

















![CouchDB Sample Document
"Subject": "I like Plankton"
"Author": "Rusty"
"PostedDate": "5/23/2006"
"Tags": ["plankton", "baseball", "decisions"]
"Body": "I decided today that I don't like baseball. I
like plankton."
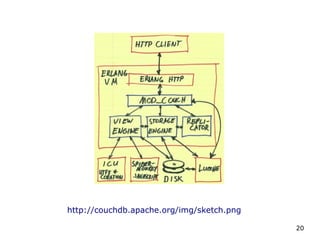
http://couchdb.apache.org/docs/intro.html
21](https://image.slidesharecdn.com/nosqltechnologies-110525093540-phpapp02/85/No-SQL-Technologies-21-320.jpg)


























This document provides an overview of NoSQL databases. It defines NoSQL and compares it to SQL databases. It discusses the history and concepts behind several popular NoSQL databases like MongoDB, Cassandra, CouchDB, HBase, Amazon SimpleDB. It also provides examples of companies that use these NoSQL databases at large scale, such as Facebook, Twitter, Netflix, Yahoo.
















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











