The document discusses the importance of model validation in machine learning, emphasizing that it is a vital step in ensuring the reliability and accuracy of AI models. It highlights various validation techniques and methods, including in-time and out-of-time validations, and explains the necessity of adapting techniques to different types of models, such as supervised, unsupervised, and deep learning. Proper validation is depicted as essential for optimizing model performance and preventing issues like overfitting, thereby crucial for successful data-driven decision-making in various sectors.
















![19/23
The schema will be parsed by utilizing the text_format function from the google.protobuf
library, which transforms the protobuf message into a textual format, along with TensorFlow’s
schema_pb2.
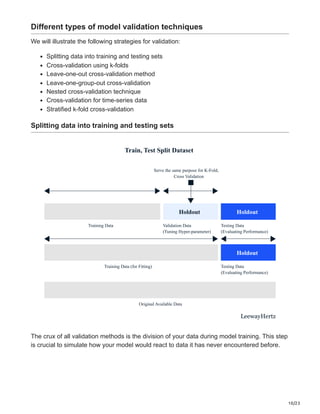
Using the schema to create TFRecords
The subsequent step involves providing TFMA with access to the dataset. To accomplish
this, a TFRecords file must be established. Utilizing the existing schema to do this is
advantageous because it ensures each feature is assigned the accurate type.
import csv
datafile = os.path.join(DATA_DIR, 'eval', 'data.csv')
reader = csv.DictReader(open(datafile, 'r'))
examples = []
for line in reader:
example = example_pb2.Example()
for feature in schema.feature:
key = feature.name
if feature.type == schema_pb2.FLOAT:
example.features.feature[key].float_list.value[:] = (
[float(line[key])] if len(line[key]) > 0 else [])
elif feature.type == schema_pb2.INT:
example.features.feature[key].int64_list.value[:] = (
[int(line[key])] if len(line[key]) > 0 else [])
elif feature.type == schema_pb2.BYTES:
example.features.feature[key].bytes_list.value[:] = (
[line[key].encode('utf8')] if len(line[key]) > 0 else [])
# Add a new column 'big_tipper' that indicates if the tip was > 20% of the fare.
# TODO(b/157064428): Remove after label transformation is supported for Keras.
big_tipper = float(line['tips']) > float(line['fare']) * 0.2
example.features.feature['big_tipper'].float_list.value[:] = [big_tipper]
examples.append(example)
tfrecord_file = os.path.join(BASE_DIR, 'train_data.rio')
with tf.io.TFRecordWriter(tfrecord_file) as writer:
for example in examples:
writer.write(example.SerializeToString())
!ls {tfrecord_file}
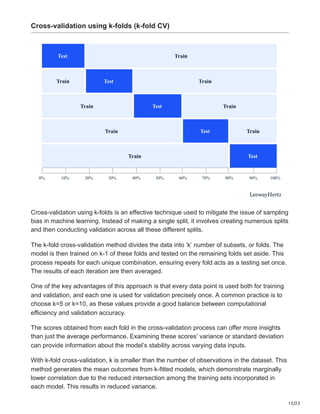
It is important to highlight that TFMA supports various model types, such as TF Keras
models, models built on generic TF2 signature APIs, and TF estimator-based models.
Here we will explore how we to configure a Keras-based model.
In configuring the Keras model, the metrics and plots will be manually integrated as part of
the setup process.
Set up and run TFMA using Keras
Import tfma using the below code](https://image.slidesharecdn.com/modelvalidationtechniquesinmachinelearning-231127115124-86cb1784/85/Model-validation-techniques-in-machine-learning-pdf-19-320.jpg)
![20/23
import tensorflow_model_analysis as tfma
You will need to call and use the previously imported instance of TensorFlow Model Analysis
(TFMA).
# You will setup tfma.EvalConfig settings
keras_eval_config = text_format.Parse("""
## Model information
model_specs {
# For keras (and serving models) we need to add a `label_key`.
label_key: "big_tipper"
}
## You will post training metric information. These will be merged with any built-in
## metrics from training.
metrics_specs {
metrics { class_name: "ExampleCount" }
metrics { class_name: "BinaryAccuracy" }
metrics { class_name: "BinaryCrossentropy" }
metrics { class_name: "AUC" }
metrics { class_name: "AUCPrecisionRecall" }
metrics { class_name: "Precision" }
metrics { class_name: "Recall" }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
metrics { class_name: "Calibration" }
metrics { class_name: "CalibrationPlot" }
metrics { class_name: "ConfusionMatrixPlot" }
# ... add additional metrics and plots ...
}
## You will slice the information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["trip_start_hour"]
}
slicing_specs {
feature_keys: ["trip_start_day"]
}
slicing_specs {
feature_values: {
key: "trip_start_month"
value: "1"
}
}
slicing_specs {
feature_keys: ["trip_start_hour", "trip_start_day"]
}
""", tfma.EvalConfig())
It’s crucial to establish a TensorFlow Model Analysis (TFMA) EvalSharedModel that
references the Keras model.](https://image.slidesharecdn.com/modelvalidationtechniquesinmachinelearning-231127115124-86cb1784/85/Model-validation-techniques-in-machine-learning-pdf-20-320.jpg)

![22/23
output_paths = []
for i in range(3):
# Create a tfma.EvalSharedModel that points to our saved model.
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=os.path.join(MODELS_DIR, 'keras', str(i)),
eval_config=keras_eval_config)
output_path = os.path.join(OUTPUT_DIR, 'time_series', str(i))
output_paths.append(output_path)
# Run TFMA
tfma.run_model_analysis(eval_shared_model=eval_shared_model,
eval_config=keras_eval_config,
data_location=tfrecord_file,
output_path=output_path)
eval_results_from_disk = tfma.load_eval_results(output_paths[:2])
tfma.view.render_time_series(eval_results_from_disk)
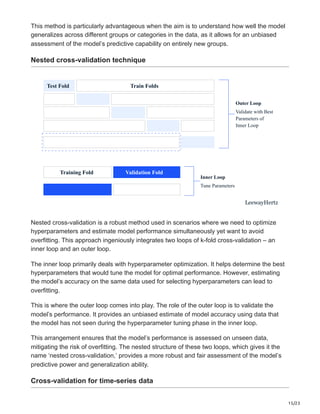
With TensorFlow Model Analysis (TFMA), it’s possible to assess and verify machine learning
models across various data segments. This provides the ability to comprehend the
performance of models across different data conditions and scenarios
Challenges in ML model validation
Data density: With the advancement of new ML and AI techniques, there is a growing
need for large, diverse, and detailed datasets to build effective models. This data can
also often be less structured, which makes validation challenging. Thus, developing
innovative tools becomes essential for data integrity and suitability checks.
Theoretical clarity: A major challenge in the ML/AI domain lies in understanding its
methodologies. They are not as comprehensively grasped by practitioners as more
traditional techniques. This lack of understanding extends to the specifics of a certain
method and how well-suited a procedure is for a given modeling scenario. This makes
it harder for model developers to substantiate the appropriateness of the theoretical
framework in a specific modeling or business context.
Model documentation and coding: An integral part of model validation is evaluating
the extent and completeness of the model documentation. The ideal documentation
would be exhaustive and standalone, enabling third-party reviewers to recreate the
model without accessing the model code. This level of detail is challenging even with
standard modeling techniques and even more so in the context of ML/AI, making model
validation a demanding task.](https://image.slidesharecdn.com/modelvalidationtechniquesinmachinelearning-231127115124-86cb1784/85/Model-validation-techniques-in-machine-learning-pdf-22-320.jpg)















































































