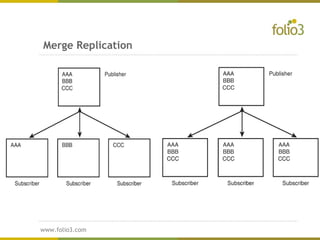
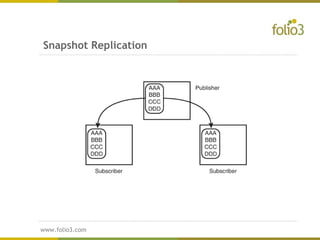
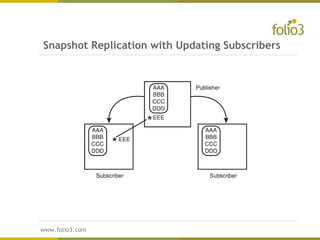
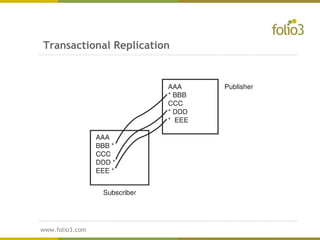
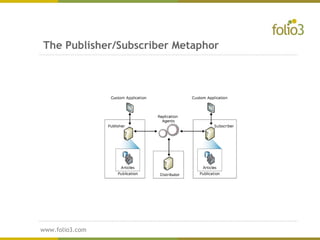
The document provides an overview of distributed databases, discussing their structure, advantages, and disadvantages, including the complexities of data allocation, fragmentation, and replication. It elaborates on the types of distributed database management systems (DDBMS) and the publisher/subscriber model for data distribution. Additionally, it addresses various replication strategies and considerations for publishing and subscribing data in distributed systems.