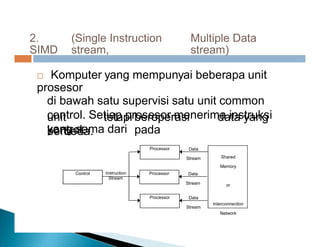
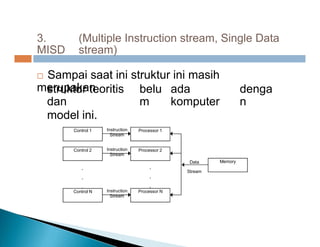
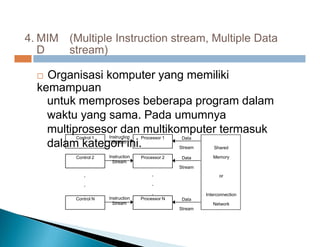
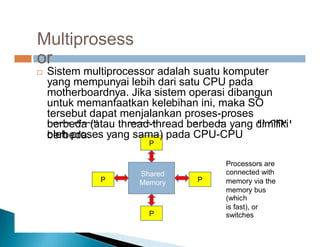
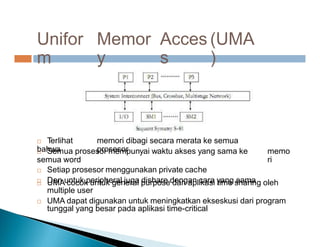
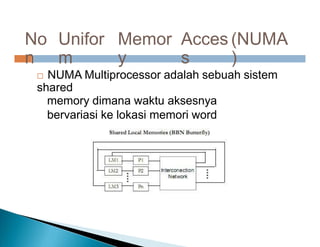
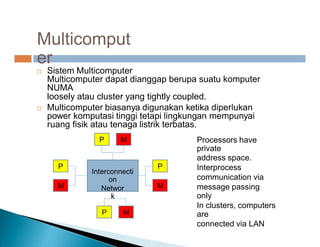
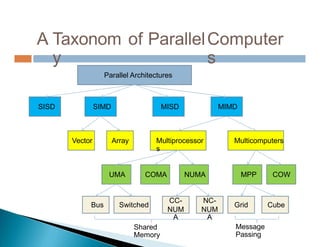
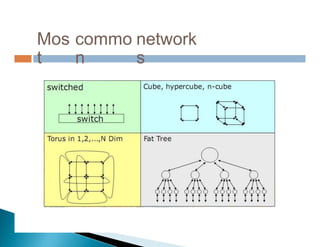
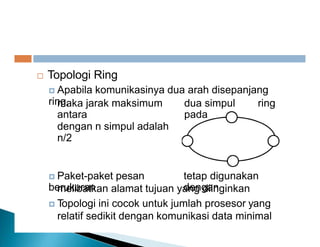
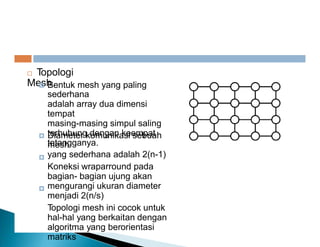
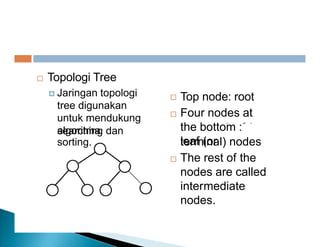
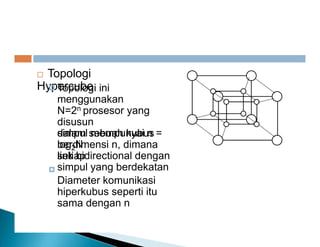
Dokumen ini membahas pemrosesan paralel untuk pengolahan data besar dan kebutuhan data yang selalu terupdate. Terdapat penjelasan tentang paradigma pengolahan paralel, klasifikasi komputer berdasarkan aliran data dan instruksi, serta model sistem memori seperti UMA, NUMA, dan COMA. Akhirnya, dibahas berbagai jaringan interkoneksi dan topologi komputer paralel, serta tantangan dalam dengan meningkatkan throughput dan biaya pemeliharaan.