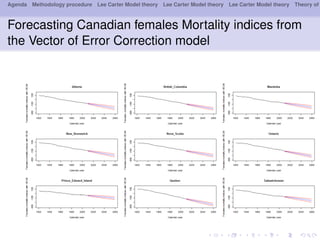
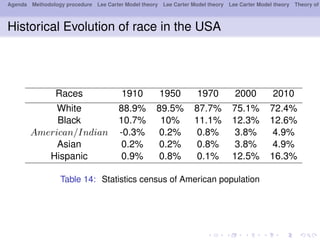
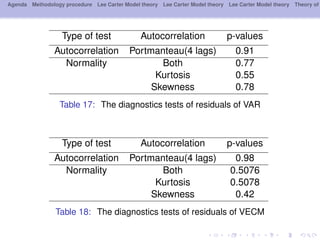
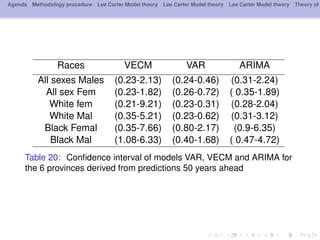
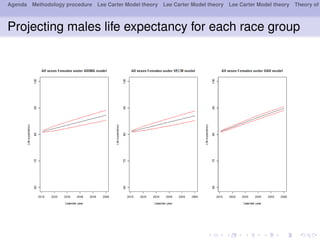
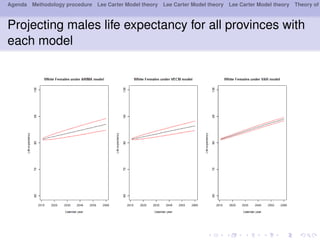
This document outlines a methodology for modeling multi-population longevity risk across Canadian provinces. It begins with a literature review on single and multi-population longevity modeling. Next, it describes retrieving Lee Carter mortality indices for 9 Canadian provinces and testing for cointegration among the indices. Finally, it discusses estimating vector autoregression and vector error correction models to forecast mortality and evaluate their ability to price annuities for different cohorts across provinces.

















































![[Actuary] actuarial mathematics and life table statistics](https://cdn.slidesharecdn.com/ss_thumbnails/actuaryactuarialmathematicsandlife-tablestatistics-120627131254-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)