Download as PDF, PPTX

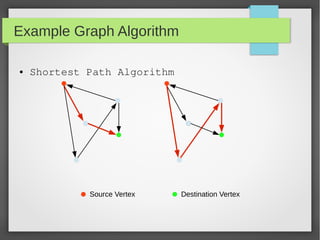


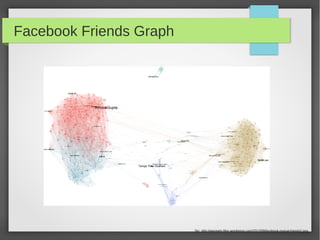


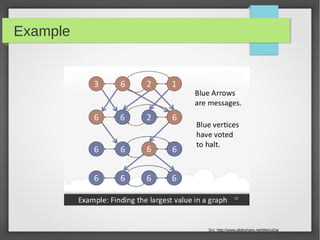




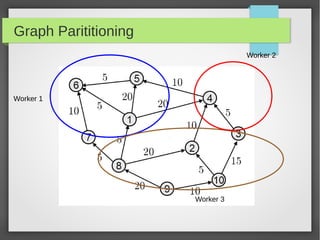

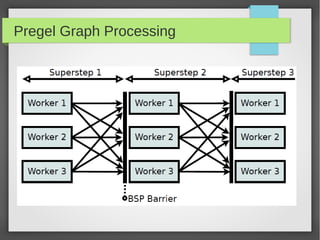







This document discusses large scale graph processing. The goal is to run graph algorithms like shortest path on huge graphs with terabytes of data that cannot fit on one machine. It introduces Pregel, Google's graph processing system from 2010 that uses a vertex-centric programming model. Pregel partitions graphs across machines and executes synchronous iterations where vertices send messages and perform computations to solve problems like PageRank. Several open source implementations of this model now exist like Apache Giraph and GraphLab.



































































