Downloaded 262 times





![ClickHouse performance tuning is different...
The bad news…
● No query optimizer
● No EXPLAIN PLAN
● May need to move [a lot
of] data for performance
The good news…
● No query optimizer!
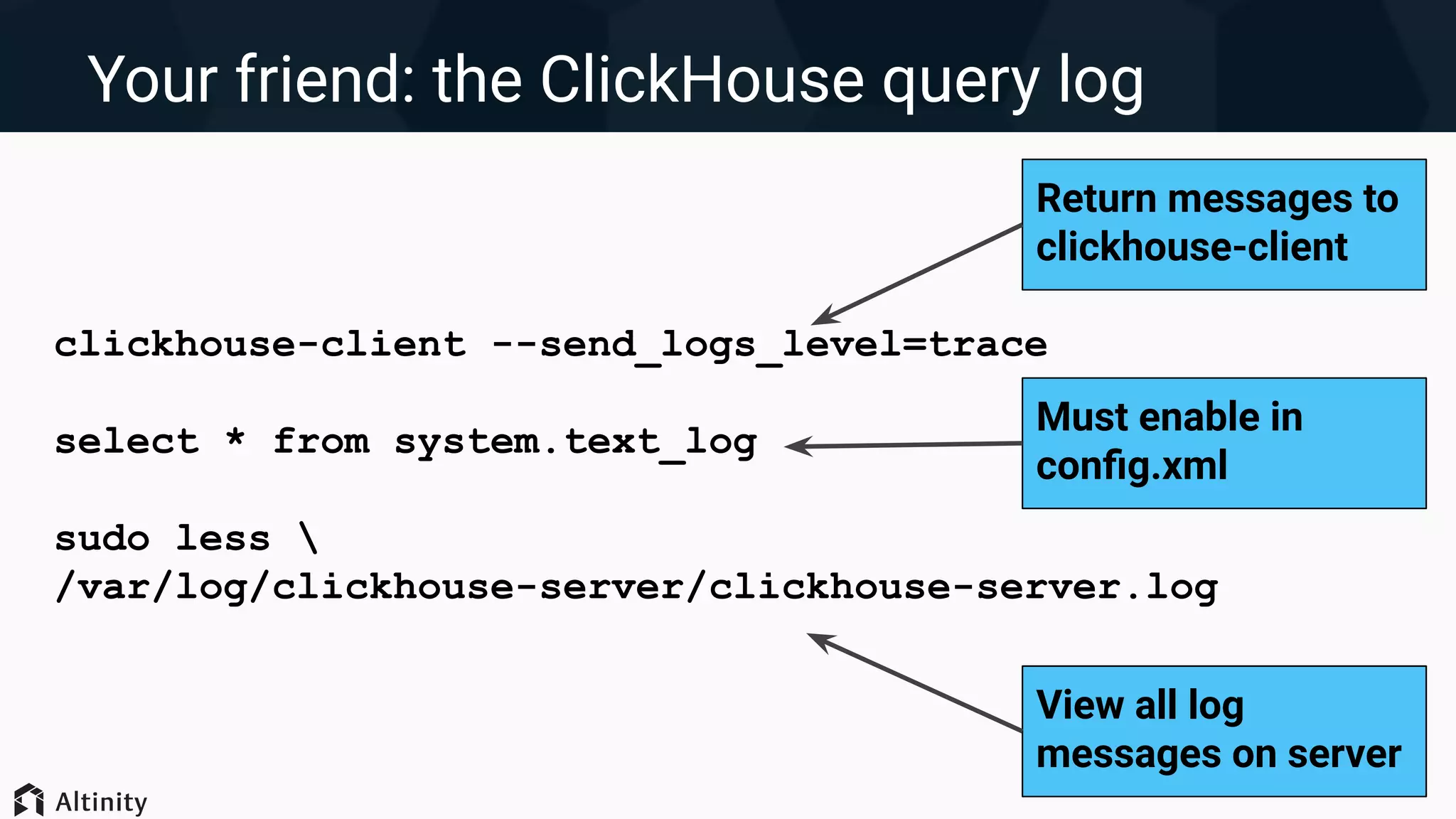
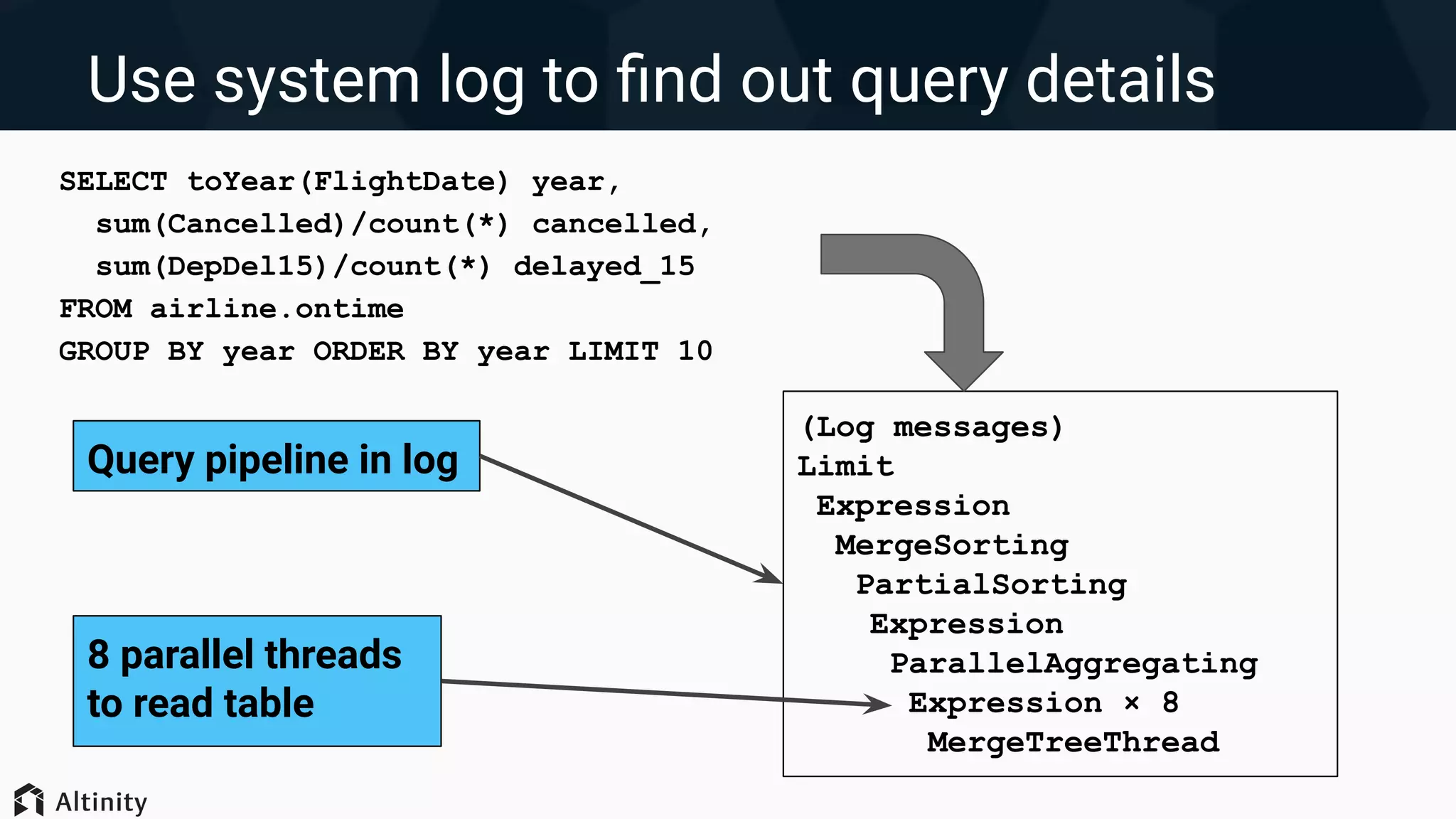
● System log is great
● System tables are too
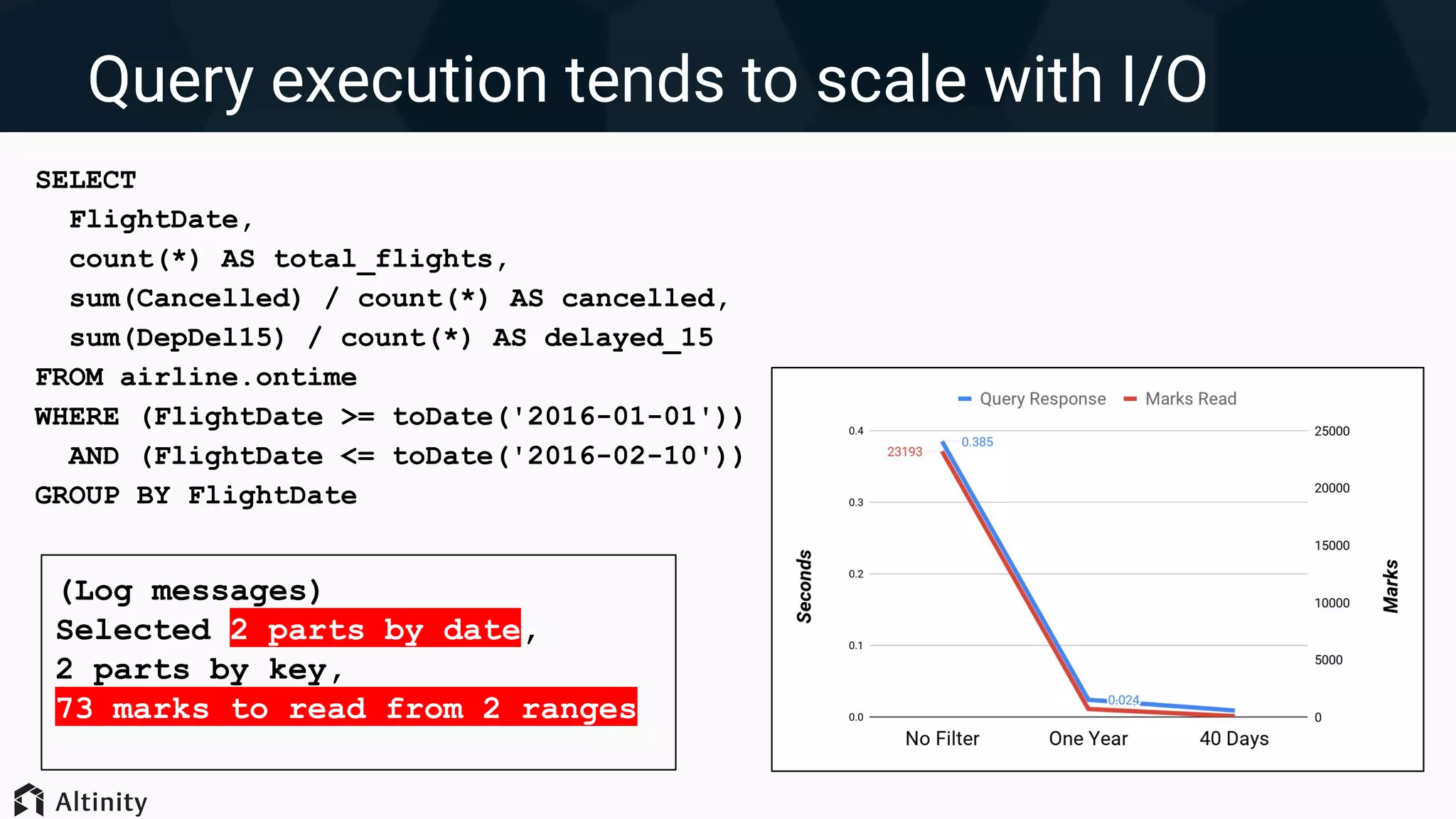
● Performance drivers are
simple: I/O and CPU](https://image.slidesharecdn.com/spkdx4jot1qxqv74ldhs-signature-c11a1e1ea9d6871527efe0518f88f0ae107e1ad90513483e986019fda779f6ee-poli-191014171058/75/ClickHouse-Query-Performance-Tips-and-Tricks-by-Robert-Hodges-Altinity-CEO-10-2048.jpg)


![(PREWHERE Log messages)
Elapsed: 0.591 sec.
Processed 173.82 million rows,
2.09 GB (294.34 million rows/s.,
3.53 GB/s.)
Use PREWHERE to help filter unindexed data
SELECT
Year, count(*) AS total_flights,
count(distinct Dest) as destinations,
count(distinct Carrier) as carriers,
sum(Cancelled) / count(*) AS cancelled,
sum(DepDel15) / count(*) AS delayed_15
FROM airline.ontime [PRE]WHERE Dest = 'BLI' GROUP BY Year
(WHERE Log messages)
Elapsed: 0.816 sec.
Processed 173.82 million rows,
5.74 GB (213.03 million rows/s.,
7.03 GB/s.)](https://image.slidesharecdn.com/spkdx4jot1qxqv74ldhs-signature-c11a1e1ea9d6871527efe0518f88f0ae107e1ad90513483e986019fda779f6ee-poli-191014171058/75/ClickHouse-Query-Performance-Tips-and-Tricks-by-Robert-Hodges-Altinity-CEO-16-2048.jpg)








![Effectiveness depends on data distribution
SELECT
Year, count(*) AS flights,
sum(Cancelled) / flights AS cancelled,
sum(DepDel15) / flights AS delayed_15
FROM airline.ontime WHERE [Column] = [Value] GROUP BY Year
Column Value Index Count Rows Processed Query Response
Dest PPG ngrambf_v1 525 4.30M 0.053
Dest ATL ngrambf_v1 9,360,581 166.81M 0.622
Carrier ML set 70,622 3.39M 0.090
Carrier WN set 25,918,402 166.24M 0.566](https://image.slidesharecdn.com/spkdx4jot1qxqv74ldhs-signature-c11a1e1ea9d6871527efe0518f88f0ae107e1ad90513483e986019fda779f6ee-poli-191014171058/75/ClickHouse-Query-Performance-Tips-and-Tricks-by-Robert-Hodges-Altinity-CEO-29-2048.jpg)
















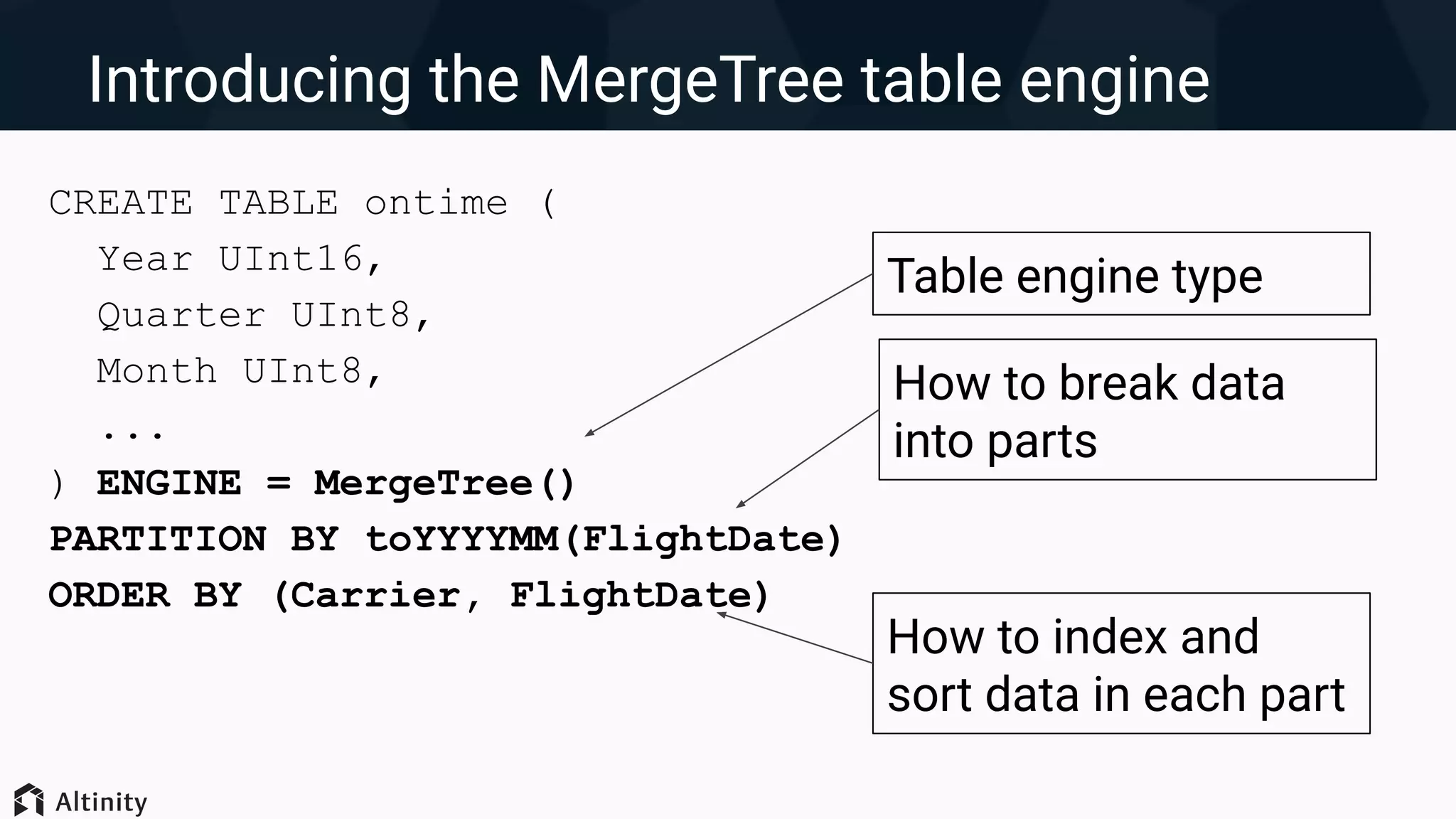
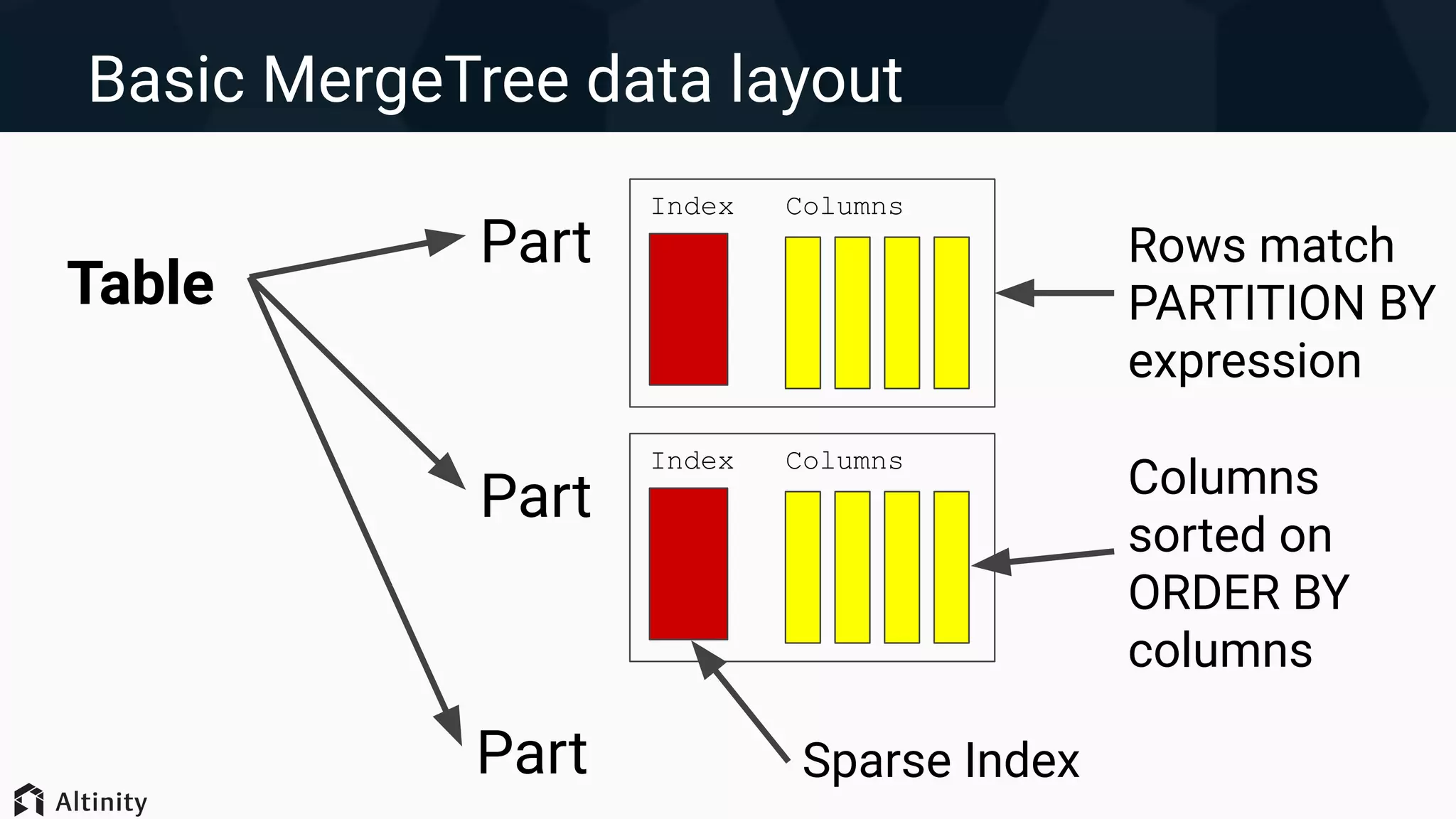
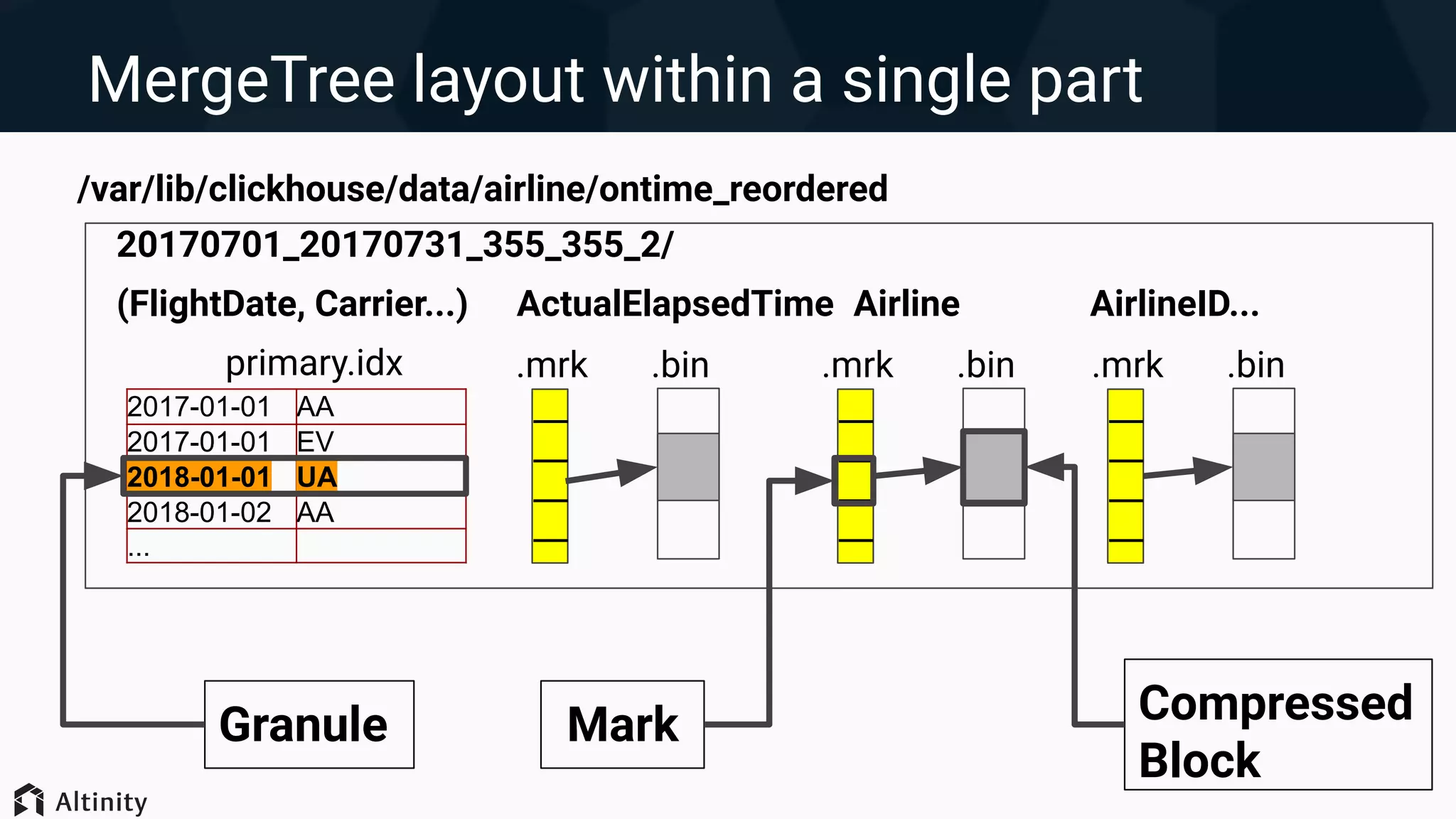
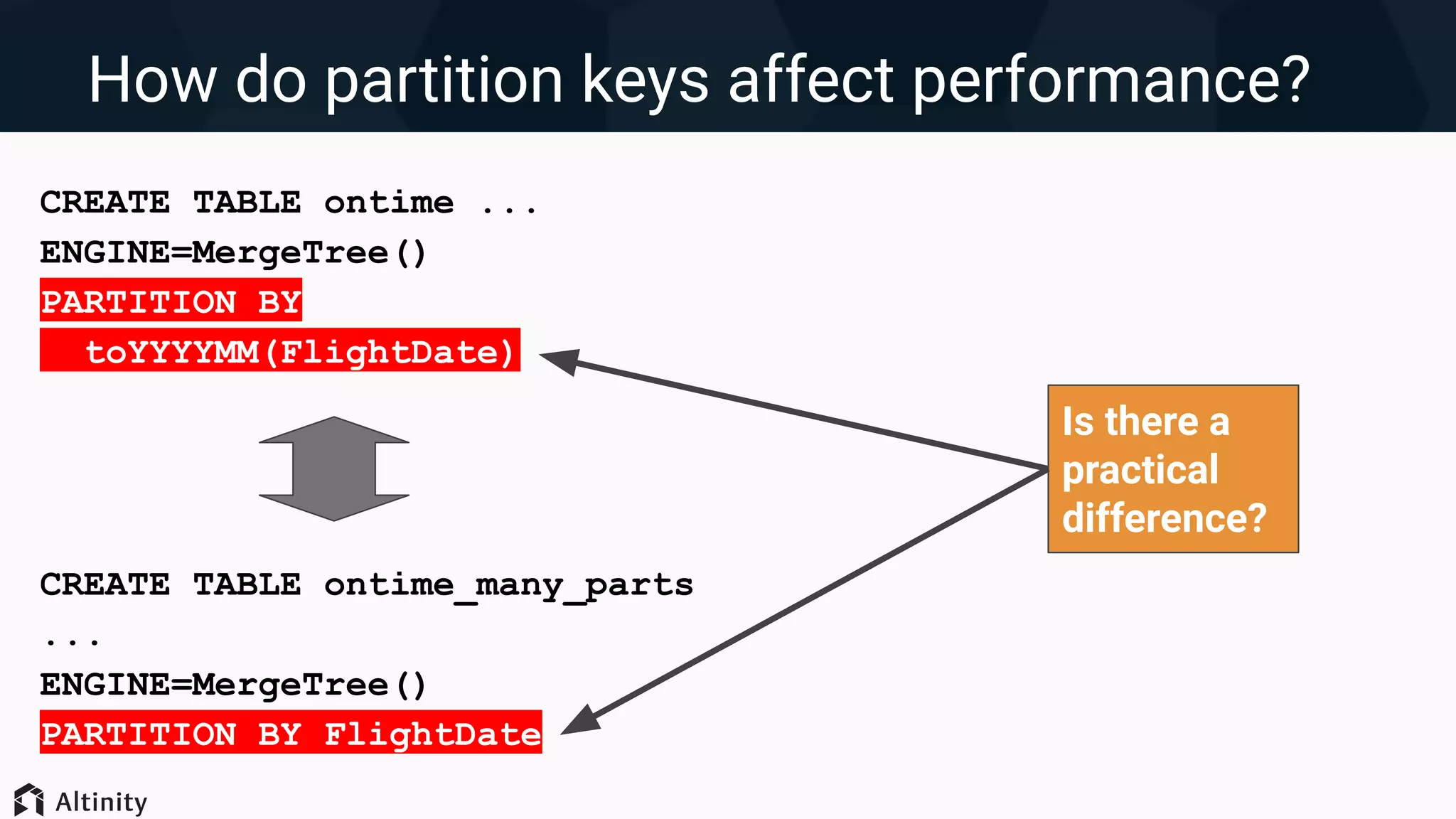
1. ClickHouse uses a MergeTree storage engine that stores data in compressed columnar format and partitions data into parts for efficient querying. 2. Query performance can be optimized by increasing threads, reducing data reads through filtering, restructuring queries, and changing the data layout such as partitioning strategy and primary key ordering. 3. Significant performance gains are possible by optimizing the data layout, such as keeping an optimal number of partitions, using encodings to reduce data size, and skip indexes to avoid unnecessary I/O. Proper indexes and encodings can greatly accelerate queries.
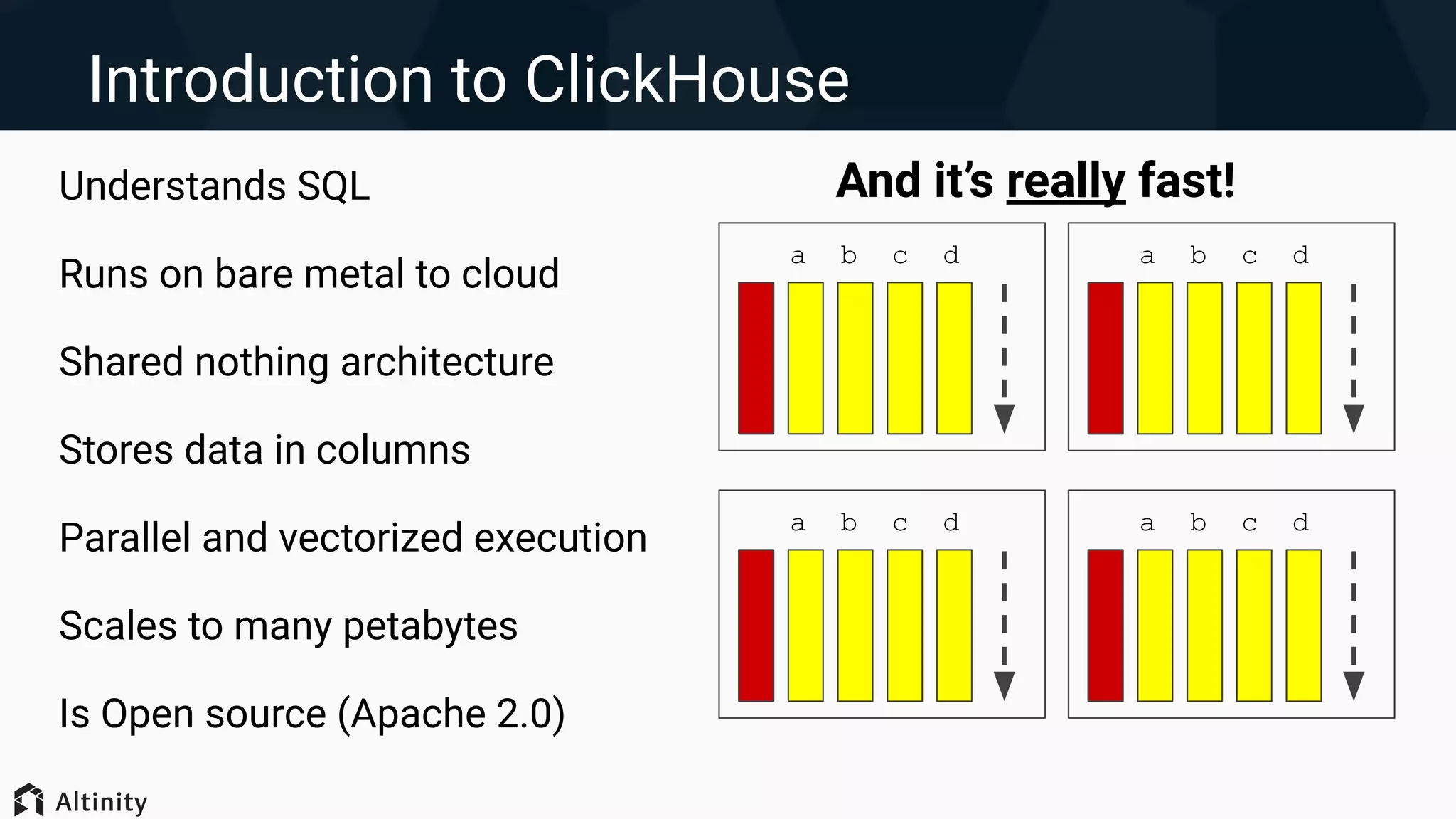
Introduction to ClickHouse performance tips, goals of the talk including understanding data structure and performance optimization.
Introduction to ClickHouse features and MergeTree table engine, with emphasis on data storage and organization.
Strategies for tuning queries in ClickHouse, including system logs, multi-threading, and reducing data reads for improved performance.
Utilizing PREWHERE filtering, restructuring joins for efficiency, and analyzing logs for improved query execution times.
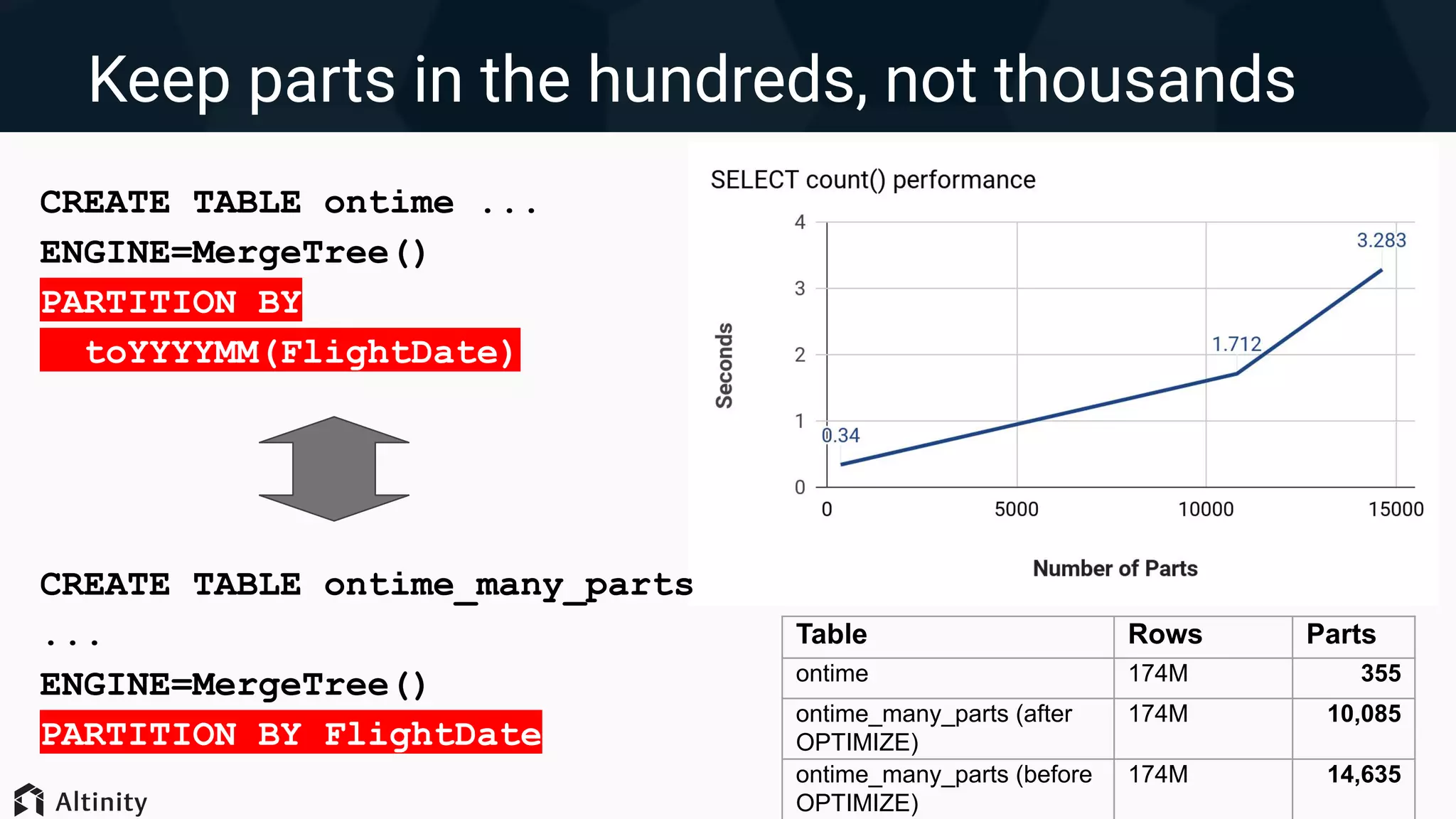
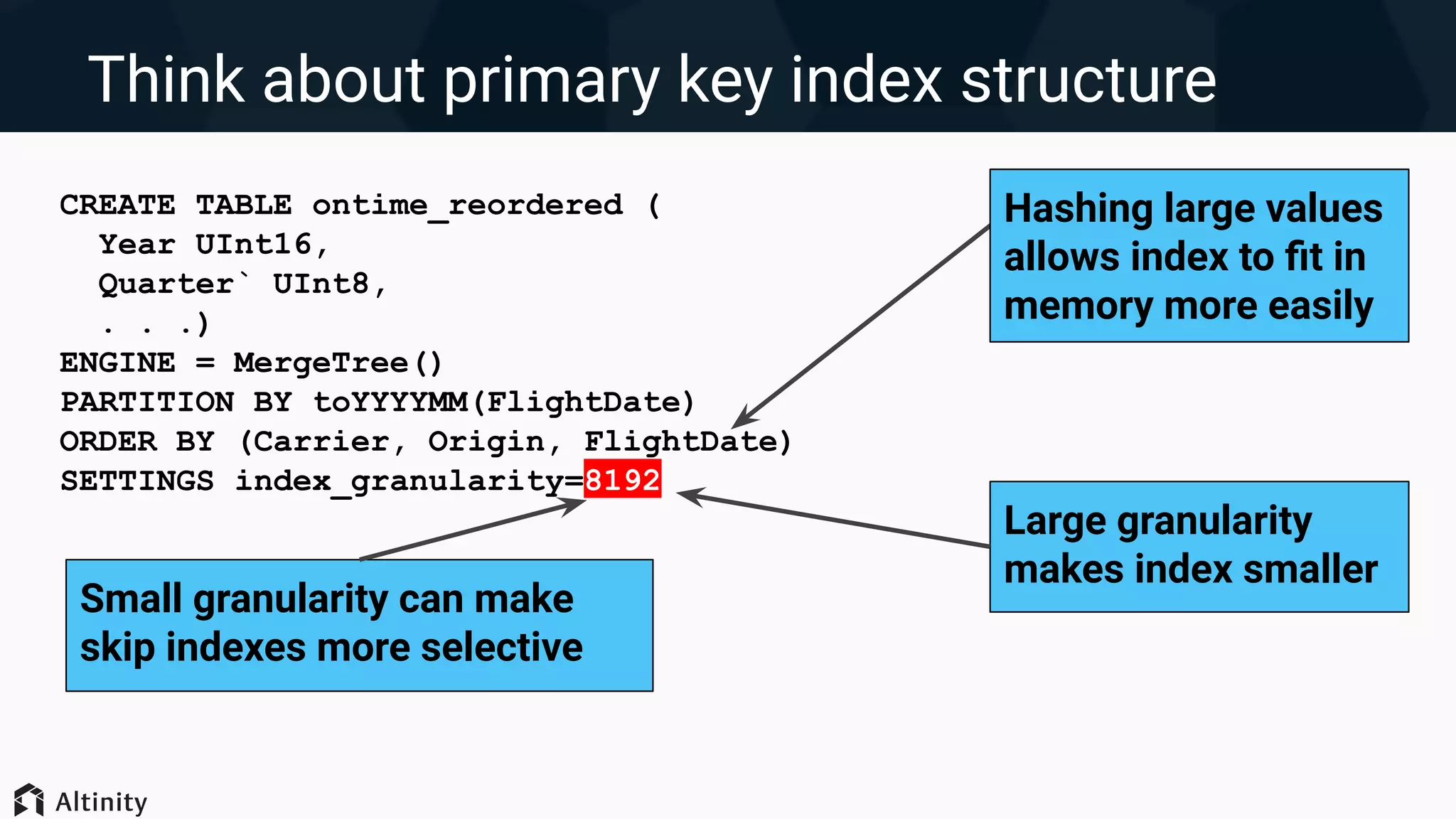
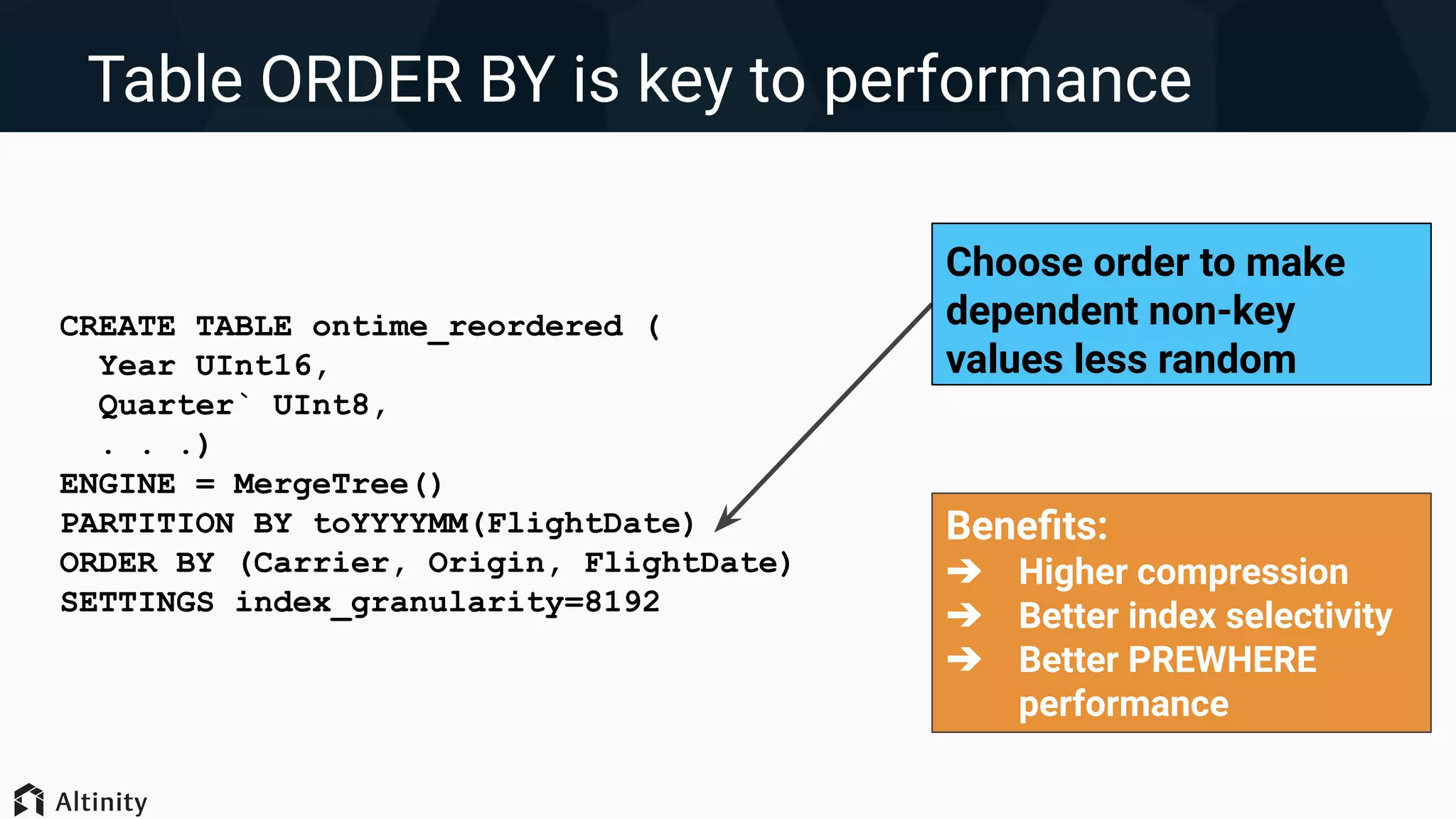
Techniques for optimizing data layout including primary key indexing, managing parts, and using skip indexes.
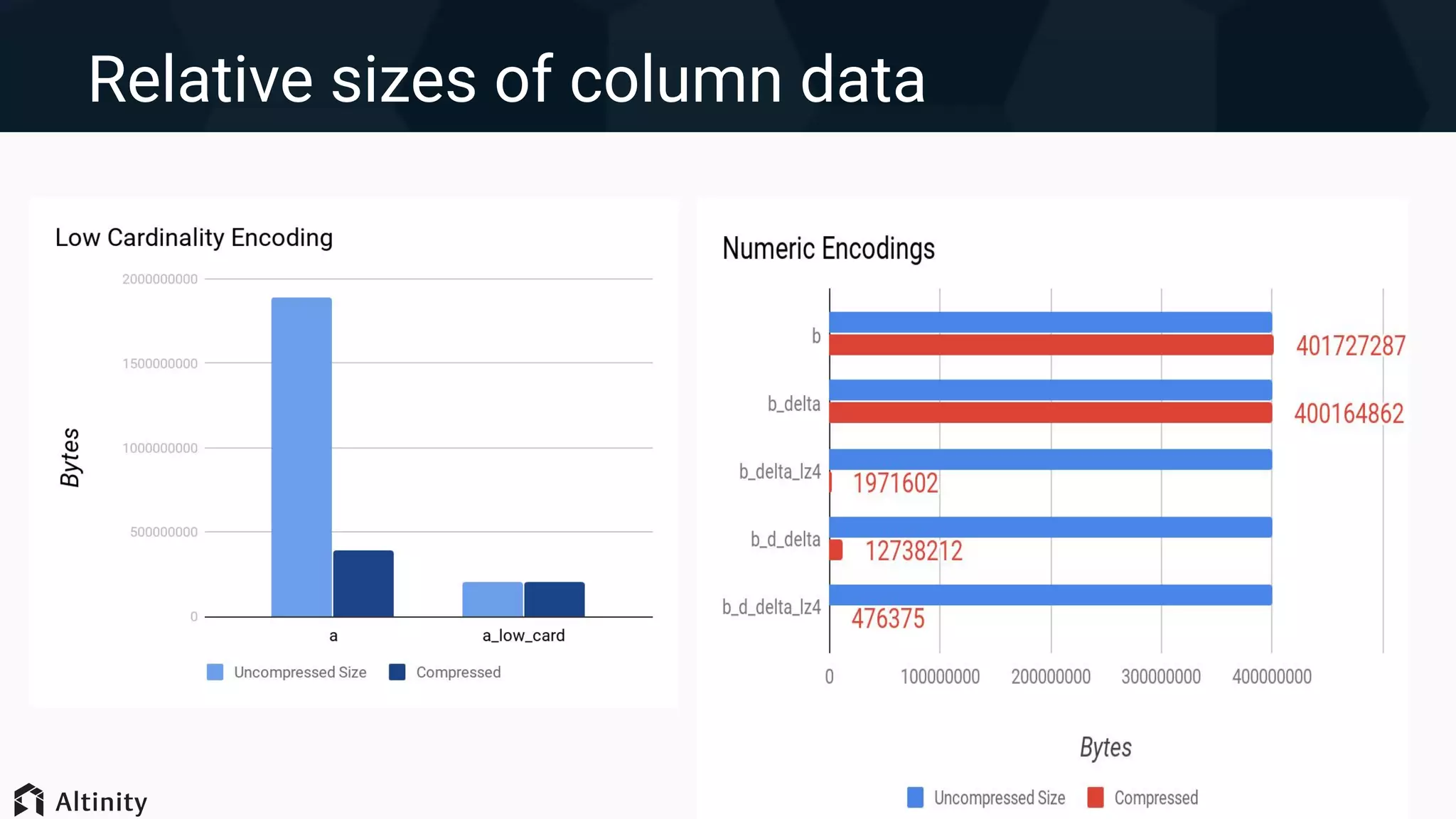
Discussion of various index types and the use of encodings to reduce data sizes and improve query times.
Strategies for using materialized views to enhance query performance and further optimizations in data handling.
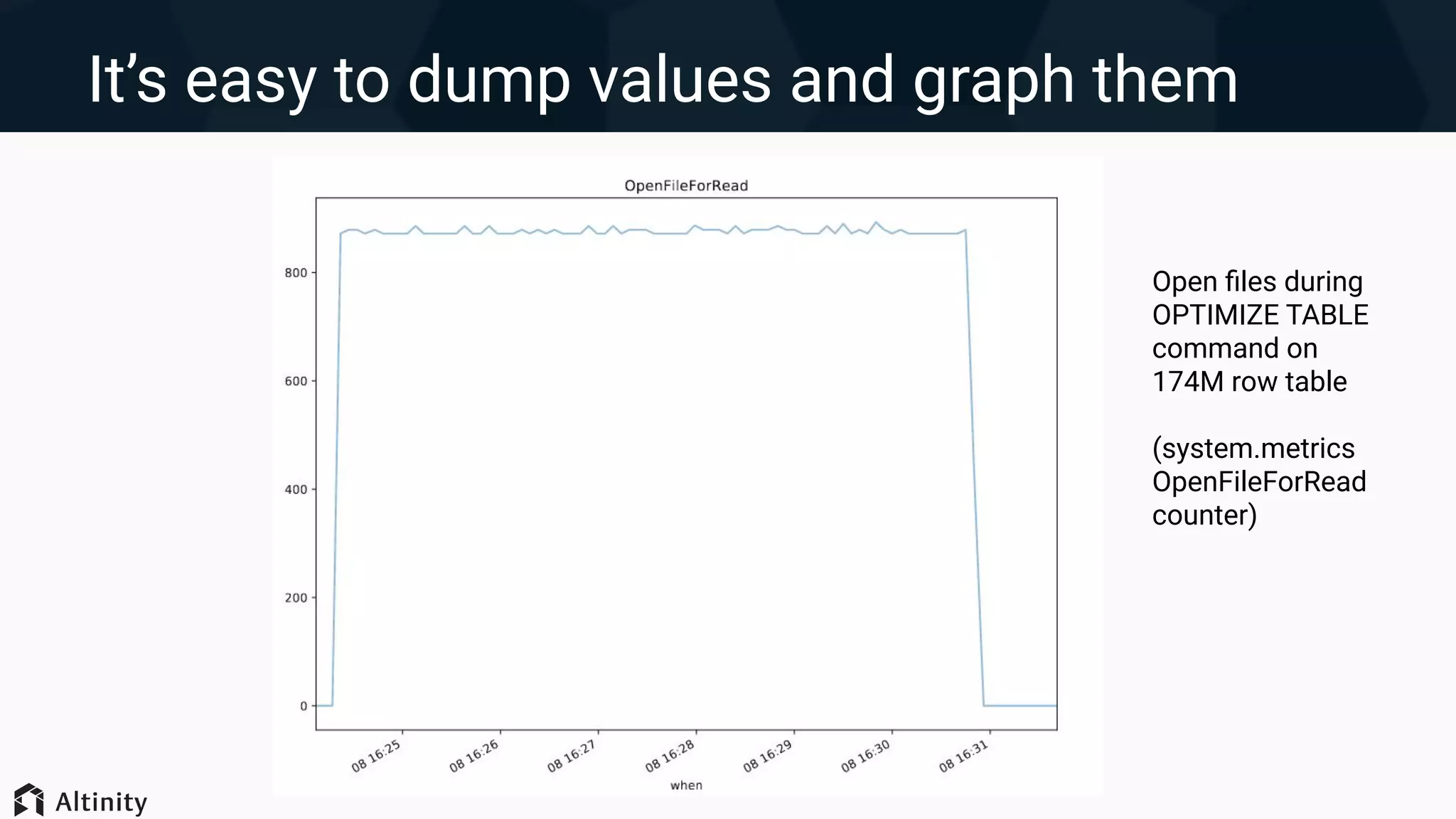
Monitoring ClickHouse performance through system metrics, query logs, and utilizing OS tools for deeper performance insights.
Summary of performance drivers in ClickHouse, importance of query optimization, and resources for further learning.
Suggestions for experimenting with ClickHouse features, such as caching for performance improvements.













































































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)









