ML Approaches for Multiclass Predictive Maintenance.pptx
1.
Machine Learning Approachesfor Multiclass
Predictive Maintenance of Industrial Rotating
Machinery
Murad Abasov • Nourhane Riham Ouahdi Yohan Arenas • Waleed Ali
ELTE, Eötvös Loránd University
Faculty of Informatics
Savaria Institute of Technology, Szombathely
2.
Research Context
• TheMaintenance Challenge
• Maintenance represents up to 60% of production costs.
• Ineffective maintenance causes $60 billion USD loss annually (US, 2002)
Reduces product quality and plant profitability.
• Industry 4.0 Solution
• PdM can reduce unplanned downtime by up to 50%.
• Extends equipment life cycles by more than 30%.
• Leverages IoT, Big Data, and AI methods.
1
Knowledge Gaps inCurrent PdM
Research
1.
Limited Failure Classification
• Most studies focus on binary fault detection (failure vs. no-failure), leaving multiclass
and multi-label failure prediction underexplored.
2.
Standardized Data Fusion Frameworks
• Few standardized frameworks for integrating heterogeneous sensor modalities.
3.
Explainability Integration
• Limited studies on how feature attribution can improve maintenance decision-making.
4.
Data Scarcity & Imbalance
• Rare fault types hinder model generalization.
3
5.
Compare ML Algorithmsin a multiclass predictive maintenance framework for industrial rotating machinery.
Compare ML Models
1
Detect Multiple Failures
2
Feature Analysis
3
Bridge the gap
4
4
MAIN GOAL
DATASET FEATURES
Key features:
•Product ID
• Air Temperature (K)
• Process Temperature (K)
• Rotational Speed (rpm)
• Torque (Nm)
• Tool Wear (min)
• Failure types:
Failure modes:
• Tool Wear Failure (TWF)
• Heat Dissipation Failure (HDF)
• Power Failure (PWF)
• Overstrain Failure (OSF)
• Random Failure (RNF)
Note: Machine fails if at least one
failure mode is true.
6
8.
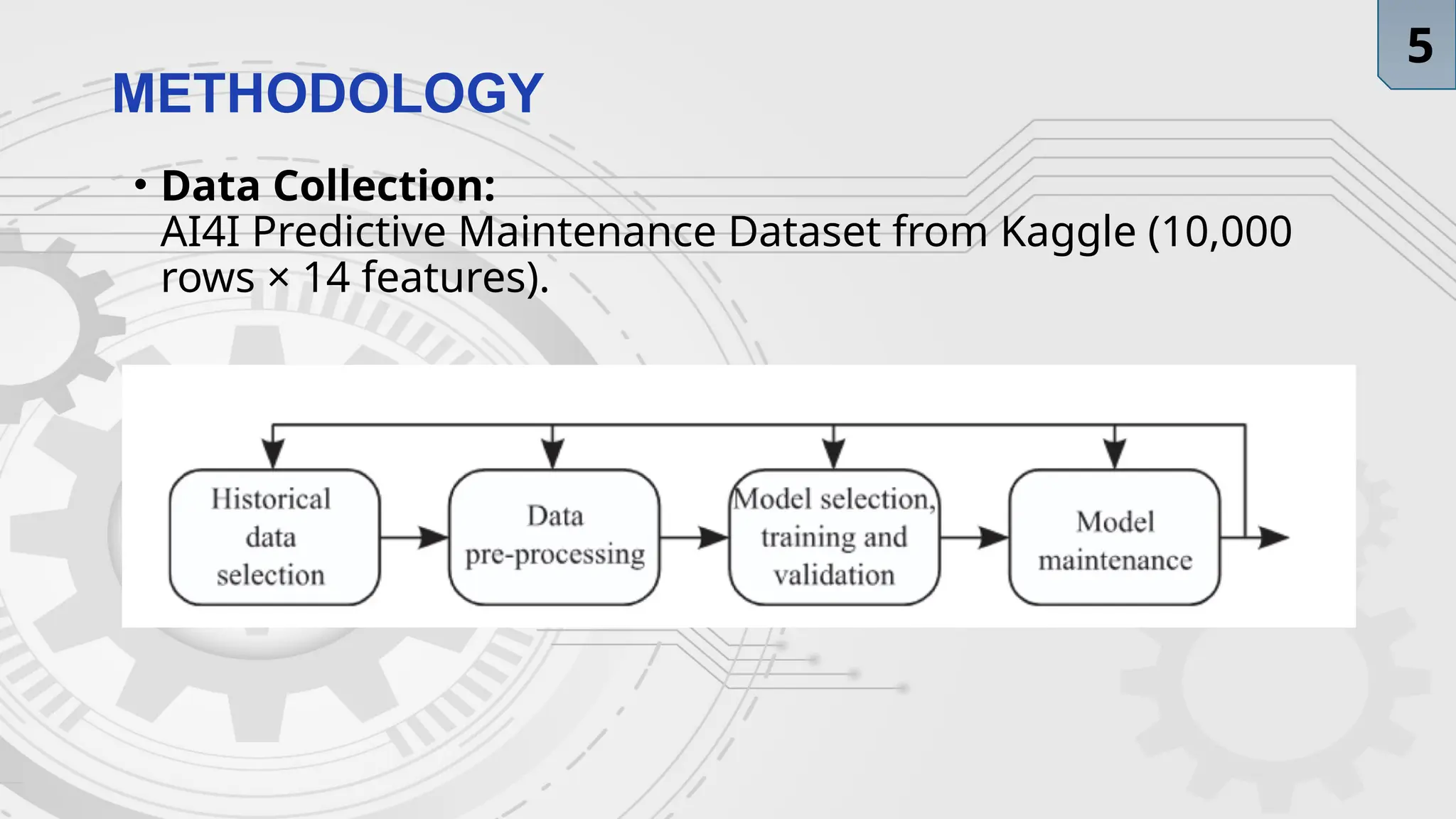
DATA PROCESSING STEPS
1.DataCleaning
• Missing or inconsistent records checked and removed.
2.Normalization
• Min-Max scaling applied to continuous variables
(temperature, speed, torque, tool wear).
3.Encoding
• One-hot encoding for categorical variables (Product ID).
4.Data Splitting
• 80% training / 20% testing.
5.Handling Imbalance
• SMOTE (Synthetic Minority Over-sampling Technique)
applied to balance class distribution.
Validation Strategy
5-fold cross-validation to ensure
generalization and robustness
7
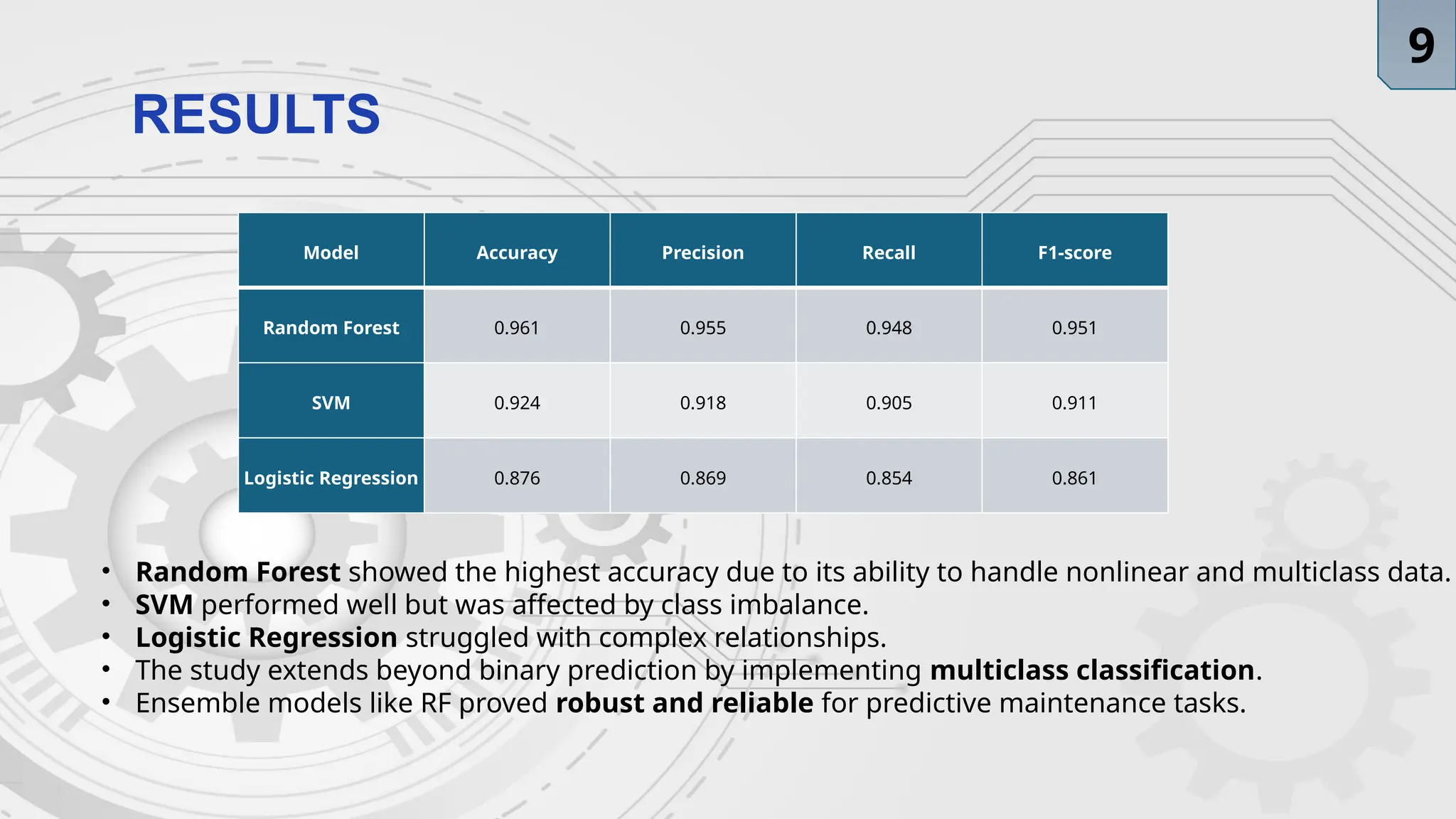
RESULTS
Model Accuracy PrecisionRecall F1-score
Random Forest 0.961 0.955 0.948 0.951
SVM 0.924 0.918 0.905 0.911
Logistic Regression 0.876 0.869 0.854 0.861
• Random Forest showed the highest accuracy due to its ability to handle nonlinear and multiclass data.
• SVM performed well but was affected by class imbalance.
• Logistic Regression struggled with complex relationships.
• The study extends beyond binary prediction by implementing multiclass classification.
• Ensemble models like RF proved robust and reliable for predictive maintenance tasks.
9
11.
IMPACT
For Industry
• Reliablebaseline for real-time
PdM.
• Applicable to CNC machines,
turbines and pumps.
• Reduces maintenance costs.
• Improves equipment reliability
For Decision-Making
• Multiple failure modes
detected simultaneously.
• Better maintenance
scheduling.
• Enhanced operational safety.
• Data-driven insights.
Trade-offs to Consider
Balance between accuracy, interpretability, and computational cost
when deploying on industrial hardware.
10
12.
LIMITATIONS
1.Synthetic Dataset
• Maynot fully capture stochastic variability, sensor noise, or missing
data from real industrial environments.
2.Limited to Classical ML
• Deep learning, hybrid models, and transformer architectures were
not explored.
3.No Temporal Analysis
• Time-series features and Remaining Useful Life (RUL) estimation
not incorporated.
4.Feature Engineering
• Advanced time-frequency decomposition techniques not applied.
11
13.
Future work :
•Applyingthe model to real industrial data.
•Incorporating time-series feature extraction.
•Evaluating the performance of deep learning
and hybrid methods.
12
14.
CONCLUSION
Why RF Succeeds
•Handles heterogeneous
sensor data.
• Robust to noise and outliers
• Reduces overfitting via
bagging
• Captures non-linear patterns
Other Models
• SVM: Sensitive to parameter
tuning and class imbalance.
• LR: Limited for nonlinear
relationships.
Feature Importance Insights
Torque, rotational speed, and tool wear identified as most influential factors
13








































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)



