CGLAB 이명규Neural 3DMesh Renderer (1/36) CGLAB 이명규
2019/06/28
신경망 기반 3D 메쉬 렌더러
Neural 3D Mesh Renderer
2.
CGLAB 이명규Neural 3DMesh Renderer (2/36)
I N D E X
01
02
03
04
05
Introduction
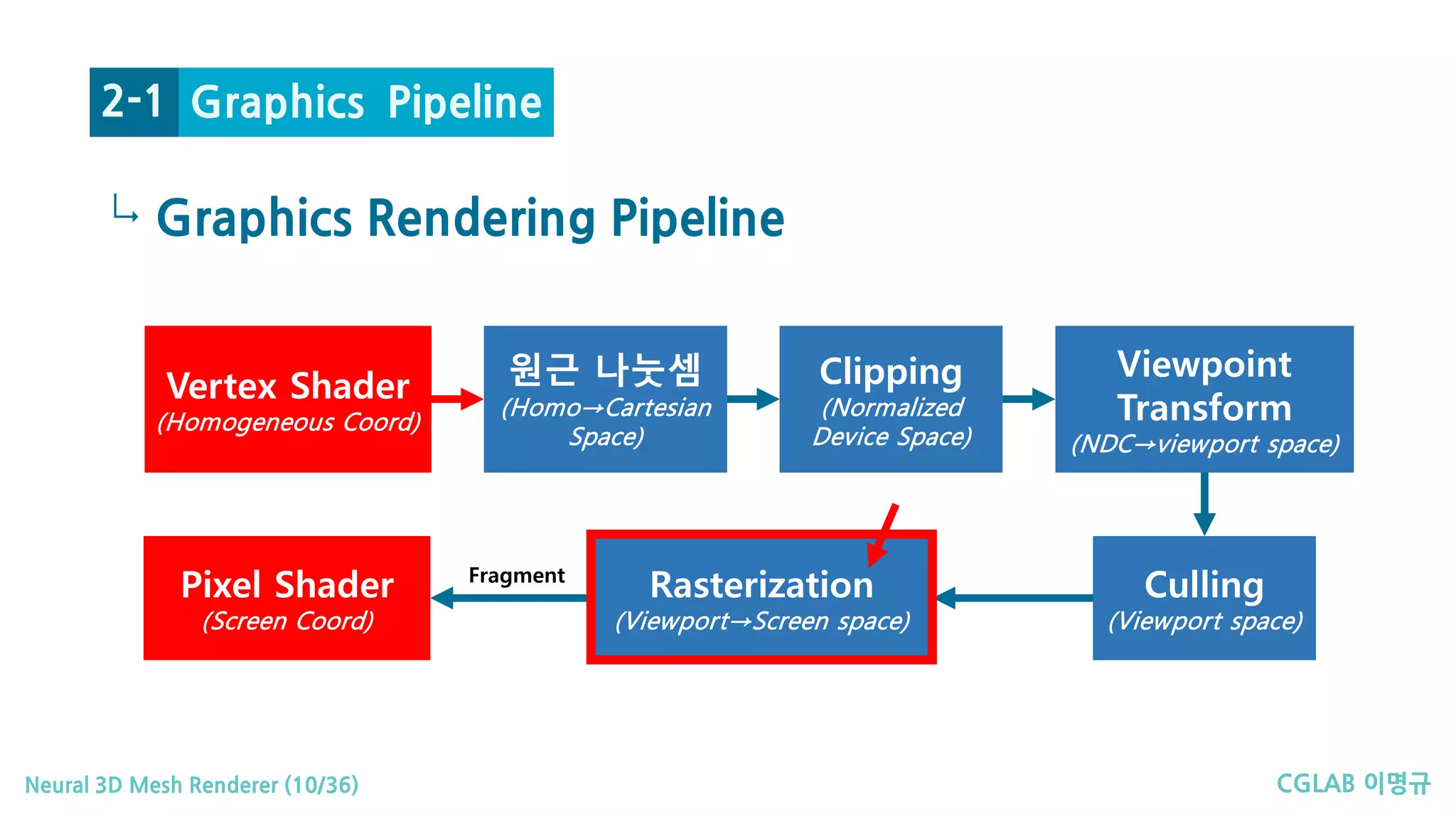
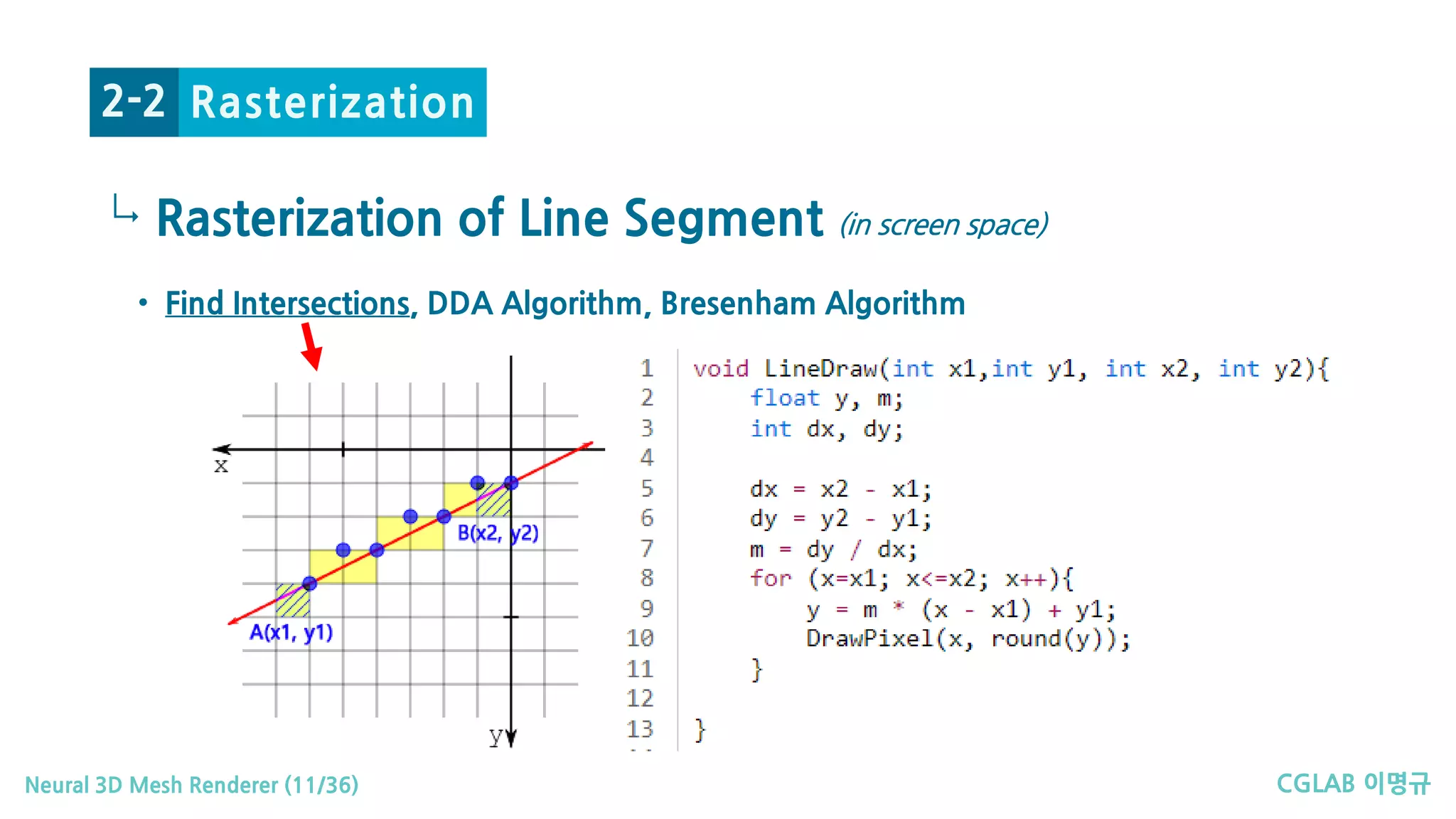
Rasterization
Proposed Method
Experiments
Conclusion
3.
CGLAB 이명규Neural 3DMesh Renderer (3/36)
Introduction
Part 01
1. 논문소개
2. 관련 연구 요약
4.
CGLAB 이명규Neural 3DMesh Renderer (4/36)
↳
논문소개1-1
• 발표 : Computer Vision and Pattern Recognition 2018
• 저자 : Hiroharu Kato et al. (University of Tokyo)
• 인용횟수 : 77회
• 래스터라이제이션 과정 때문에 2D->3D로의 미분이 불가능했던
문제를 해결하고, 세 개의 어플리케이션을 통해 증명하는 연구
저널정보 및 논문소개
5.
CGLAB 이명규Neural 3DMesh Renderer (5/36)
↳
관련 연구 요약1-2
• Rasterized form에서의 연구동향 – CNN 연산이 용이
• Voxel data는 3D CNN으로 처리 가능해 classification,
3D reconstruction & Generation에 사용됨.
• Multi-view RGB(D)이미지들은 recognition, view synthesis 연구들에 사용됨.
• Geometric form에서의 연구동향 – CNN적용이 어려워 FE*필요
• 3D mesh reconstruction을 위해 OpenGL renderer를 NN에 통합한 사례가 있음.
• Recognition, segmentation뿐만 아니라 generation 모두 어려워 제한적.
Related Works
Rasterized form Geometric form
- Voxels
- Multi-view RGB(D) Images
- Proint Clouds
- Polygon Mesh
- Sets of Primitives
CNN 연산 쉬움 CNN 어려움
*FE : Feature Engineering
6.
CGLAB 이명규Neural 3DMesh Renderer (6/36)
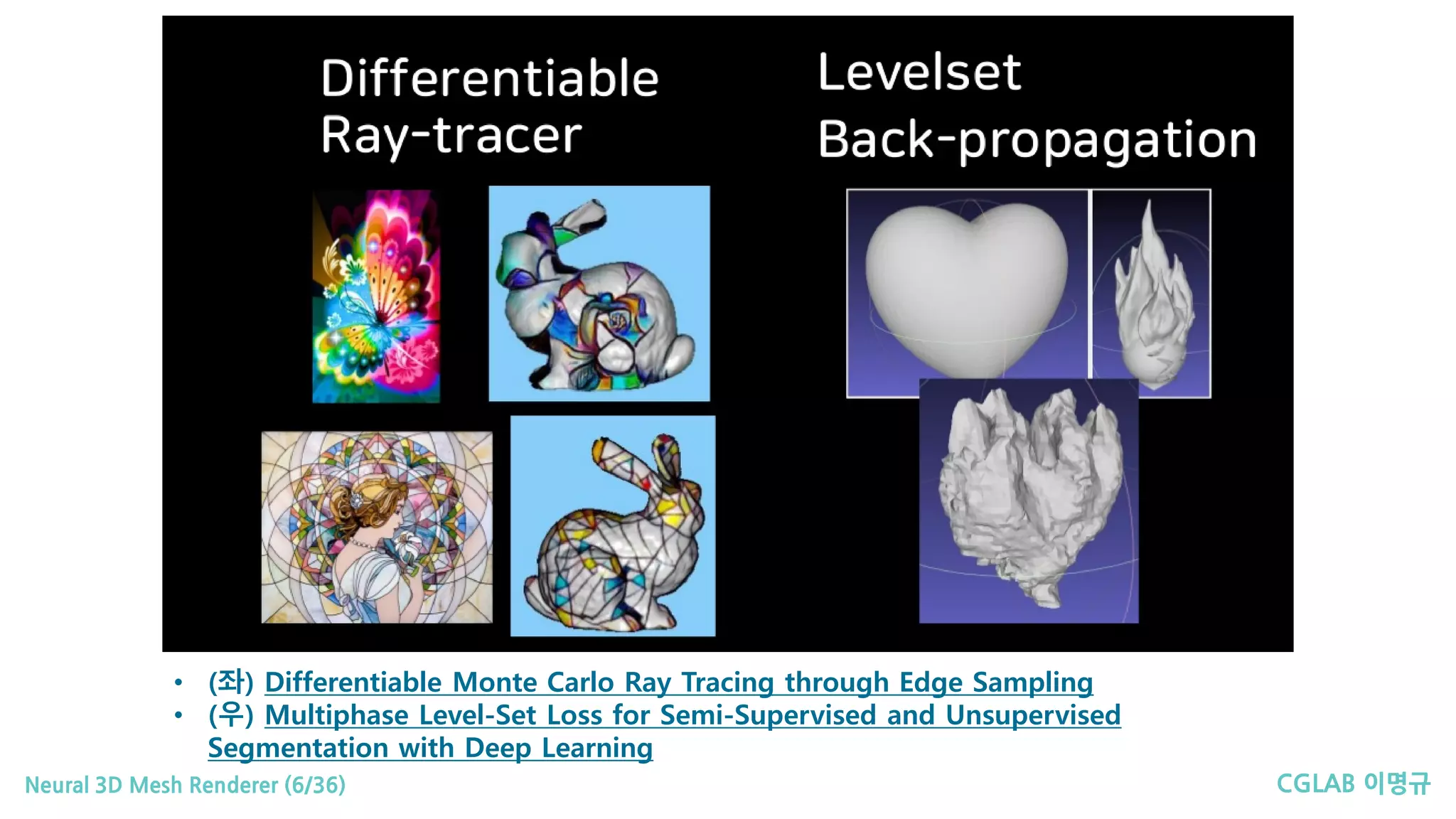
• (좌) Differentiable Monte Carlo Ray Tracing through Edge Sampling
• (우) Multiphase Level-Set Loss for Semi-Supervised and Unsupervised
Segmentation with Deep Learning
7.
CGLAB 이명규Neural 3DMesh Renderer (7/36)
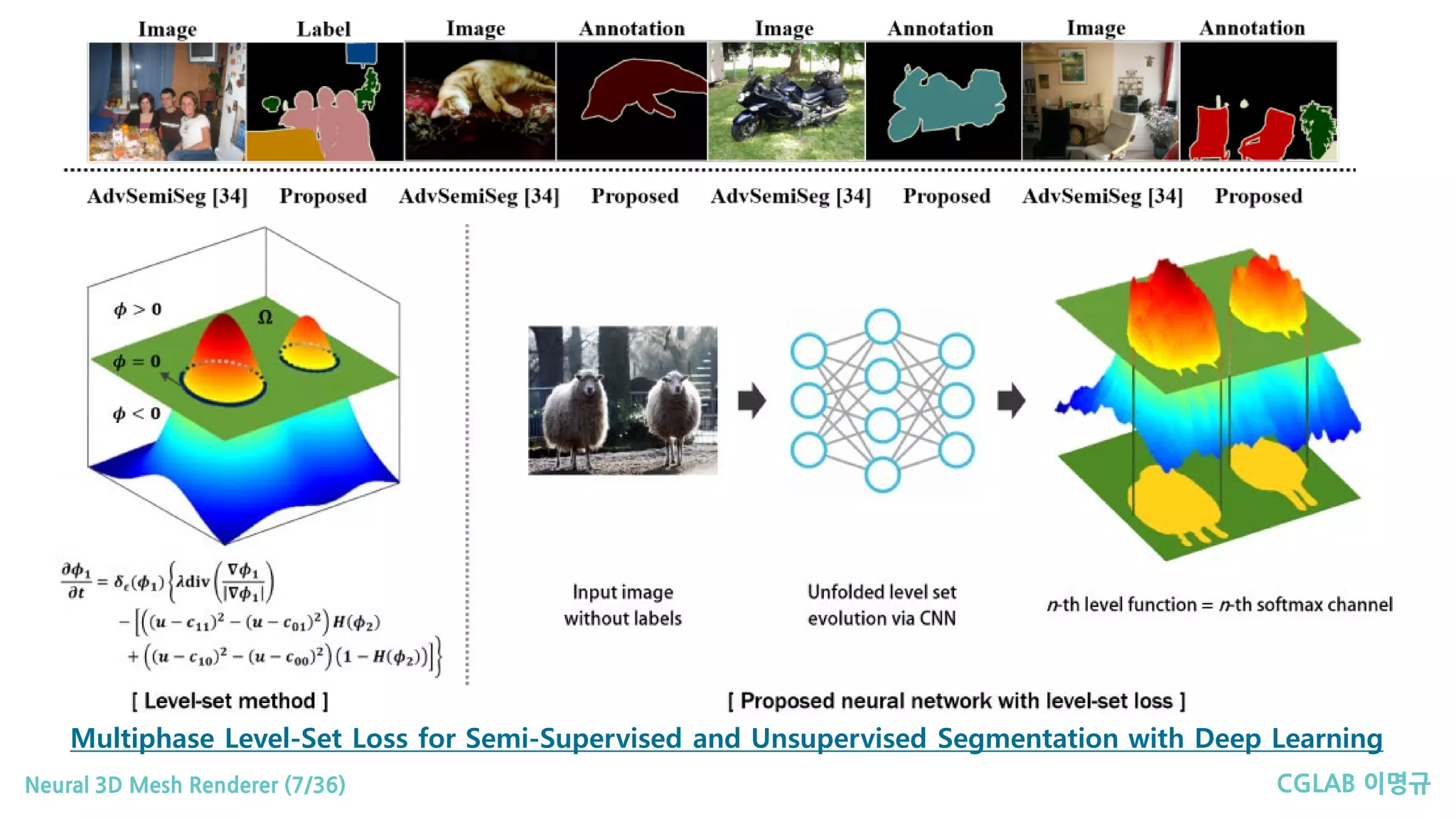
Multiphase Level-Set Loss for Semi-Supervised and Unsupervised Segmentation with Deep Learning
8.
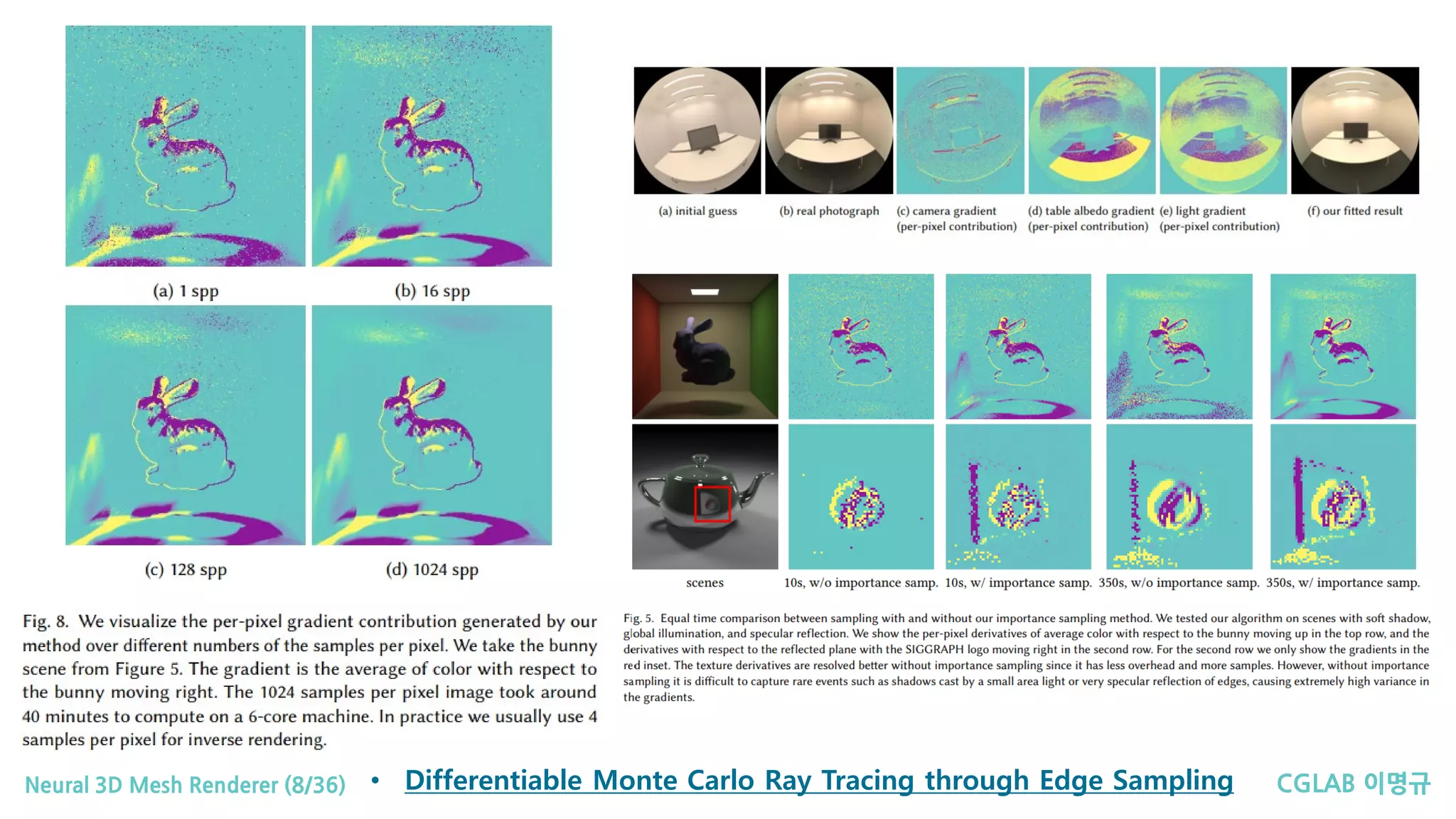
CGLAB 이명규Neural 3DMesh Renderer (8/36) • Differentiable Monte Carlo Ray Tracing through Edge Sampling
CGLAB 이명규Neural 3DMesh Renderer (17/36)
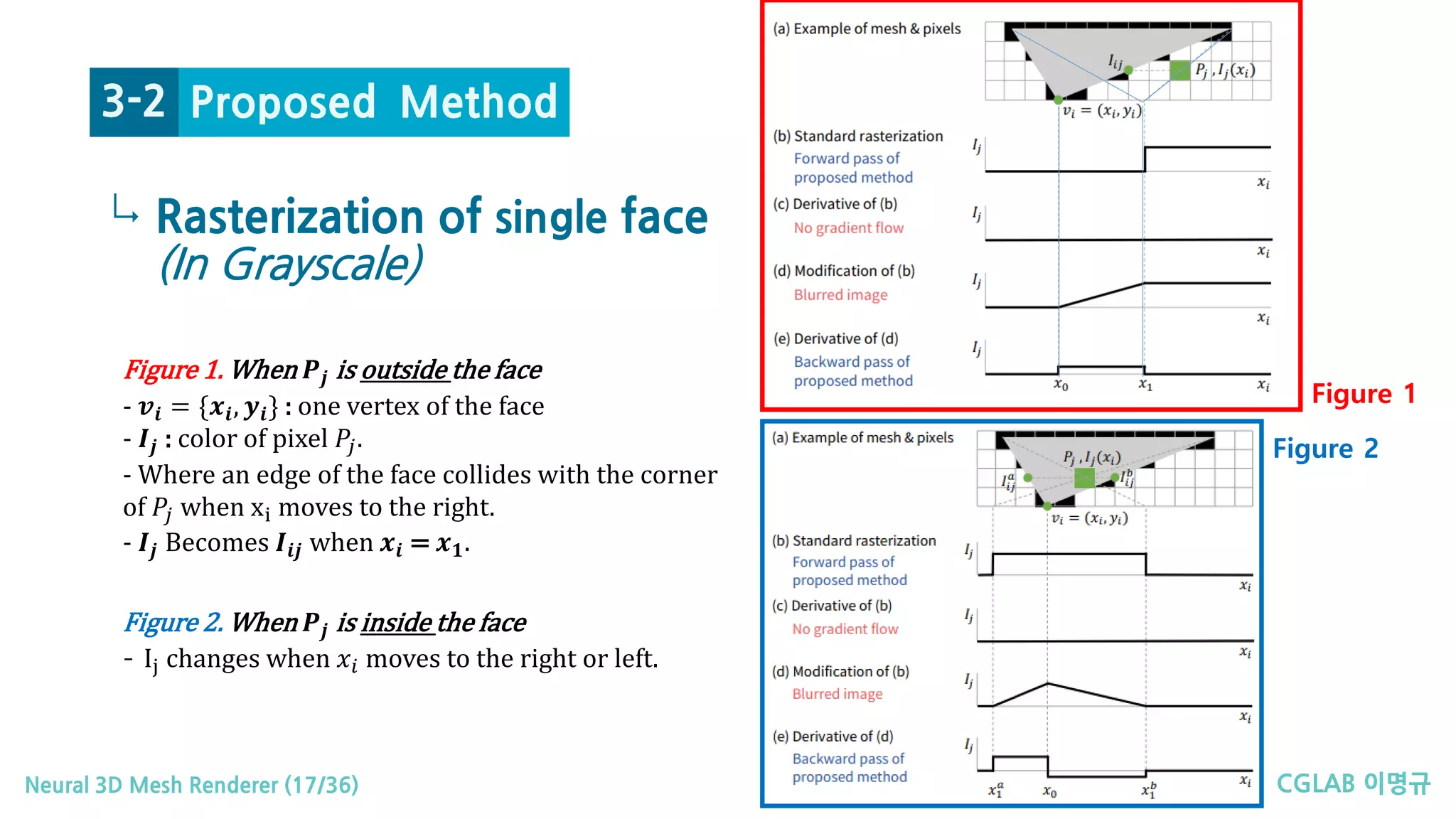
↳ Rasterization of single face
(In Grayscale)
Figure 1. When 𝑷𝑷𝒋𝒋 is outside the face
- 𝒗𝒗𝒊𝒊 = {𝒙𝒙𝒊𝒊, 𝒚𝒚𝒊𝒊} : one vertex of the face
- 𝑰𝑰𝒋𝒋 : color of pixel 𝑃𝑃𝑗𝑗.
- Where an edge of the face collides with the corner
of 𝑃𝑃𝑗𝑗 when xi moves to the right.
- 𝑰𝑰𝒋𝒋 Becomes 𝑰𝑰𝒊𝒊𝒊𝒊 when 𝒙𝒙𝒊𝒊 = 𝒙𝒙𝟏𝟏.
Figure 2. When 𝑷𝑷𝒋𝒋 is inside the face
- Ij changes when 𝑥𝑥𝑖𝑖 moves to the right or left.
Figure 1
Figure 2
Proposed Method3-2
18.
CGLAB 이명규Neural 3DMesh Renderer (18/36)
↳ 1. When 𝑷𝑷𝒋𝒋 is outside the face
Proposed Method3-2
•
𝝏𝝏𝑰𝑰𝒋𝒋(𝒙𝒙𝒊𝒊)
𝝏𝝏𝒙𝒙𝒊𝒊
=
𝑷𝑷𝒋𝒋
𝝏𝝏𝒙𝒙𝒊𝒊
= 𝟎𝟎 𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎 𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒
• 따라서 𝑰𝑰𝒋𝒋 𝒙𝒙𝟎𝟎 → 𝜹𝜹𝒋𝒋
𝑰𝑰
로 바꾸어 생각.
• 즉 𝒙𝒙𝟎𝟎과 𝒙𝒙𝟏𝟏에 선형보간 적용해 선형성 부여
(𝒙𝒙𝟎𝟎: Current position)
• 그렇다면
𝝏𝝏𝑰𝑰𝒋𝒋
𝝏𝝏𝒙𝒙𝒊𝒊
는 𝒙𝒙𝟎𝟎과 𝒙𝒙𝟏𝟏사이의
𝜹𝜹𝒋𝒋
𝑰𝑰
𝜹𝜹𝒊𝒊
𝒙𝒙(변화량)로
생각할 수 있다.
19.
CGLAB 이명규Neural 3DMesh Renderer (19/36)
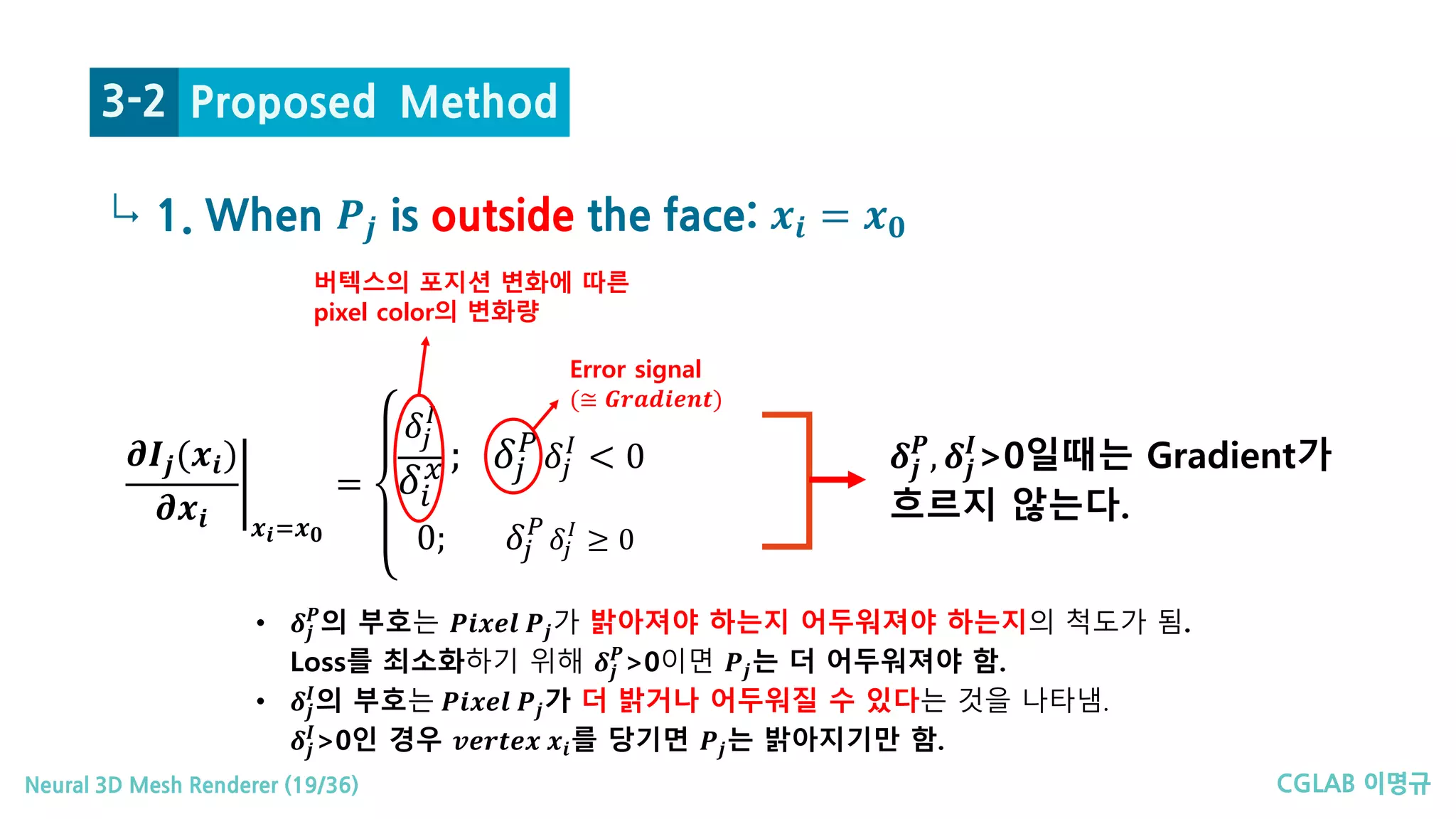
↳ 1. When 𝑷𝑷𝒋𝒋 is outside the face: 𝒙𝒙𝒊𝒊 = 𝒙𝒙𝟎𝟎
Proposed Method3-2
�
𝝏𝝏𝑰𝑰𝒋𝒋(𝒙𝒙𝒊𝒊)
𝝏𝝏𝒙𝒙𝒊𝒊 𝒙𝒙𝒊𝒊=𝒙𝒙𝟎𝟎
=
𝛿𝛿𝑗𝑗
𝐼𝐼
𝛿𝛿𝑖𝑖
𝑥𝑥 ; 𝛿𝛿𝑗𝑗
𝑃𝑃
𝛿𝛿𝑗𝑗
𝐼𝐼
< 0
0; 𝛿𝛿𝑗𝑗
𝑃𝑃
𝛿𝛿𝑗𝑗
𝐼𝐼
≥ 0
Error signal
(≅ 𝑮𝑮𝑮𝑮𝑮𝑮𝑮𝑮𝑮𝑮𝑮𝑮 𝑮𝑮𝑮𝑮)
버텍스의 포지션 변화에 따른
pixel color의 변화량
• 𝜹𝜹𝒋𝒋
𝑷𝑷
의 부호는 𝑷𝑷𝑷𝑷𝑷𝑷𝑷𝑷𝑷𝑷 𝑷𝑷𝒋𝒋가 밝아져야 하는지 어두워져야 하는지의 척도가 됨.
Loss를 최소화하기 위해 𝜹𝜹𝒋𝒋
𝑷𝑷
>0이면 𝑷𝑷𝒋𝒋는 더 어두워져야 함.
• 𝜹𝜹𝒋𝒋
𝑰𝑰
의 부호는 𝑷𝑷𝑷𝑷𝑷𝑷𝑷𝑷𝑷𝑷 𝑷𝑷𝒋𝒋가 더 밝거나 어두워질 수 있다는 것을 나타냄.
𝜹𝜹𝒋𝒋
𝑰𝑰
>0인 경우 𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗 𝒙𝒙𝒊𝒊를 당기면 𝑷𝑷𝒋𝒋는 밝아지기만 함.
𝜹𝜹𝒋𝒋
𝑷𝑷
, 𝜹𝜹𝒋𝒋
𝑰𝑰
>0일때는 Gradient가
흐르지 않는다.
CGLAB 이명규Neural 3DMesh Renderer (21/36)
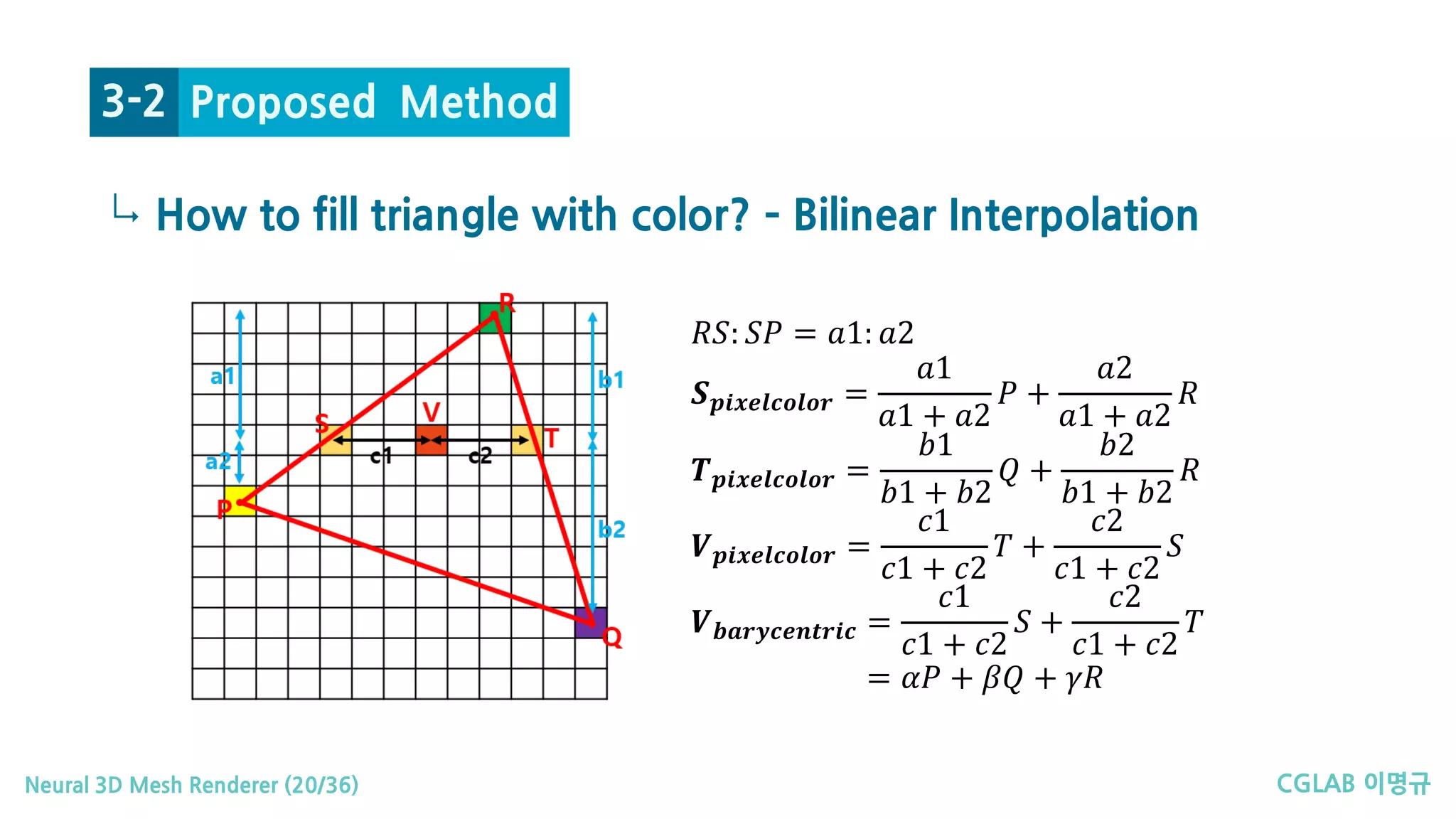
↳ 2. When 𝑷𝑷𝒋𝒋 is inside the face
Proposed Method3-2
Notations:
• 𝛿𝛿𝑗𝑗
𝐼𝐼 𝑎𝑎
= 𝐼𝐼 𝑥𝑥1
𝑎𝑎
− 𝐼𝐼 𝑥𝑥0
• 𝛿𝛿𝑗𝑗
𝐼𝐼 𝑏𝑏
= 𝐼𝐼 𝑥𝑥1
𝑏𝑏
− 𝐼𝐼 𝑥𝑥0
• 𝛿𝛿𝑥𝑥
𝑎𝑎
= 𝑥𝑥1
𝑎𝑎
− 𝑥𝑥0
• 𝛿𝛿𝑥𝑥
𝑏𝑏
= 𝑥𝑥1
𝑏𝑏
− 𝑥𝑥0
Delta of
pixel color
Delta of
𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗𝒗 𝒙𝒙𝟎𝟎 to 𝒙𝒙𝟏𝟏.
22.
CGLAB 이명규Neural 3DMesh Renderer (22/36)
↳ 2. When 𝑷𝑷𝒋𝒋 is inside the face - 𝑳𝑳𝑳𝑳𝑳𝑳𝑳𝑳 𝒇𝒇
Proposed Method3-2
23.
CGLAB 이명규Neural 3DMesh Renderer (23/36)
↳
Rasterization of multiple face
Proposed Method3-2
1. Face가 여러 개인 경우 각 픽셀에서 제일 앞에 있는 face만 그림.
(표준 래스터라이제이션 방법과 동일)
2. Backward pass(Backpropagation 등)를 지나는 동안 교차점
𝑰𝑰𝒊𝒊𝒊𝒊, 𝑰𝑰𝒊𝒊𝒊𝒊
𝒂𝒂
, 𝑰𝑰𝒊𝒊𝒊𝒊
𝒃𝒃
이 그려지는지 확인
3. 𝒗𝒗𝒊𝒊 를 포함하지 않는 surfaces로 가려지면 그래디언트가 흐르지 않음.
24.
CGLAB 이명규Neural 3DMesh Renderer (24/36)
↳
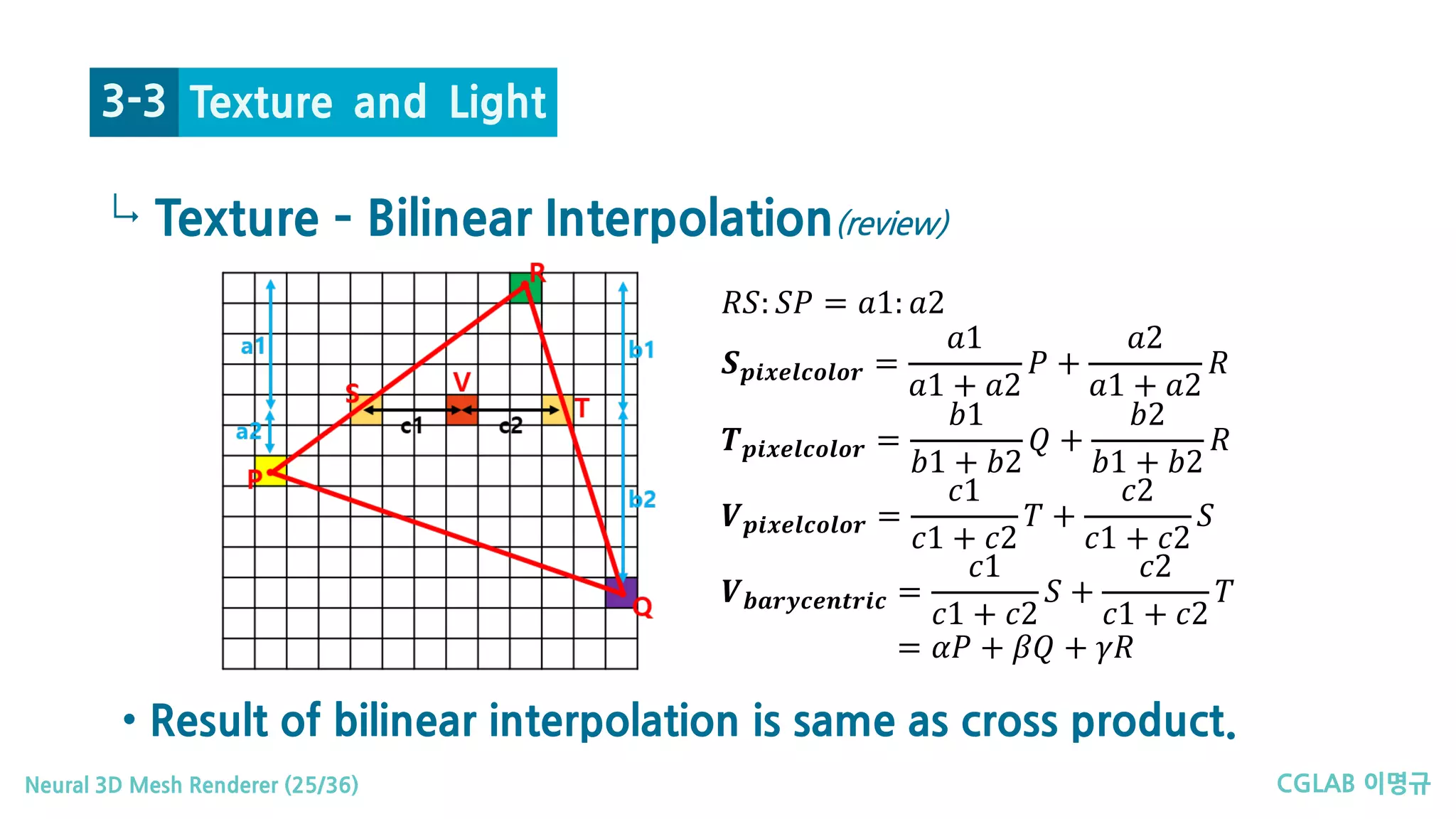
Texture and Light3-3
• Each face has its own texture image of size 𝒔𝒔𝒕𝒕 × 𝒔𝒔𝒕𝒕 × 𝒔𝒔𝒕𝒕.
• Centroid 좌표계를 통해 𝒑𝒑 위치에 해당하는 텍스쳐 공간에서의 좌표 결정
• 𝒑𝒑𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩𝑩 = 𝒘𝒘𝟏𝟏 𝒗𝒗𝟏𝟏 + 𝒘𝒘𝟐𝟐 𝒗𝒗𝟐𝟐 + 𝒘𝒘𝟑𝟑 𝒗𝒗𝟑𝟑
• (𝒘𝒘𝟏𝟏, 𝒘𝒘𝟐𝟐, 𝒘𝒘𝟑𝟑) is the corresponding coordinate in texture space.
Texture
CGLAB 이명규Neural 3DMesh Renderer (27/36)
↳
Texture and Light3-3
• Rasterization 중 Sampling으로 인한
gradient flow 끊김이 핵심 문제
• 선형 결합으로 표현 가능한 Texture, Light는
Gradient flow에 큰 방해가 되지 않는다.
Conclusion of part 3
28.
CGLAB 이명규Neural 3DMesh Renderer (28/36)
Experiments
Part 04
1. Applications
29.
CGLAB 이명규Neural 3DMesh Renderer (29/36)
↳
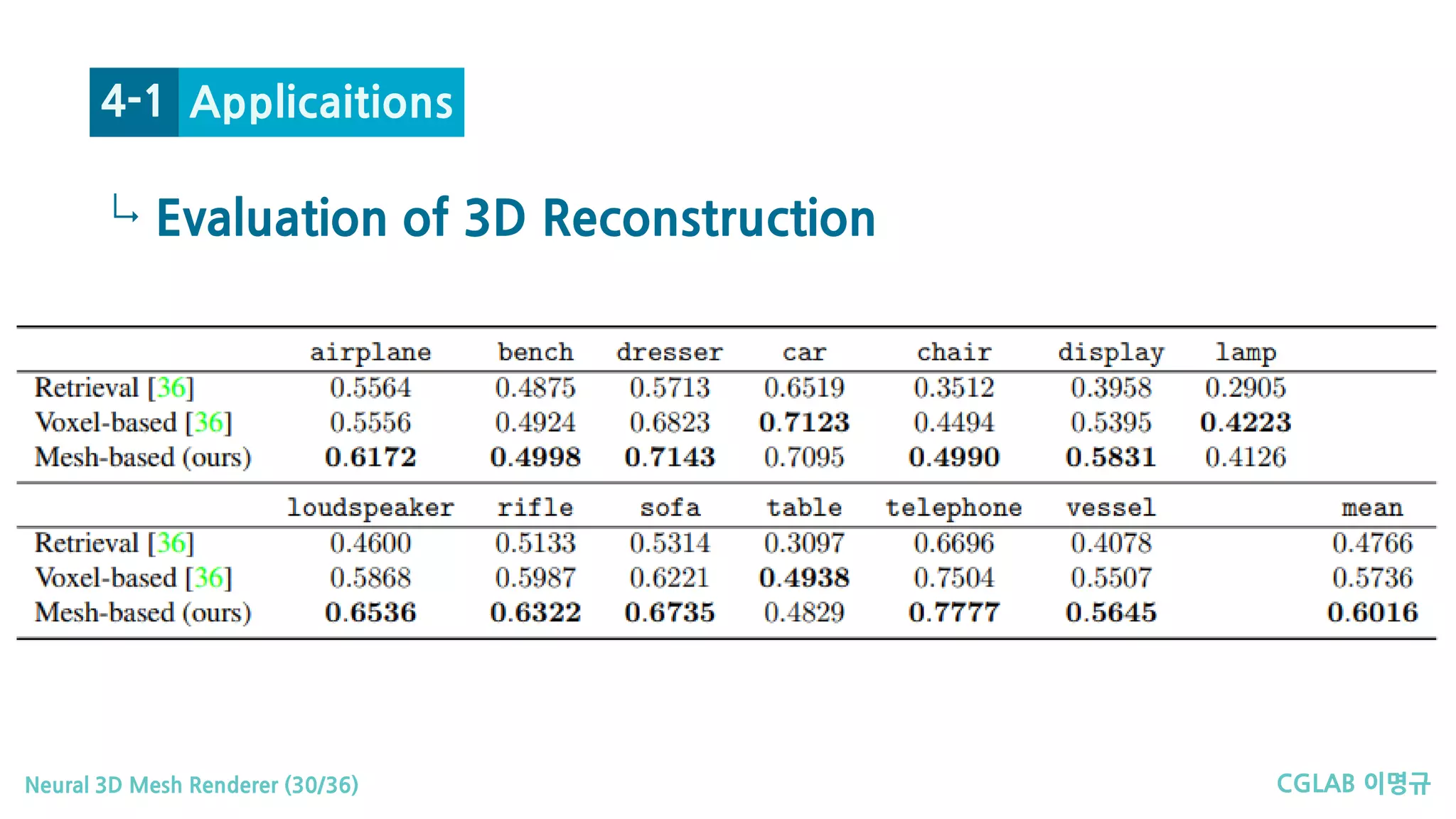
Applicaitions4-1
1. 3D Reconstruction
30.
CGLAB 이명규Neural 3DMesh Renderer (30/36)
↳
Applicaitions4-1
Evaluation of 3D Reconstruction
31.
CGLAB 이명규Neural 3DMesh Renderer (31/36)
↳
Applicaitions4-1
2. 2D-to-3D Style Transfer
• Transfer 2D style-
loss to 3D Mesh
32.
CGLAB 이명규Neural 3DMesh Renderer (32/36)
↳
Applicaitions4-1
3. DeepDream of 3D Mesh
CGLAB 이명규Neural 3DMesh Renderer (34/36)
↳
Conclusion5-2
• 3D Mesh까지 Gradient를 전달하기 위한 approximated gradient
기법을 제안함으로서 Rendering과 신경망을 통합
• 다양한 어플리케이션을 제안
• 3D reconstruction에 저자들의 아이디어를 차용함으로서 기존 Voxel 기반
접근법보다 시각적 및 Voxel IoU metric 측면에서 우수성을 보임.
• 2D Image의 loss와 GD를 이용해 3D mesh의 정점, 텍스쳐를 편집 가능.
• 아티스트들에게 새로운 영감을 줄 수 있음.
요약
35.
CGLAB 이명규Neural 3DMesh Renderer (35/36)
↳
Limitations5-2
• In general
• 래스터라이제이션 렌더링 방식처럼, 하이폴리곤 메쉬의 역전파에서는
다소 시간이 오래 걸릴 수 있다.
• 아직 다양한 3D graphics 효과들을 적용하기에는 큰 무리가 있다.
• In 3D Reconstruction Application
• 다양한 토폴로지로 모델을 생성할 수 없다.
(네트워크가 vertices-Faces간의 관계를 모르므로 복잡한 토폴로지를 갖는 모델 생성 불가능.)
본 논문의 한계
36.
CGLAB 이명규Neural 3DMesh Renderer (36/36)
Thank you for Listening.
Email : brstar96@naver.com (or brstar96@soongsil.ac.kr)
Mobile : +82-10-8234-3179




























![2017 12 09_데브루키_리얼타임 렌더링_입문편(3차원 그래픽스[저자 : 한정현] 참조)](https://cdn.slidesharecdn.com/ss_thumbnails/20171209-171227014347-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GEG1] 3.volumetric representation of virtual environments](https://cdn.slidesharecdn.com/ss_thumbnails/geg13-volumetricrepresentationofvirtualenvironments-111030115748-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Kgc2013] 모바일 엔진 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2013-130929065039-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Shader study] the rendering technology of lords of the fallen - 발표메모(14.06.23)](https://cdn.slidesharecdn.com/ss_thumbnails/shaderstudytherenderingtechnologyoflordsofthefallen-14-140728052906-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IGC2018] 퍼니파우 최재영 - 감성을 위한 개발요소](https://cdn.slidesharecdn.com/ss_thumbnails/2-181023020204-thumbnail.jpg?width=640&height=640&fit=bounds)

![[1106 조진현] if you( batch rendering )](https://cdn.slidesharecdn.com/ss_thumbnails/1106ifyoubatchrendering-101108015106-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 5 - Others](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture5others-210215060452-thumbnail.jpg?width=640&height=640&fit=bounds)

















