2019.04.02 판도라큐브 세미나
제작자: 기획 파트 김종성
코멘트: 없음
비고: 없음
판도라큐브는 세종대학교 소프트웨어융합대학 소속의 게임 제작 동아리입니다.
매주 회의마다 게임 제작과 관련된 주제로 세미나를 개최합니다.
모든 자료는 세미나 자료 제작자의 동의 하에 업로드됩니다.
세미나의 소유 및 책임은 제작자가 지닙니다.
1.1 페이지 제목
데이터란?
3/ 14
데이터(Data)
• 어떠한 주체에 대한 사실, 관찰 등을 통해 얻은 정성적 또는 정량적 변수와 관련된 값들의 집합[1]
• 데이터 그 자체는 의미가 없는 단순한 값의 집합
• 데이터에 의미를 부여 -> 정보(information)가 됨
게임 데이터의 종류
• 유저 정보(접속 기간, 레벨, 승률, 티어, 순위 등등)
• 로그(버그/에러, 행동, 상태)
유저 Most Pick 승률(%)
1 A 51
2 B 44
3 C 21
4 A 78
5 D 39
유저 Most Pick 승률(%)
4 A 78
1 A 51
<유저 집합 - 데이터> <승률 50% 넘는 유저 – 정보>
4.
1.1 페이지 제목
데이터마이닝
4 / 14
데이터 마이닝
• 대규모로 저장된 데이터 안에서 체계적으로 통계적 규칙이나 패턴을 찾아 내는 작업[2]
• KDD(Knowledge-Discovery in Database) 라고 불리기도 함
유저 구매한 아이템
1 a, b, c, d, e
2 b, c, f, g
3 a, b, d, f
4 c, e, g
5 b, c, d ,e
(Threshold = 3)
3번 이상 나타난 패턴 {bc}, {bd}, {ce}
예시1) 빈발 패턴 마이닝
5.
1.1 페이지 제목
클러스터링
5/ 14
심슨의 역설
• 어떤 집단의 전체 통계량과 집단을 여러 개의 세부 그룹으로 나눈 후
각각의 그룹의 통계량이 반대되는 특정을 가지는 현상
클래스 시도 횟수
스테이지 클리어 비율
(CR)
A 200 53%
B 150 42%
예시2) 클래스 별 스테이지 클리어 비율
밸런스 수준 봐라 진짜
6.
1.1 페이지 제목
클러스터링
6/ 14
심슨의 역설
• 어떤 집단의 전체 통계량과 집단을 여러 개의 세부 그룹으로 나눈 후
각각의 그룹의 통계량이 반대되는 특정을 가지는 현상
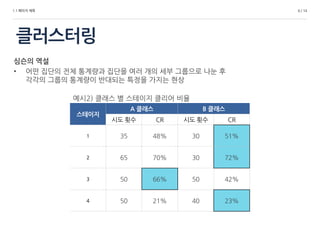
스테이지
A 클래스 B 클래스
시도 횟수 CR 시도 횟수 CR
1 35 48% 30 51%
2 65 70% 30 72%
3 50 66% 50 42%
4 50 21% 40 23%
예시2) 클래스 별 스테이지 클리어 비율
7.
1.1 페이지 제목
클러스터링
7/ 14
클러스터링(Clustering, 군집화)
• 유사한 특성을 지닌 데이터를 하나로 묶어 관리하는 기법
• 분류 기준에 따라 결과가 다른 군집화가 이루어짐
• 데이터들의 유사도를 측정해 군집화(결정 트리와 구분됨)
• 데이터 전처리 단계
<색으로 분류> <내각의 합으로 분류>
8.
1.1 페이지 제목
클러스터링
8/ 14
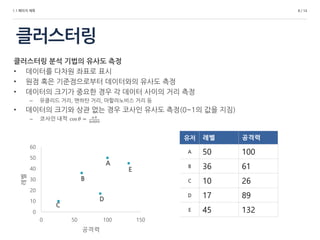
클러스터링 분석 기법의 유사도 측정
• 데이터를 다차원 좌표로 표시
• 원점 혹은 기준점으로부터 데이터와의 유사도 측정
• 데이터의 크기가 중요한 경우 각 데이터 사이의 거리 측정
– 유클리드 거리, 맨하탄 거리, 마할라노비스 거리 등
• 데이터의 크기와 상관 없는 경우 코사인 유사도 측정(0~1의 값을 지짐)
– 코사인 내적 cos 𝜃 = 𝑎∙𝑏
∥𝑎∥∥𝑏∥
유저 레벨 공격력
A 50 100
B 36 61
C 10 26
D 17 89
E 45 1320
10
20
30
40
50
60
0 50 100 150
레벨
공격력
A
B
C
D
E
9.
1.1 페이지 제목
클러스터링
9/ 14
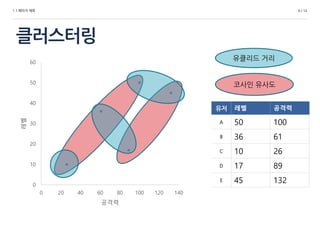
유저 레벨 공격력
A 50 100
B 36 61
C 10 26
D 17 89
E 45 1320
10
20
30
40
50
60
0 20 40 60 80 100 120 140
레벨
공격력
코사인 유사도
유클리드 거리
10.
1.1 페이지 제목
클러스터링
10/ 14
K-means 알고리즘
• K개의 기준점을 사용해 군집을 만드는 알고리즘[3]
• 기준점은 군집의 평균값
• 애매한 경우는 어떻게 하나요... =>k-median(중앙값), 밀도 기반 클러스터링, 확률 기반 클러스터링 등
A
B
C
D
A’ B’
C’
D’
E’
K = 4 K = 4
11.
1.1 페이지 제목
장단점과보완
11 / 14
클러스터링 분석 기법의 단점
• 데이터의 특질(feature)에 따라 전혀 다른 결과가 나옴
• 데이터의 분산 정도에 영향을 받음
• 환원주의 오류
– 나무를 보지 말고 숲을 보라
보완
• 데이터들 간의 관계를 분석하는 네트워크 분석 기법[4]
– Ex)연필과 다이아몬드
클러스터링 분석 기법의 장점
• 데이터를 유형화 시켜 추후에 있을 분석을 효율적으로 할 수 있음
• 전체 데이터가 아닌 대표 데이터(기준점)만 확인해 특성을 파악할 수 있음
더 자세한 내용들은
NC 공식 블로그(http://blog.ncsoft.com)의
Tech Dev 카테고리 참고
12.
감사합니다
이 문서는 나눔글꼴로작성되었습니다. 설치하기
[1] https://en.wikipedia.org/wiki/Data
[2] https://ko.wikipedia.org/wiki/데이터_마이닝
[3] gimmesilver, “군집 분석 #3”, https://brunch.co.kr/@gimmesilver/40
[4] gimmesilver, “네트워크 분석 기법을 활용한 게임 데이터 분석#1”, https://brunch.co.kr/@gimmesilver/46
Reference


![1.1 페이지 제목
데이터란?
3 / 14
데이터(Data)
• 어떠한 주체에 대한 사실, 관찰 등을 통해 얻은 정성적 또는 정량적 변수와 관련된 값들의 집합[1]
• 데이터 그 자체는 의미가 없는 단순한 값의 집합
• 데이터에 의미를 부여 -> 정보(information)가 됨
게임 데이터의 종류
• 유저 정보(접속 기간, 레벨, 승률, 티어, 순위 등등)
• 로그(버그/에러, 행동, 상태)
유저 Most Pick 승률(%)
1 A 51
2 B 44
3 C 21
4 A 78
5 D 39
유저 Most Pick 승률(%)
4 A 78
1 A 51
<유저 집합 - 데이터> <승률 50% 넘는 유저 – 정보>](https://image.slidesharecdn.com/2019-200224194805/85/PandoraCube-3-320.jpg)
![1.1 페이지 제목
데이터 마이닝
4 / 14
데이터 마이닝
• 대규모로 저장된 데이터 안에서 체계적으로 통계적 규칙이나 패턴을 찾아 내는 작업[2]
• KDD(Knowledge-Discovery in Database) 라고 불리기도 함
유저 구매한 아이템
1 a, b, c, d, e
2 b, c, f, g
3 a, b, d, f
4 c, e, g
5 b, c, d ,e
(Threshold = 3)
3번 이상 나타난 패턴 {bc}, {bd}, {ce}
예시1) 빈발 패턴 마이닝](https://image.slidesharecdn.com/2019-200224194805/85/PandoraCube-4-320.jpg)


![1.1 페이지 제목
클러스터링
10 / 14
K-means 알고리즘
• K개의 기준점을 사용해 군집을 만드는 알고리즘[3]
• 기준점은 군집의 평균값
• 애매한 경우는 어떻게 하나요... =>k-median(중앙값), 밀도 기반 클러스터링, 확률 기반 클러스터링 등
A
B
C
D
A’ B’
C’
D’
E’
K = 4 K = 4](https://image.slidesharecdn.com/2019-200224194805/85/PandoraCube-10-320.jpg)
![1.1 페이지 제목
장단점과 보완
11 / 14
클러스터링 분석 기법의 단점
• 데이터의 특질(feature)에 따라 전혀 다른 결과가 나옴
• 데이터의 분산 정도에 영향을 받음
• 환원주의 오류
– 나무를 보지 말고 숲을 보라
보완
• 데이터들 간의 관계를 분석하는 네트워크 분석 기법[4]
– Ex)연필과 다이아몬드
클러스터링 분석 기법의 장점
• 데이터를 유형화 시켜 추후에 있을 분석을 효율적으로 할 수 있음
• 전체 데이터가 아닌 대표 데이터(기준점)만 확인해 특성을 파악할 수 있음
더 자세한 내용들은
NC 공식 블로그(http://blog.ncsoft.com)의
Tech Dev 카테고리 참고](https://image.slidesharecdn.com/2019-200224194805/85/PandoraCube-11-320.jpg)
![감사합니다
이 문서는 나눔글꼴로 작성되었습니다. 설치하기
[1] https://en.wikipedia.org/wiki/Data
[2] https://ko.wikipedia.org/wiki/데이터_마이닝
[3] gimmesilver, “군집 분석 #3”, https://brunch.co.kr/@gimmesilver/40
[4] gimmesilver, “네트워크 분석 기법을 활용한 게임 데이터 분석#1”, https://brunch.co.kr/@gimmesilver/46
Reference](https://image.slidesharecdn.com/2019-200224194805/85/PandoraCube-12-320.jpg)




![[Swift] Data Structure Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/swiftdatastructureintroduction-200525090844-thumbnail.jpg?width=640&height=640&fit=bounds)











![[FAST CAMPUS] 1강 data science overview](https://cdn.slidesharecdn.com/ss_thumbnails/1datascienceoverviewprint-141124210725-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC 2011] 게임 개발자를 위한 데이터분석의 도입](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2011ver5-140313211642-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[PandoraCube] 게임에 재미요소 부여하기](https://cdn.slidesharecdn.com/ss_thumbnails/2020-200228132627-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 게임과 언어](https://cdn.slidesharecdn.com/ss_thumbnails/2020-200228132252-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PandoraCube] 쉐이더 with Unity](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228110654-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 의사소통 구현정도](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228110519-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] GOG GALAXY 2.0](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228110351-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] World of Warcraft](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228110124-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] Microsphere Interpolation](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228105930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 게임 타격감에 대하여](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228105759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 게임과 법 1](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228105137-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 게임 개발자의 수익](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228105017-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 게임 출시에 대해](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228104543-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 클라우드 게이밍](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228104046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 오토배틀러 장르 분석](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228103821-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 연쇄 할인마](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228103104-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 모션 캡쳐와 게임](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228095559-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 객체 지향 프로그래밍](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200228093211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 유니티에 광고 넣기](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200227040710-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] 이야이야이야이야기](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200224195822-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PandoraCube] '게임메이커'에 대해 알아보자](https://cdn.slidesharecdn.com/ss_thumbnails/2019-200224195404-thumbnail.jpg?width=640&height=640&fit=bounds)