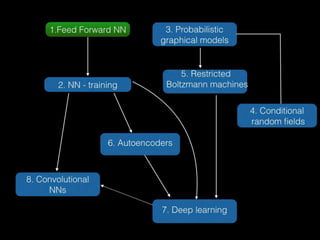
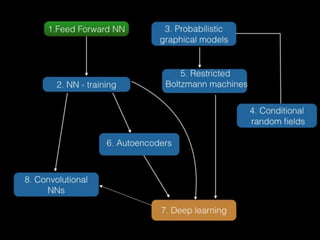
Siódma część wykładów na temat deep learning i uczenia maszynowego. Prowadzone były na AGH, przez firme Craftinity (Craftinity.com), razem z kołem naukowym BIT (http://knbit.edu.pl/pl/)
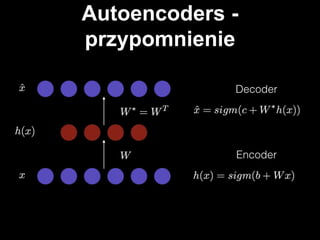
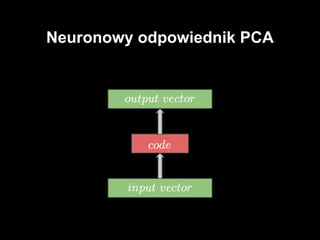
#7 sieć neuronowa z jedną warstwą ukrytą
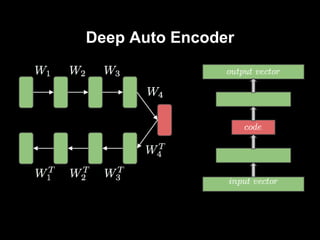
aktywacja neuronów w warstwie ukrytej - encoder
aktywacja na widocznej - dekoder
rozmiar wejściowej == rozmiar dekodera
cel: kompresja danych, ekstrakcja cech z danych
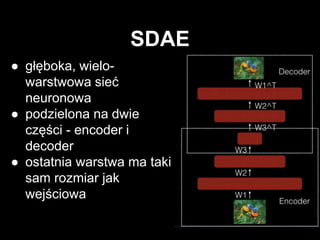
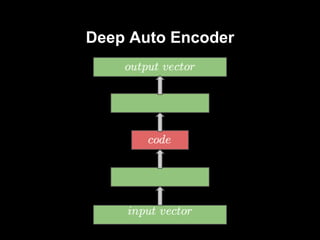
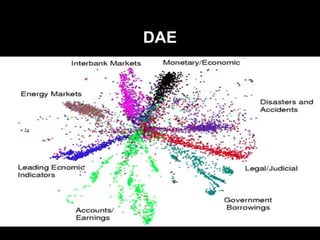
#8 budujemy głęboki model licząc na to, że wyekstrachuje nam lepsze cechy -> idea taka sama jak w przypadku innych modeli głębokich
sieć zwęża się do pewnego momentu, później rozszerza się w taki sam sposób jak poprzednio się zwężała
podobnie jak w autoencoderze na wyjściu chcemy uzyskać mały błąd rekonstrukcji
problem z trenowaniem -> zwykłe backpropagation powoduje underfitting - błąd rekonstrukcji bardzo duży
staramy się ratować tym samym czym się ratujemy w przypadku głębokich sieci FF
#9 pretrenowanie warstwa po warstwa
mogą być autoencoder-y albo RBM-y
ciekawostka: w przypadku sieci FF używanych przy Supervised Learning pretrenowanie działa jak dobry regularyzator - unikamy overfittingu
w tym przyapdku pomagamy sobie osiągając lepsze minimum funkcji kosztu
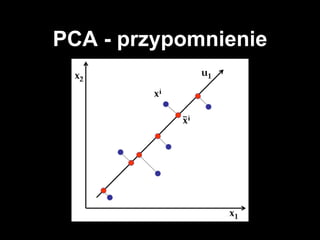
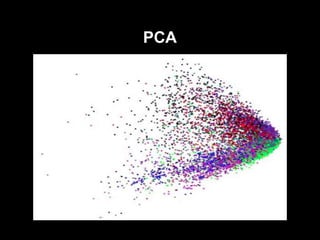
#14 liniowy model redukcji wymiarowości
intuicja: bierze n-wymiarowe dane i znajduje m ortogonalnych kierunków w których dane mają największą wariancję. To M kierunków tworzy mało wymiarową przestrzeń, do której rzutujemy dane
działa kiepsko bo jest tylko liniowy