време
за
обработка
• Възможност
за
ползване
на
CDN
Trick
8:
Hidden
MapReduce
Params
• Има
параметри,
които
не
са
описани
в
документацията
на
AWS!
• По
подразбиране
10
мин
Emeout
• Retry
counts,
skip
counts,
etc.
• h•p://devblog.factual.com/pracEcal-‐hadoop-‐
streaming-‐dealing-‐with-‐bri•le-‐code
15.
Trick
9:
Monitoring
• Намиране
на
необработени
документи
• Коя
версия
на
кода
е
използвана
• Използване
на
изхода
на
mapper-‐ите
за
следене
• Външен
service
–
трябва
да
скалира
добре
• Външна
база
–
може
да
е
bo•leneck
16.
Trick
10:
Индексиране
чрез
S3
• Read-‐A•er-‐Write
Consistency
• List
objects
by
prefix
• <date>_<user_id>_<session_id>
– 2012_03_15_1234_a34df5g7dr
– 2012_03_15_*
• <user_id>_<date>_<session_id>
– 1234_2012_03_a34df5g7dr
– 1234_2012_03_*
• Лимит
на
резултатите:
1000
• Latency
–
100-‐200ms
17.
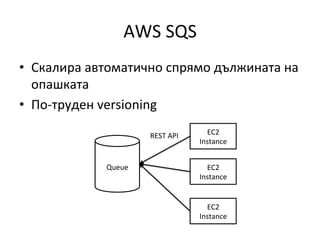
AWS
SQS
• Скалира
автоматично
спрямо
дължината
на
опашката
• По-‐труден
versioning
Queue
EC2
Instance
EC2
Instance
EC2
Instance
REST
API