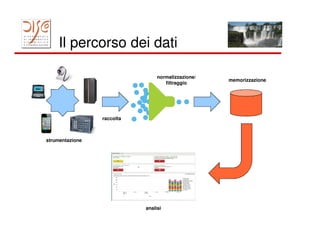
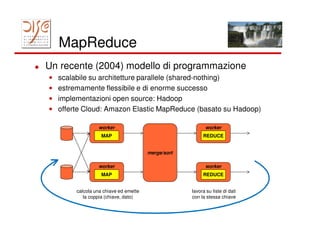
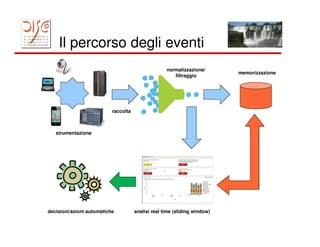
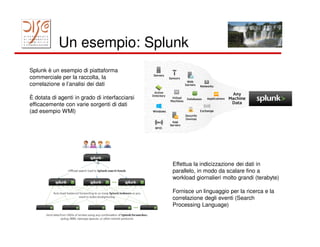
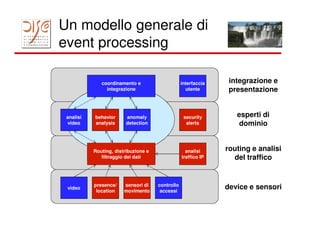
Il documento tratta dell'importanza dei big data e dell'elaborazione degli eventi, evidenziando l'uso di tecnologie come MapReduce e Hadoop per l'analisi di grandi volumi di dati. Viene discusso anche il concetto di smart cities e l'importanza della correlazione temporale degli eventi per rispondere in tempo reale a varie applicazioni, dal marketing alla gestione della sicurezza. Infine, si menziona l'uso di piattaforme come Splunk per la raccolta e l'analisi dei dati, insieme alle sfide di implementare reazioni automatiche ai flussi di eventi.