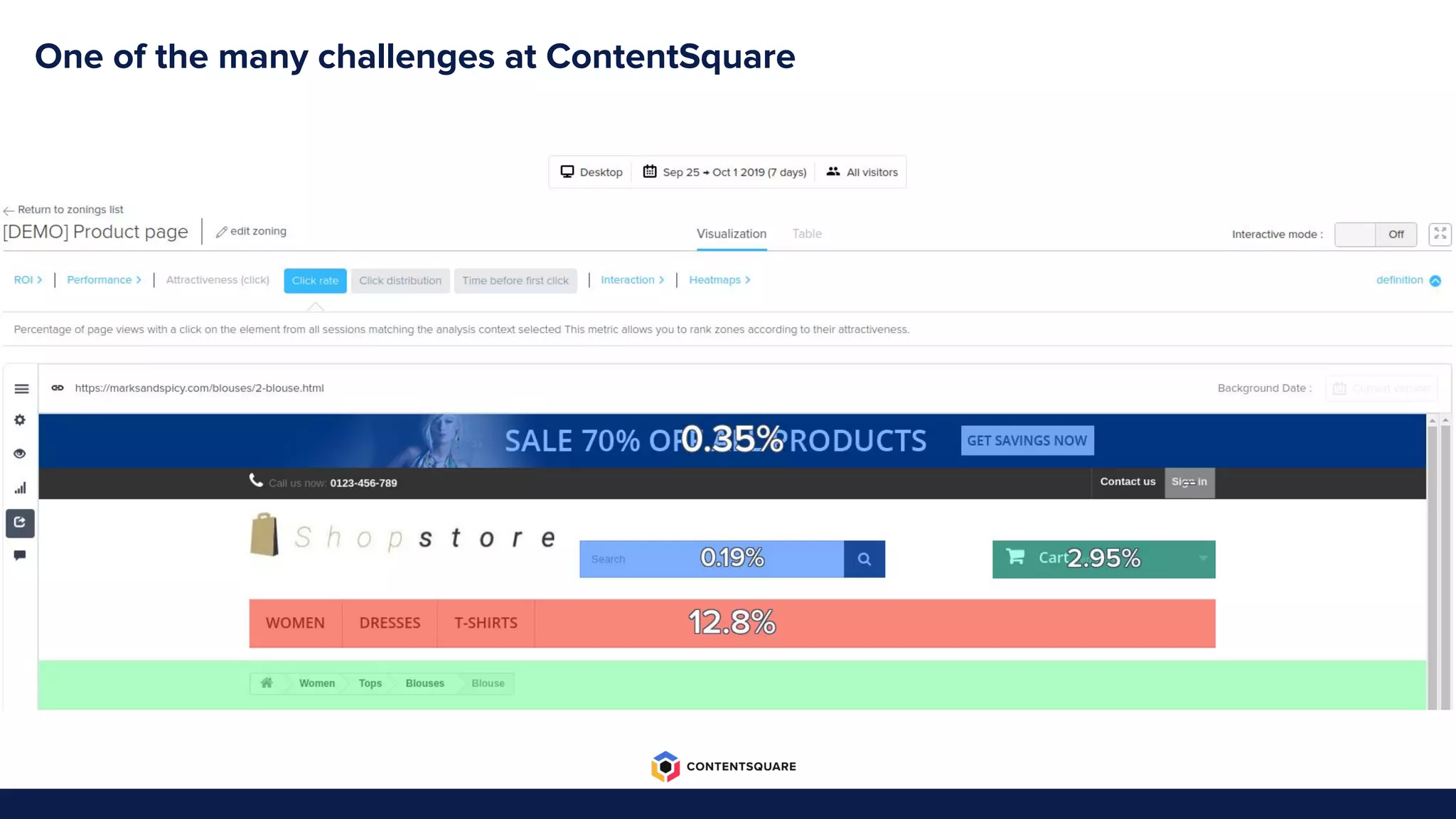
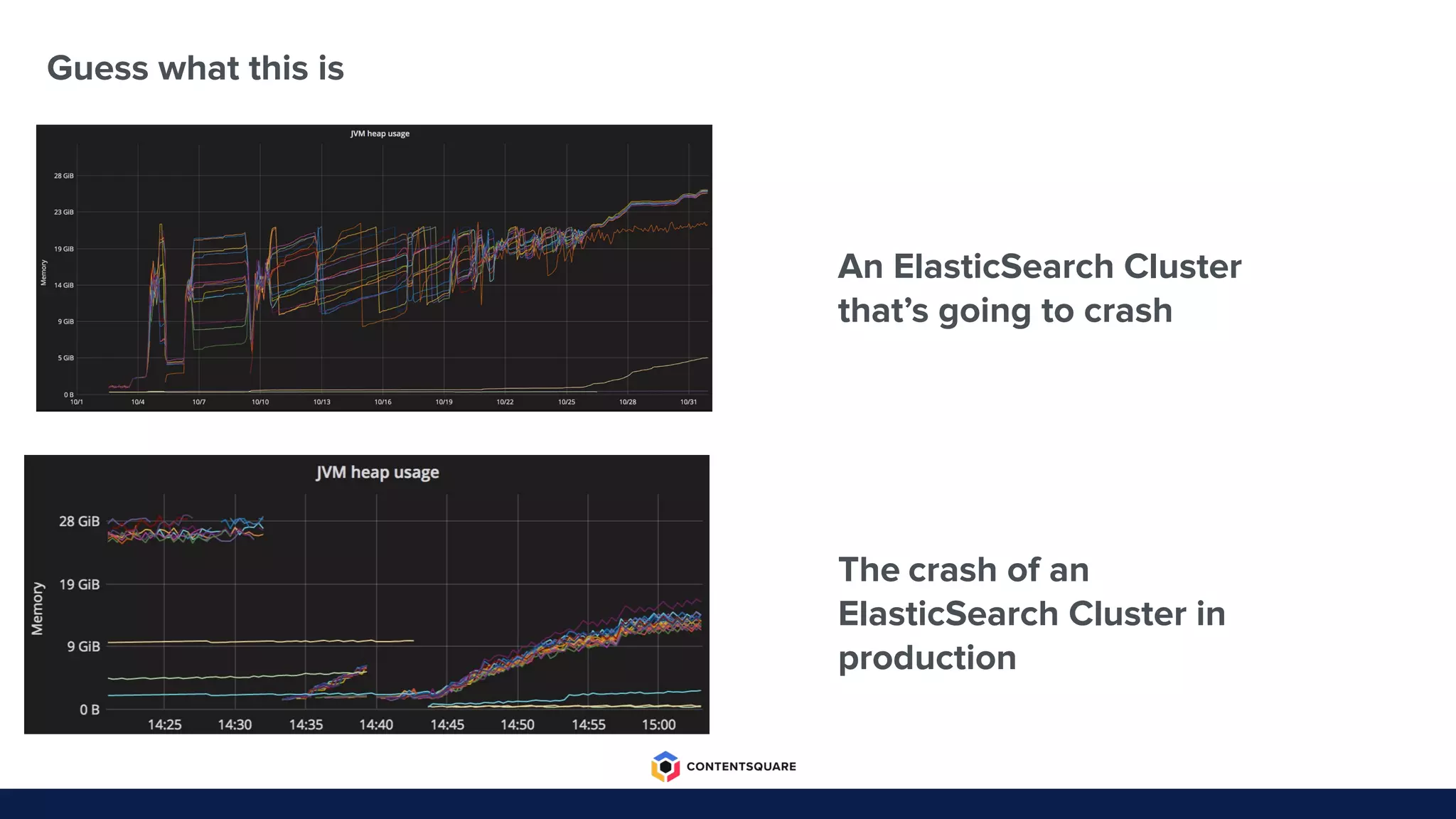
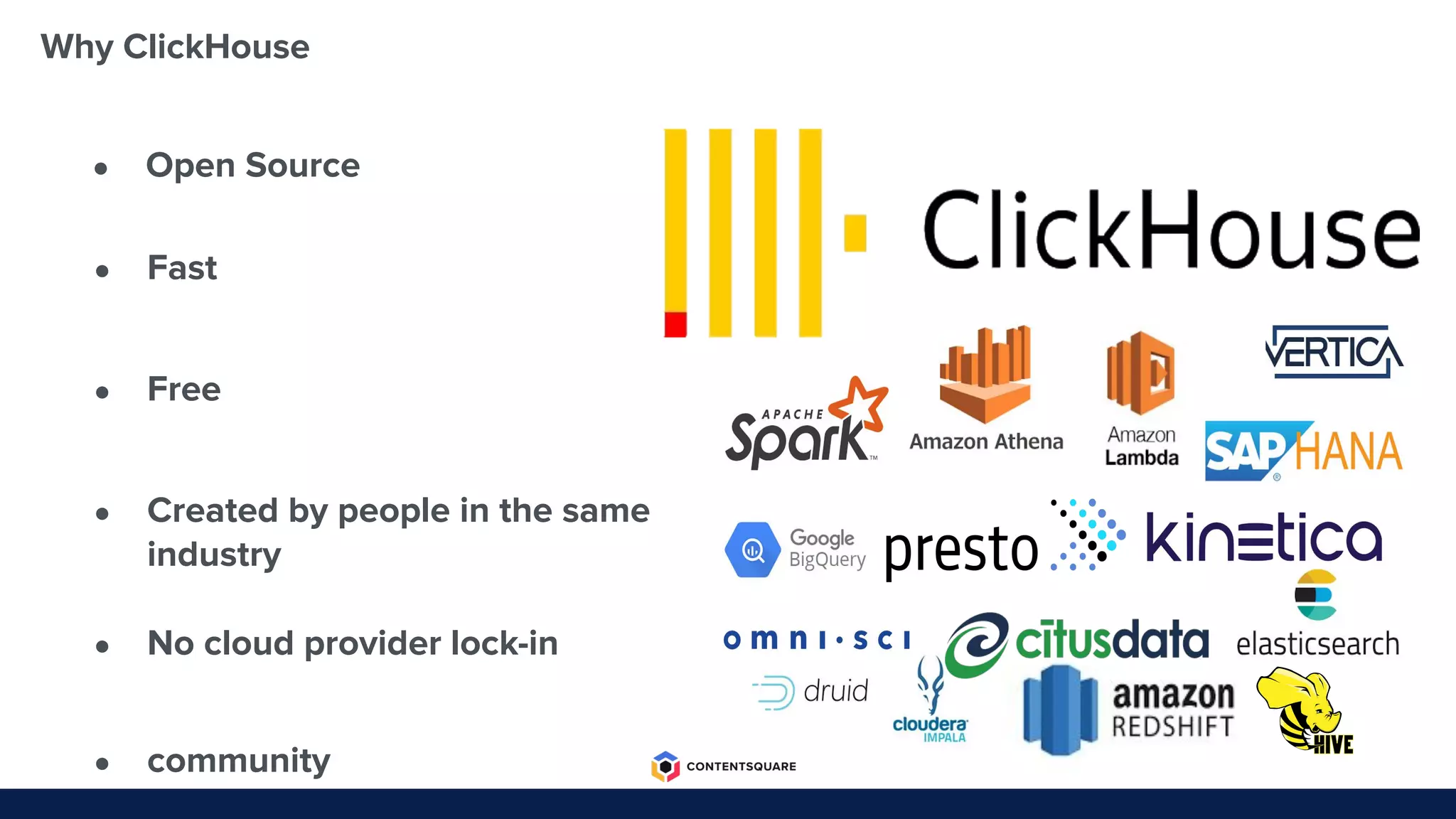
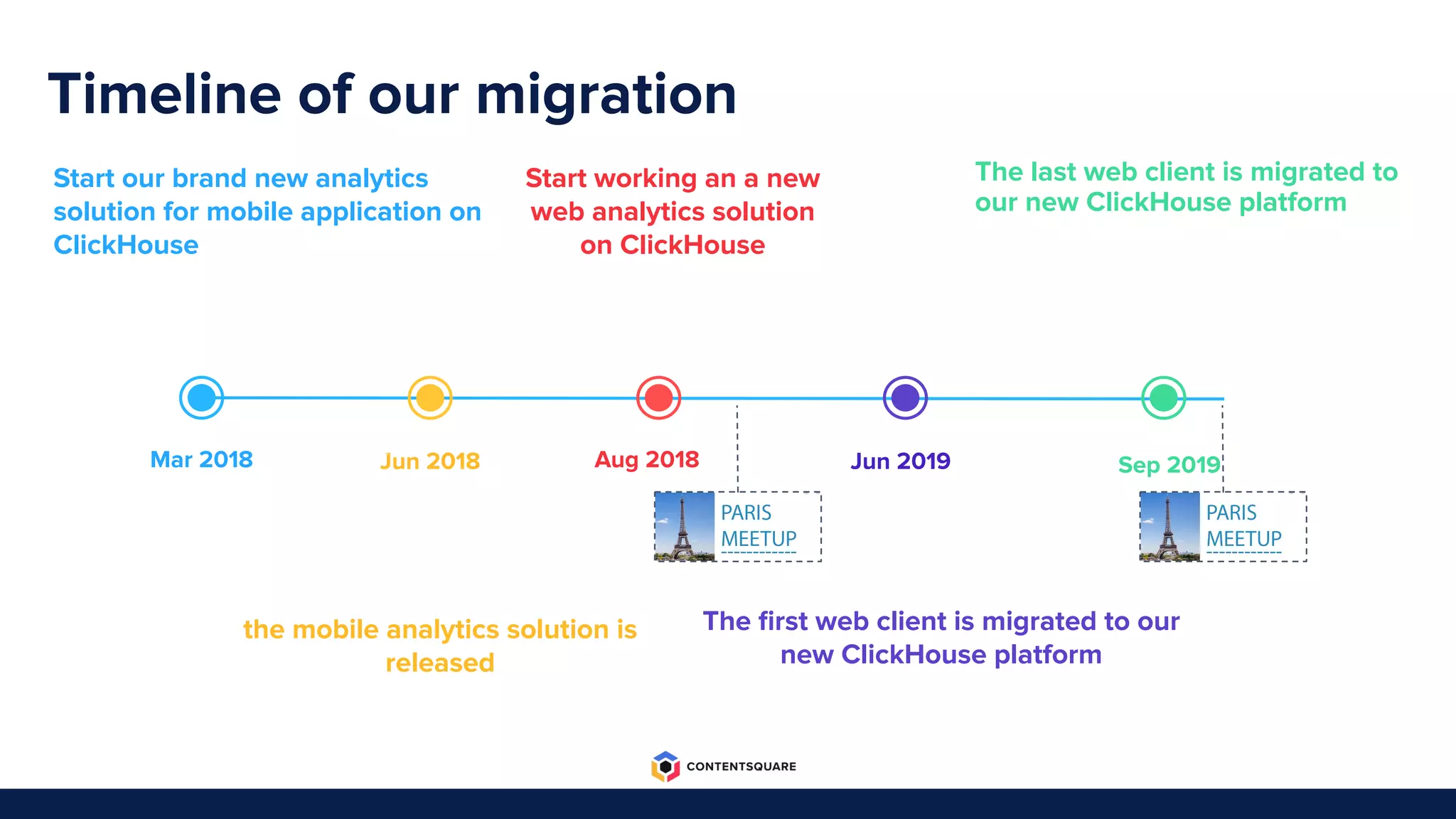
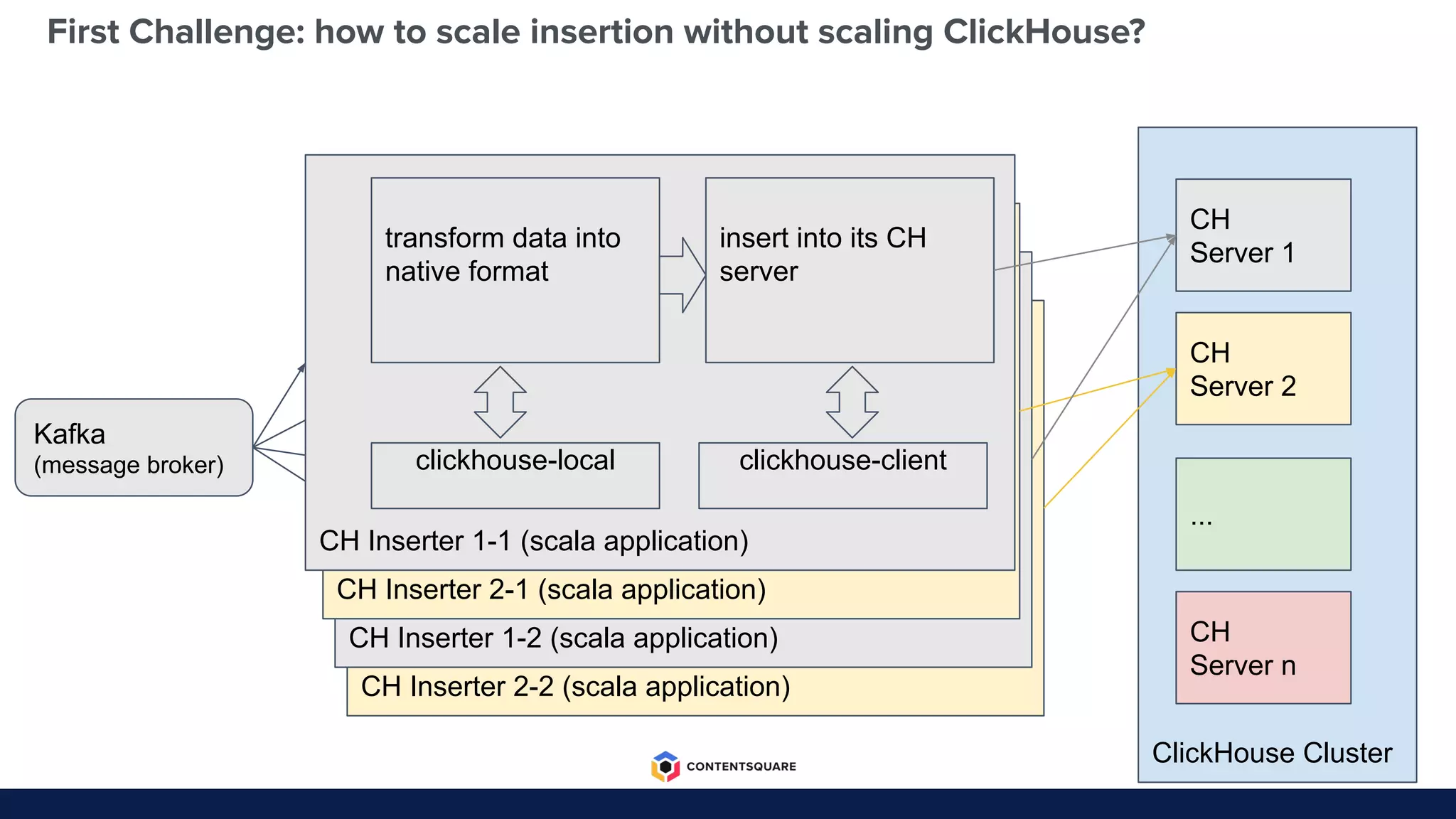
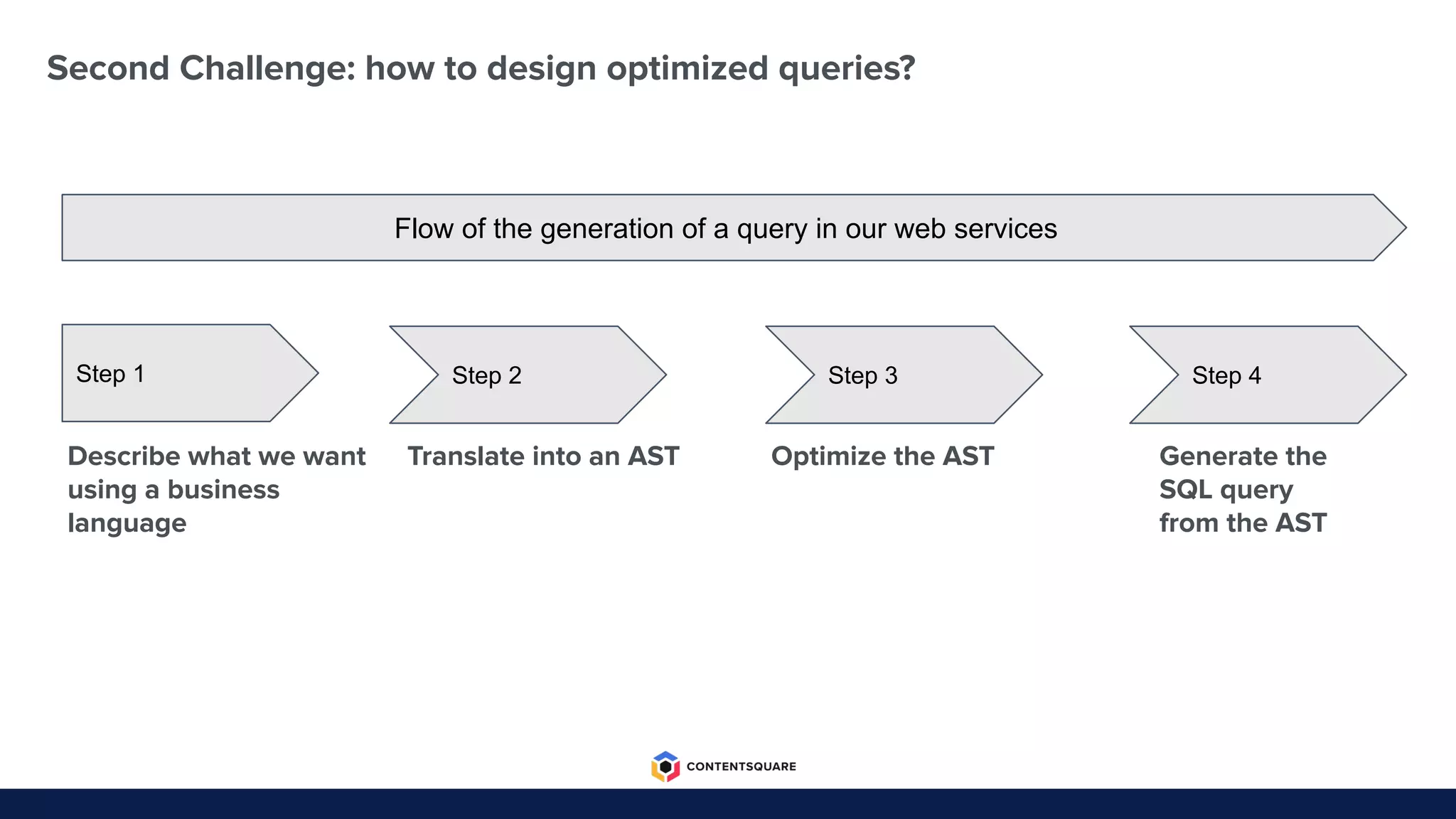
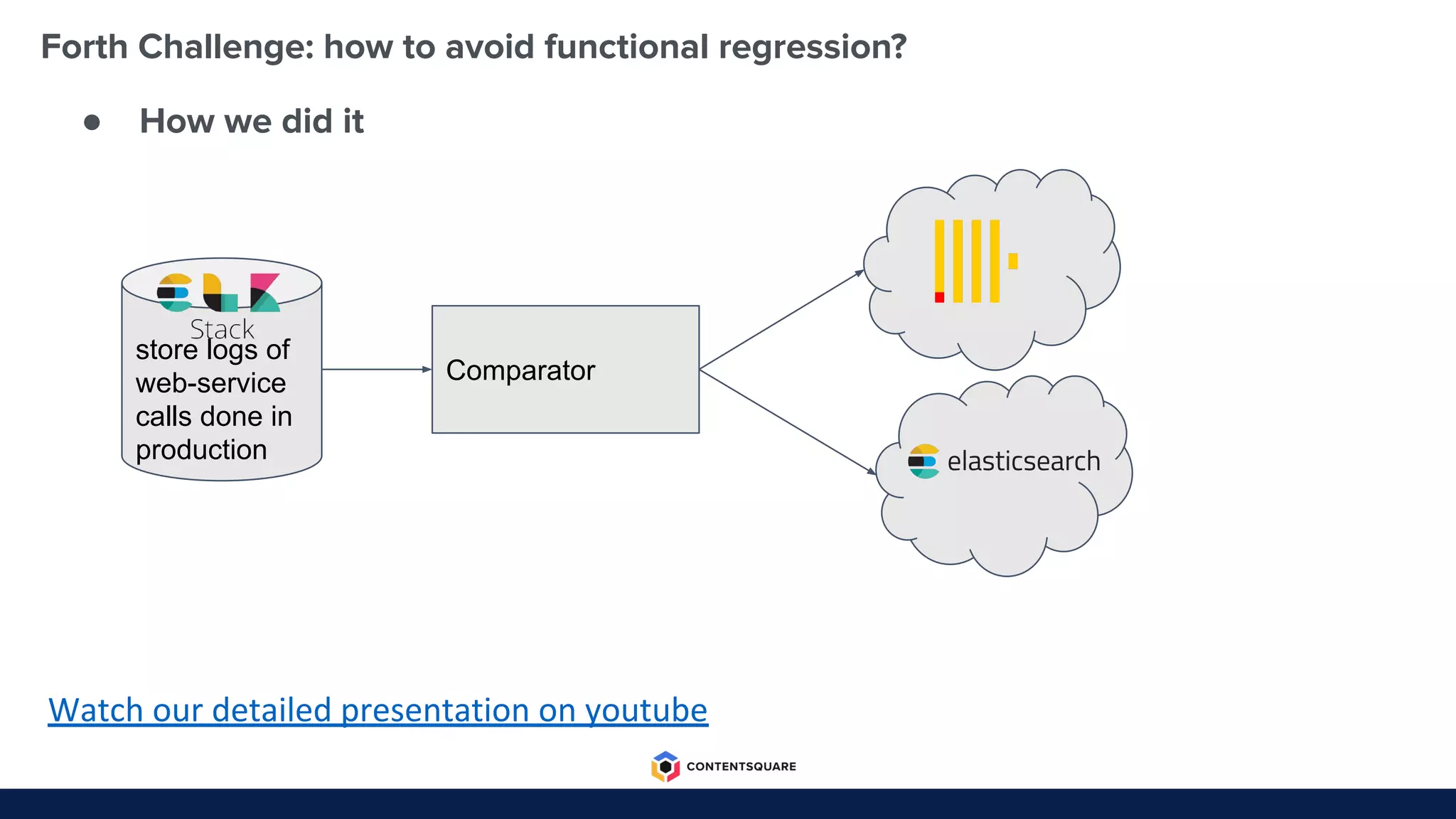
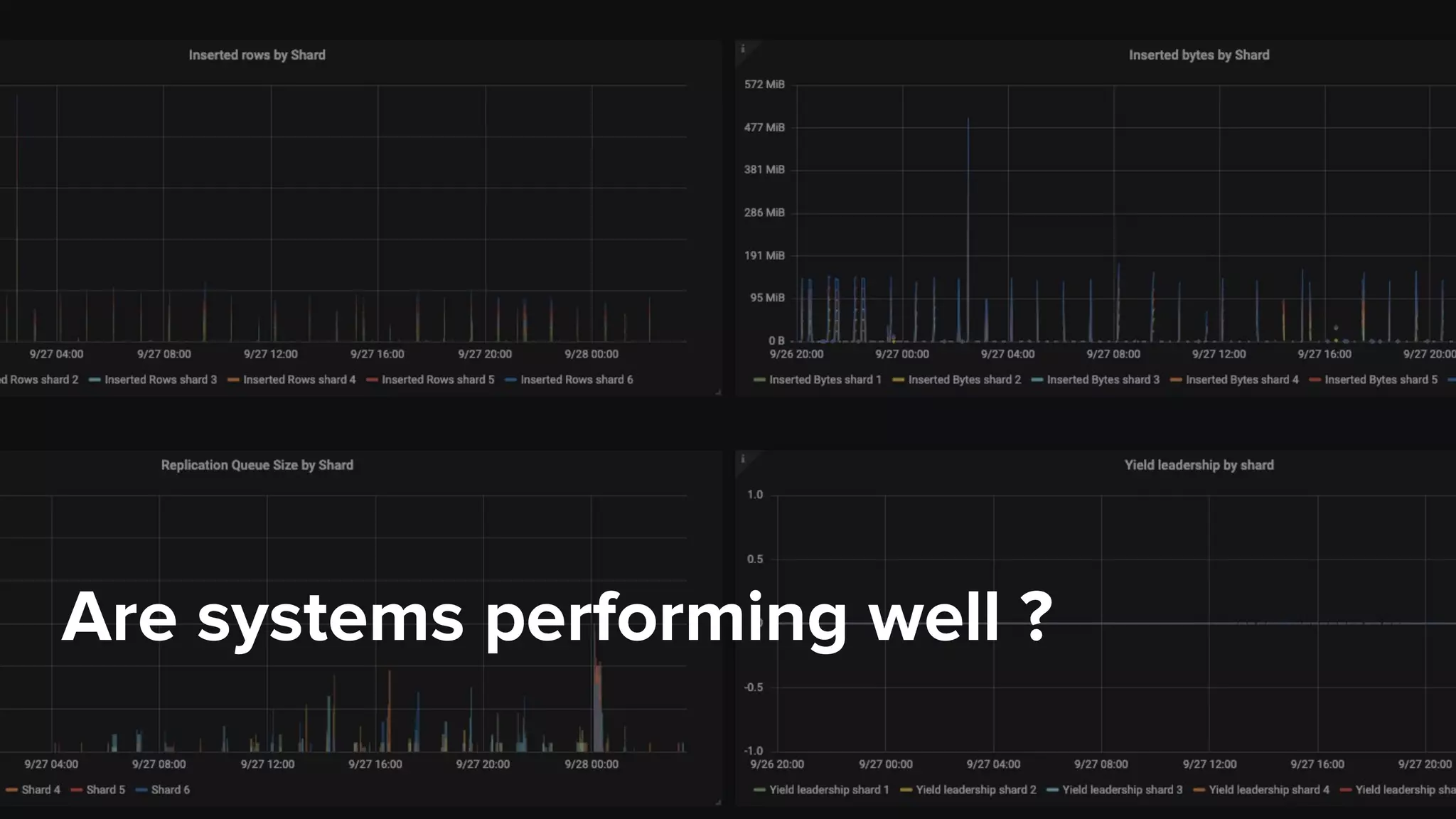
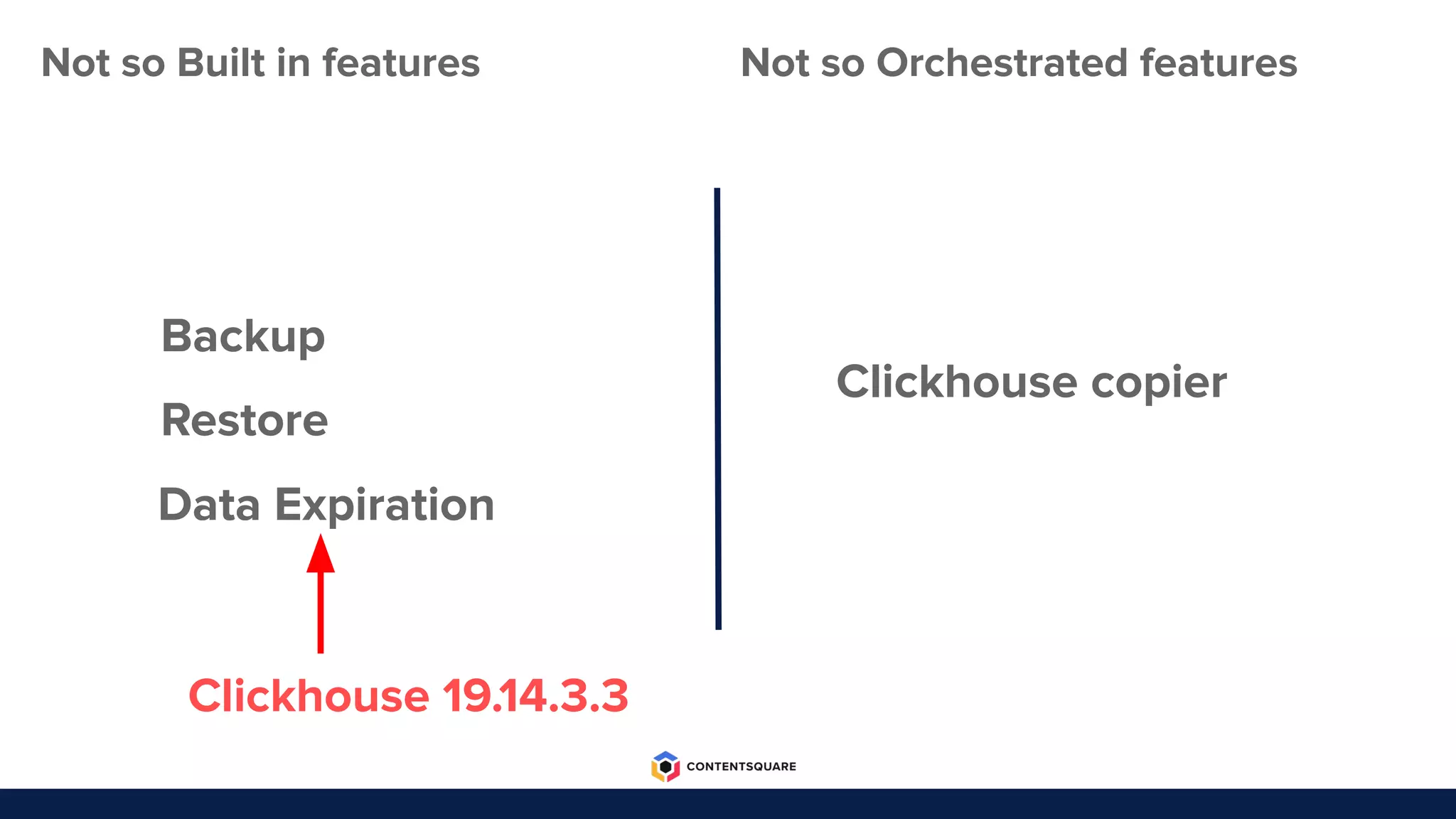
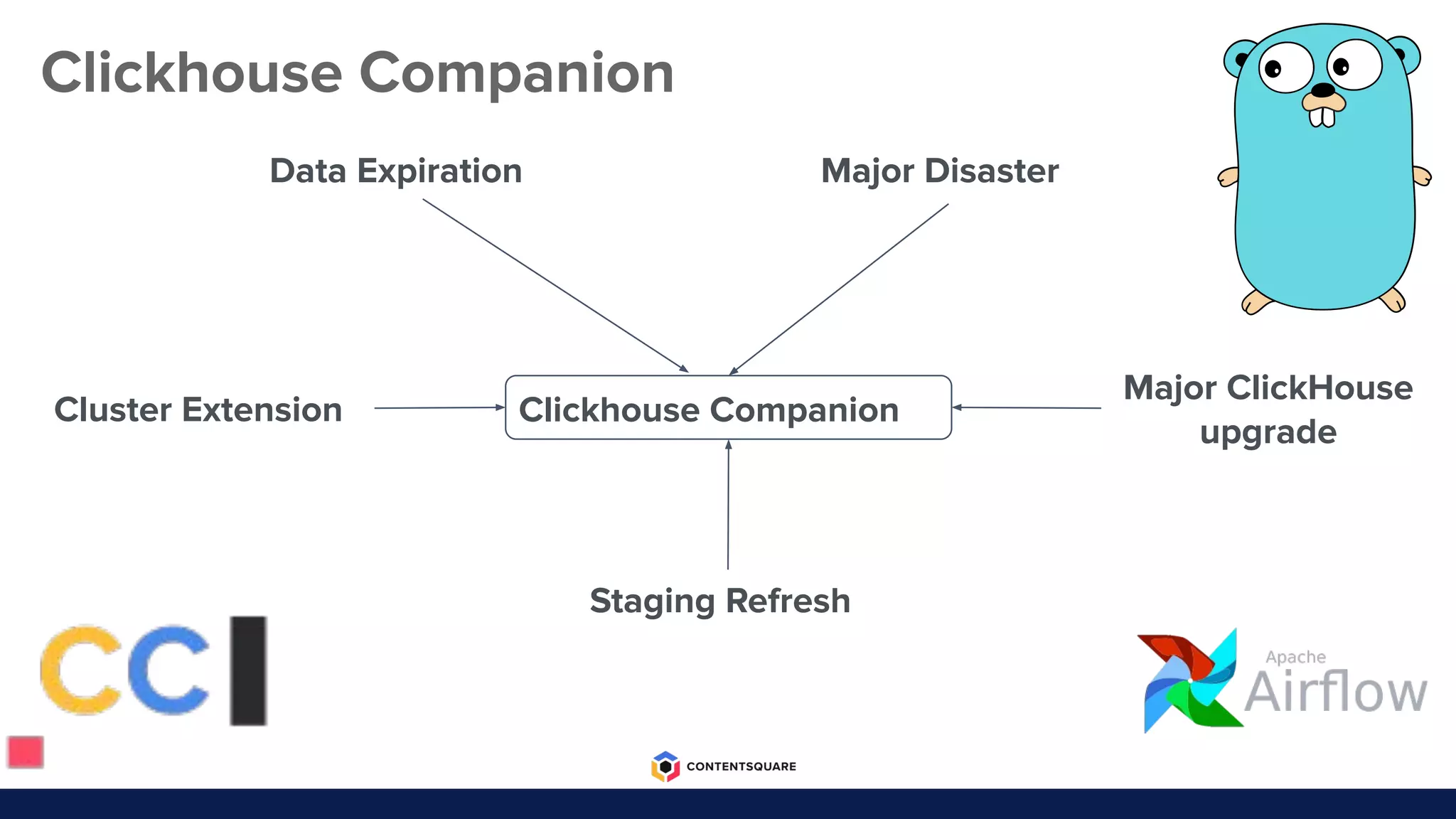
The document outlines the migration process from Elasticsearch to ClickHouse by Contentsquare, detailing the reasons for the switch, key challenges faced, and the benefits of using ClickHouse, which include cost-efficiency and improved performance. It also discusses various technical challenges encountered, such as optimizing query design, reducing storage costs, and ensuring system reliability post-migration. The document concludes with takeaways emphasizing automation, metrics, and developer empowerment in the transition process.












































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















