
Download to read offline

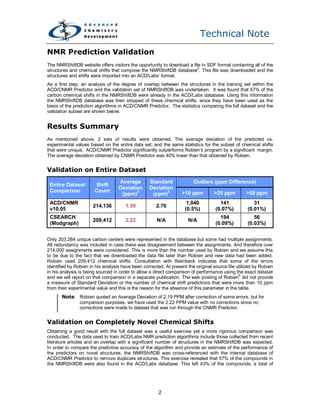

The document evaluates the performance of the ACD/CNMR predictor for NMR chemical shift prediction using the NMRShiftdb database as a validation set. The analysis shows that the ACD/CNMR predictor significantly outperforms a competing program by Robien, with an average deviation of less than 1.8 ppm compared to a larger deviation from Robien's predictions. The study highlights the importance and quality of the NMRShiftdb dataset for accurately assessing prediction algorithms.


























































![Fda Irvine Usp Eas2009 Final Ger[1] Final](https://cdn.slidesharecdn.com/ss_thumbnails/fdairvineuspeas2009finalger1final-12591545161634-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



























