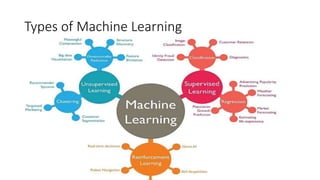
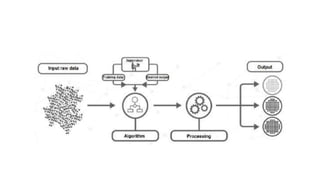
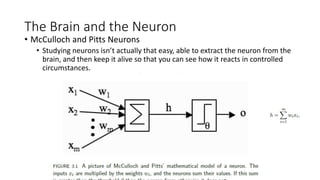
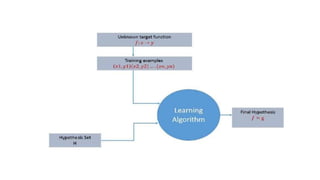
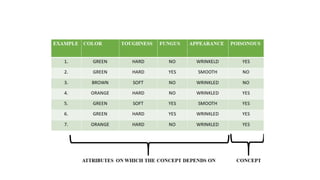
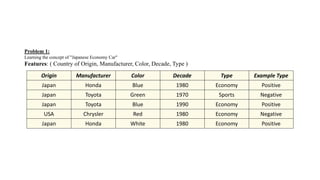
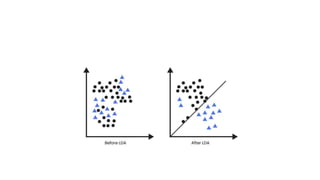
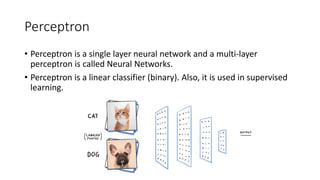
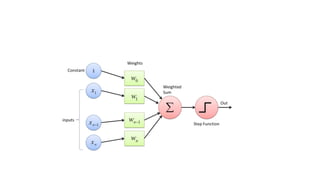
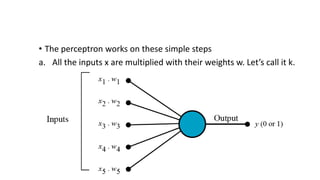
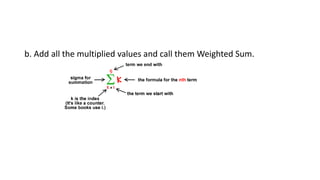
The document discusses machine learning techniques and concepts such as supervised learning, linear discriminant analysis, perceptrons, and more. It begins by defining machine learning and different types including supervised learning. It then covers topics like the brain and neurons, concept learning as search, finding maximally specific hypotheses, version spaces, and the candidate elimination algorithm. It also discusses linear discriminants, perceptrons, and applications of machine learning.