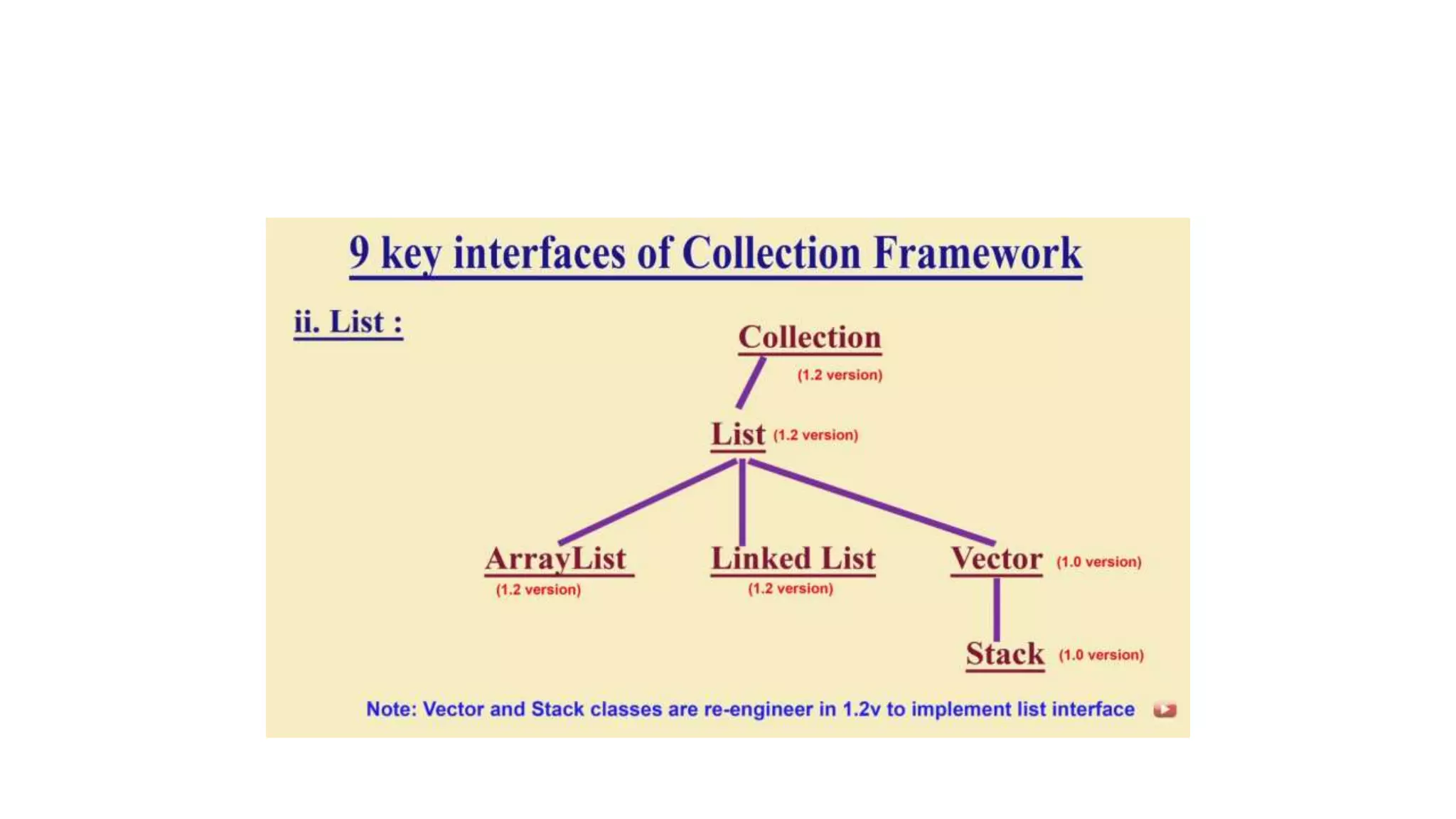
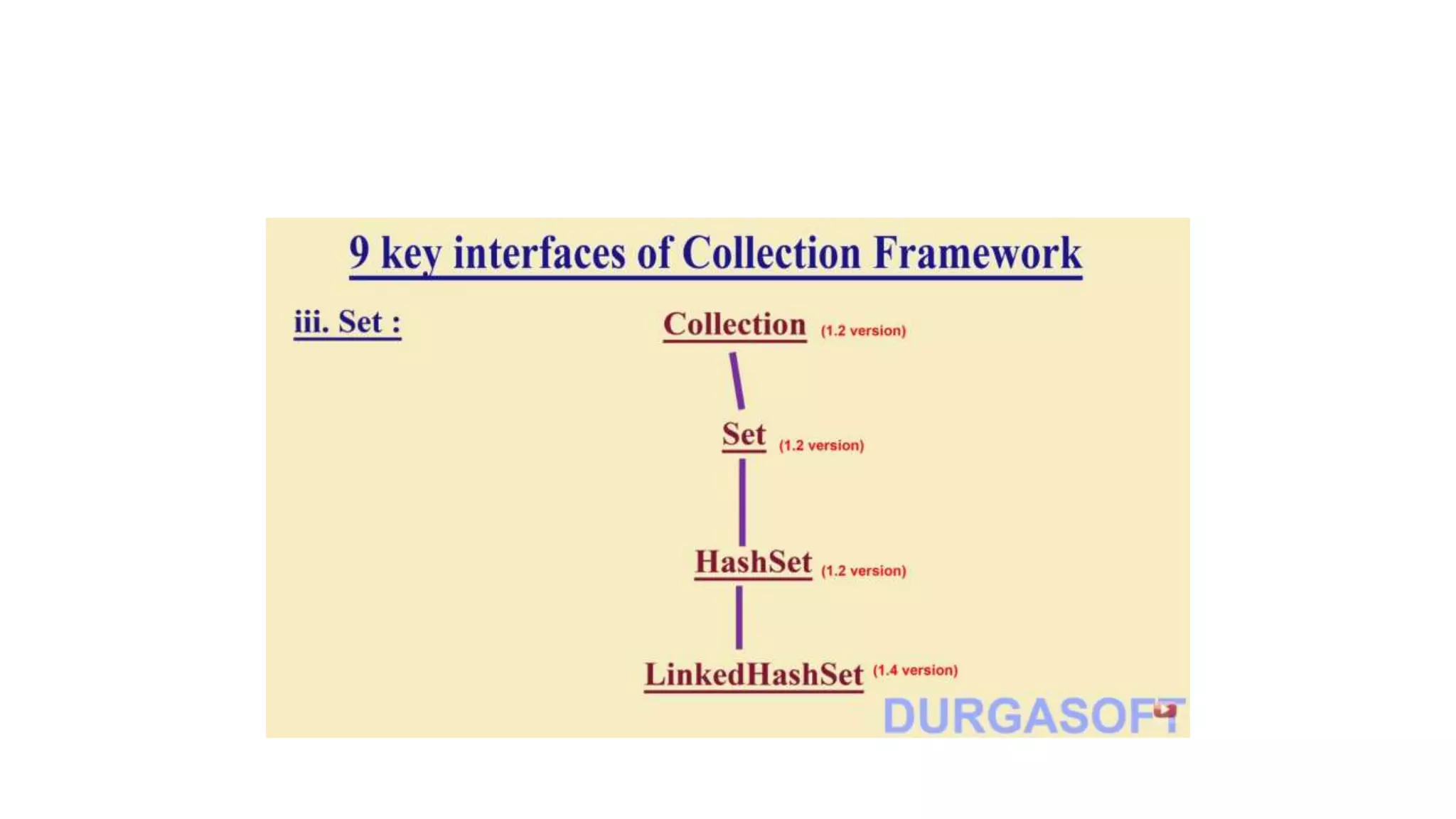
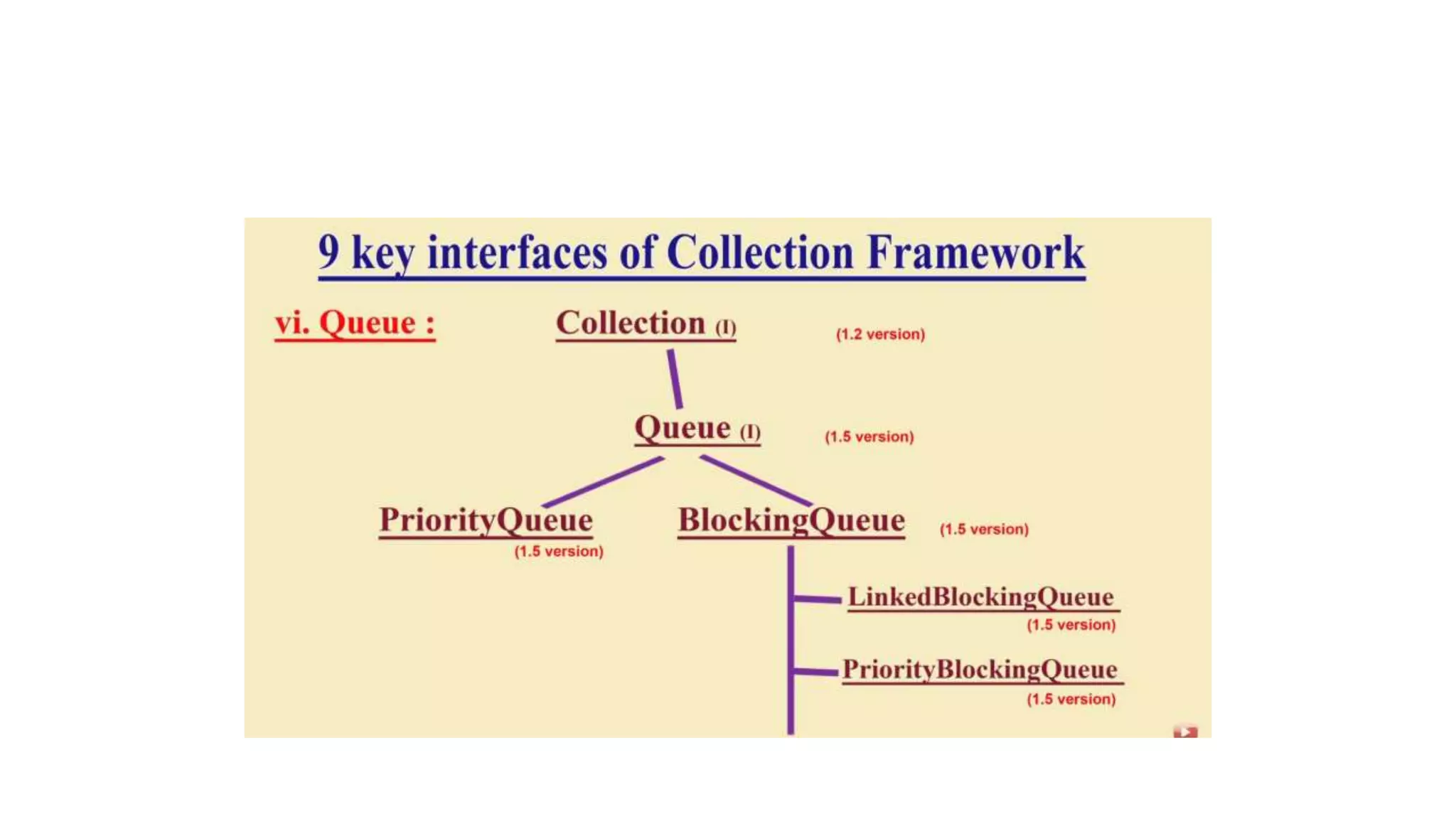
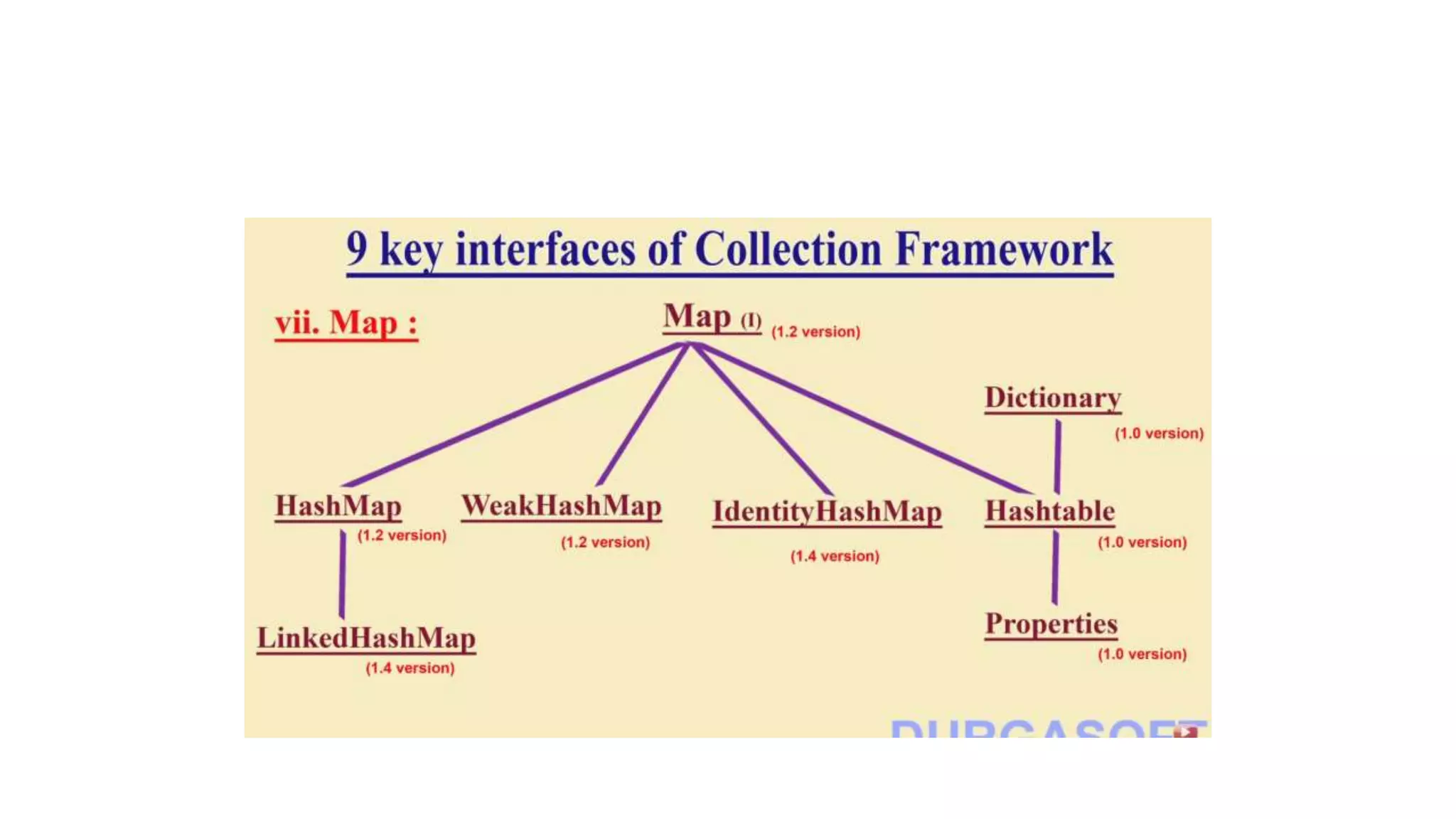
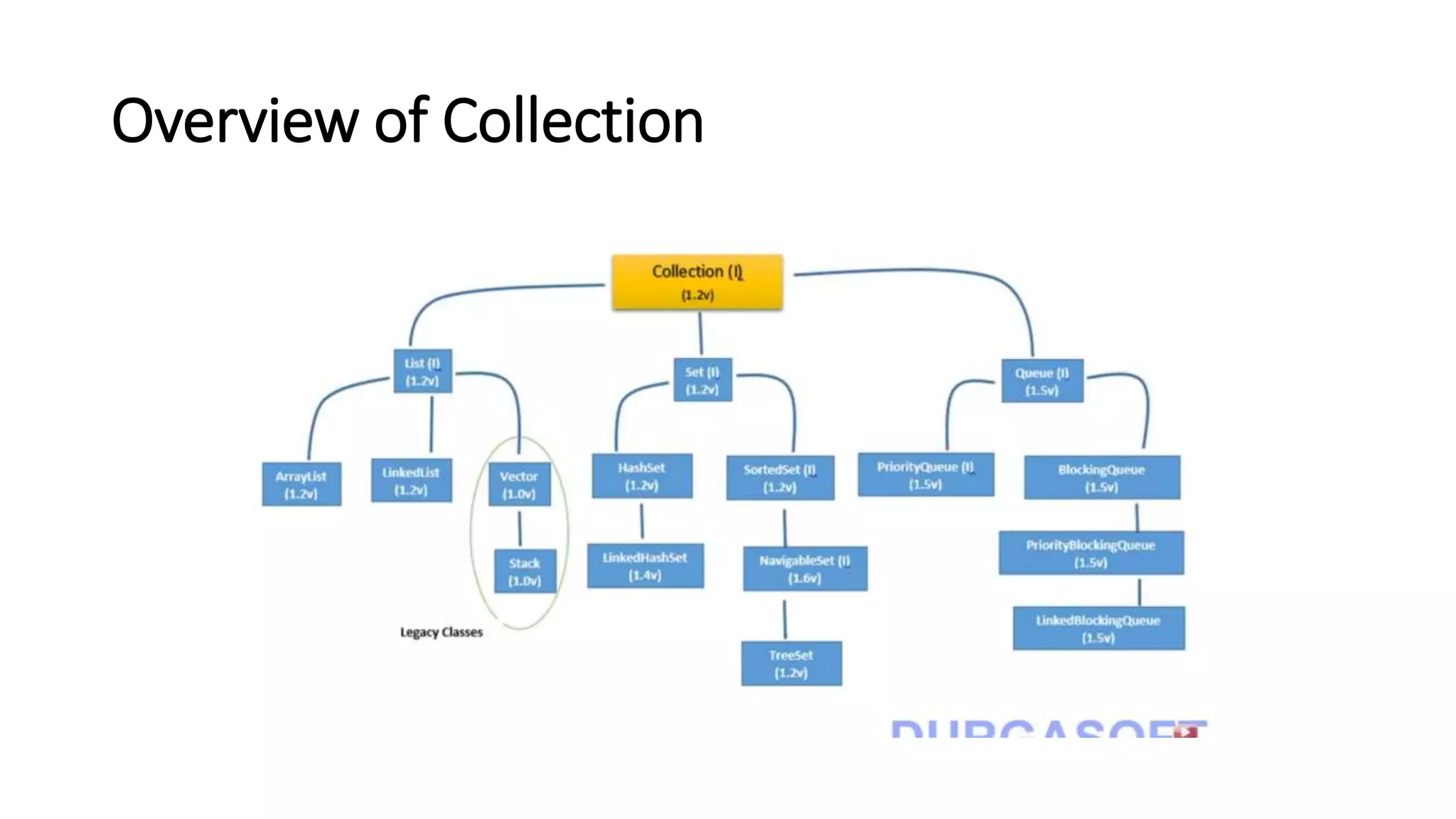
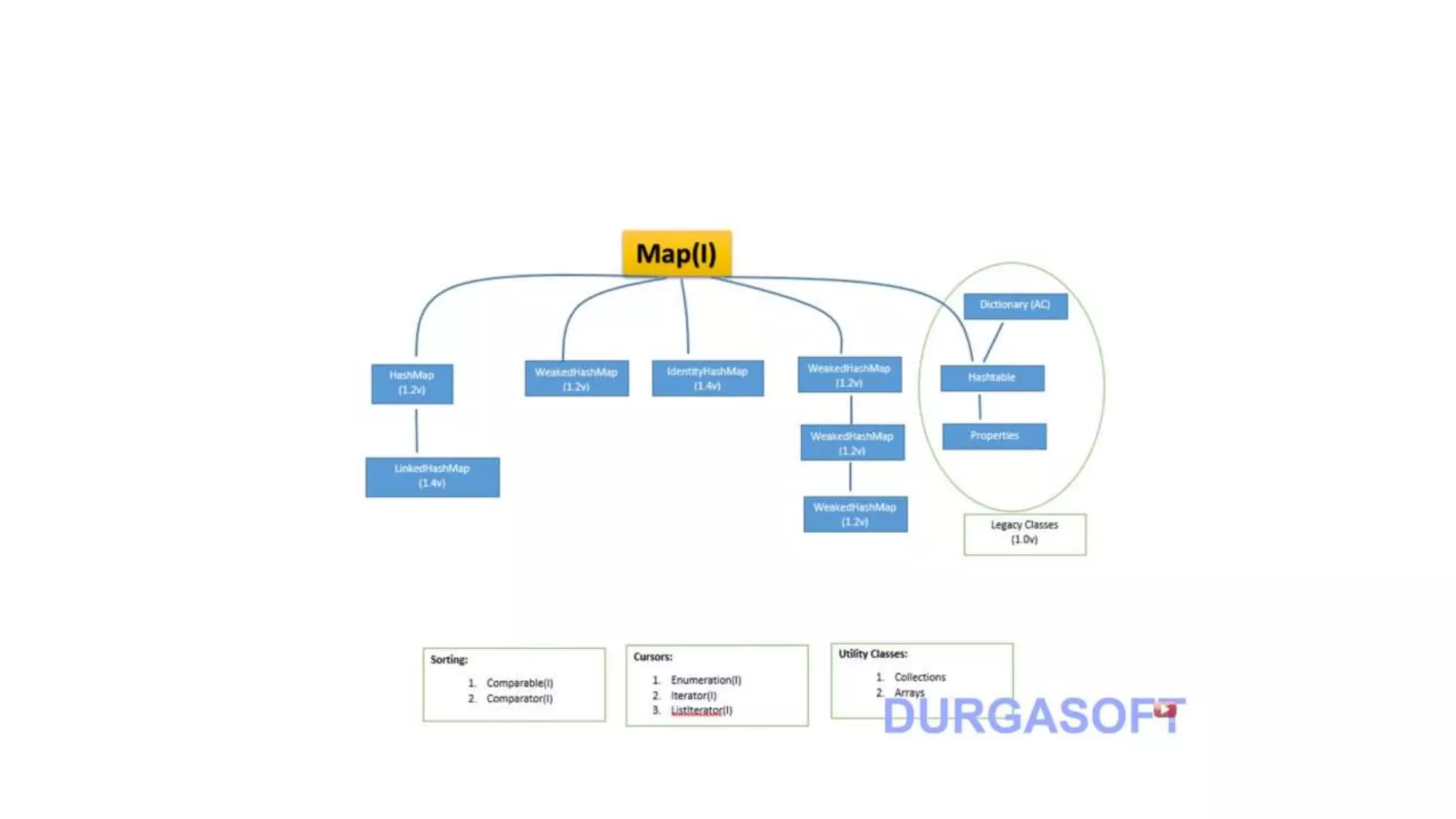
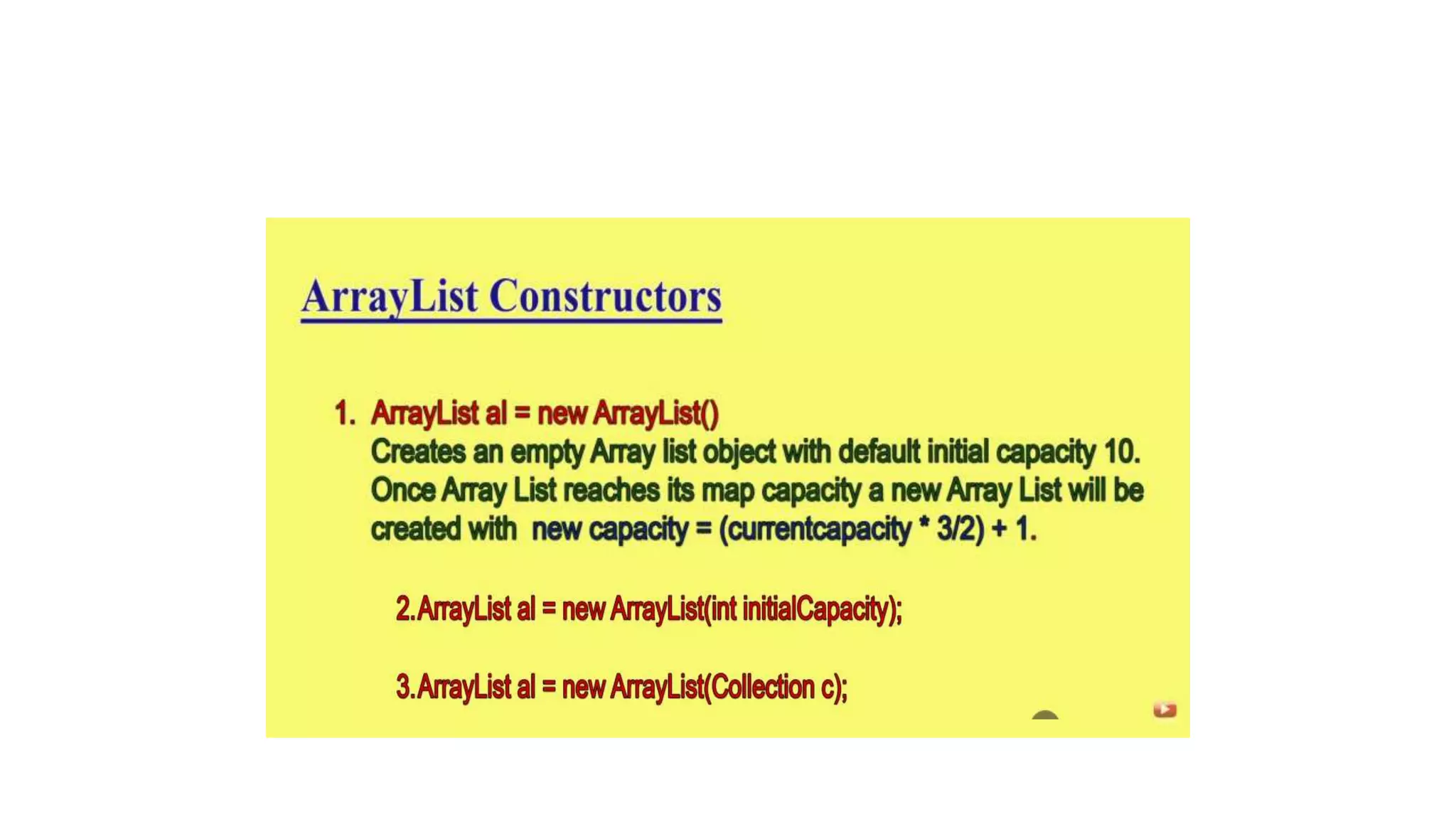
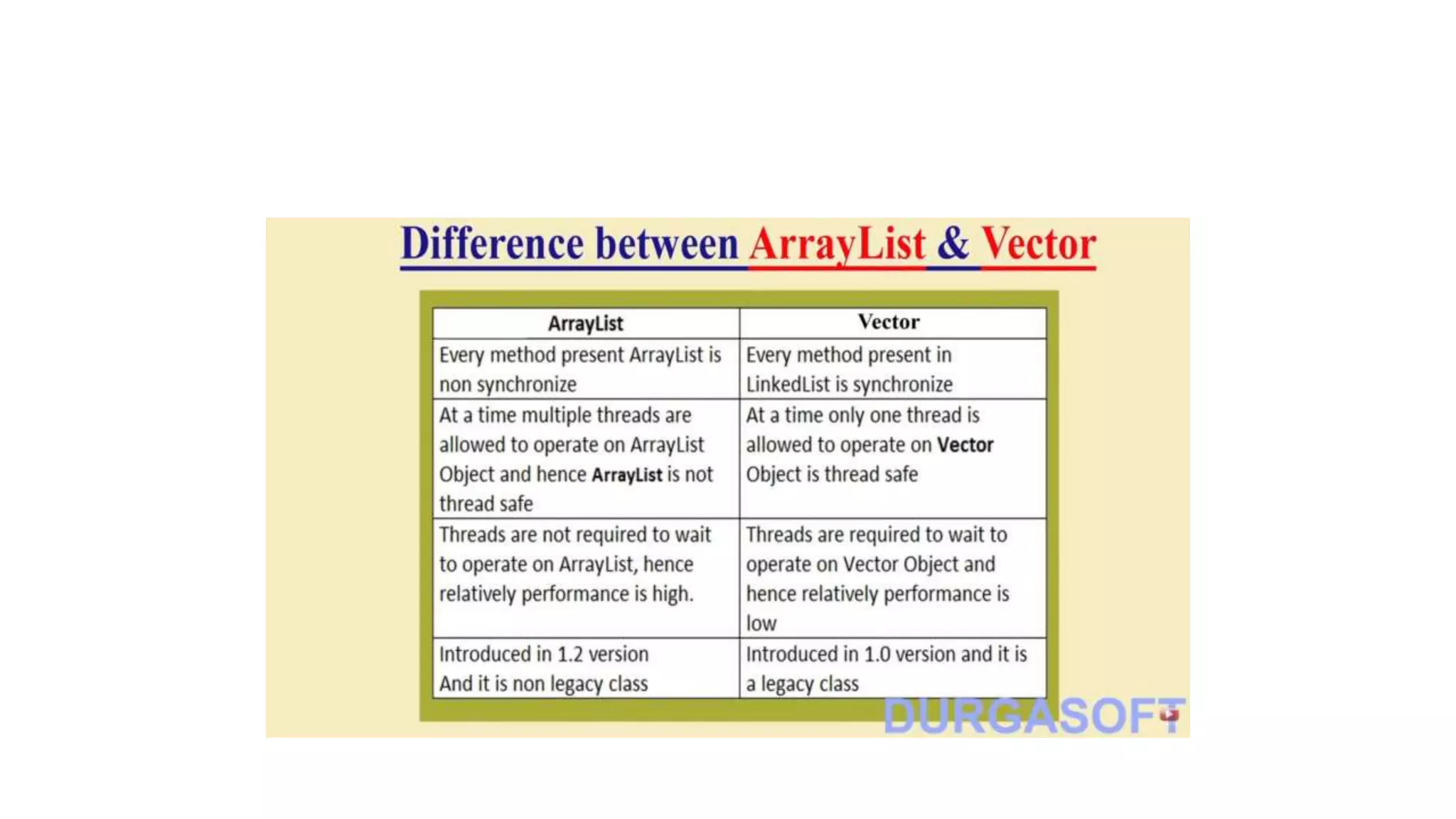
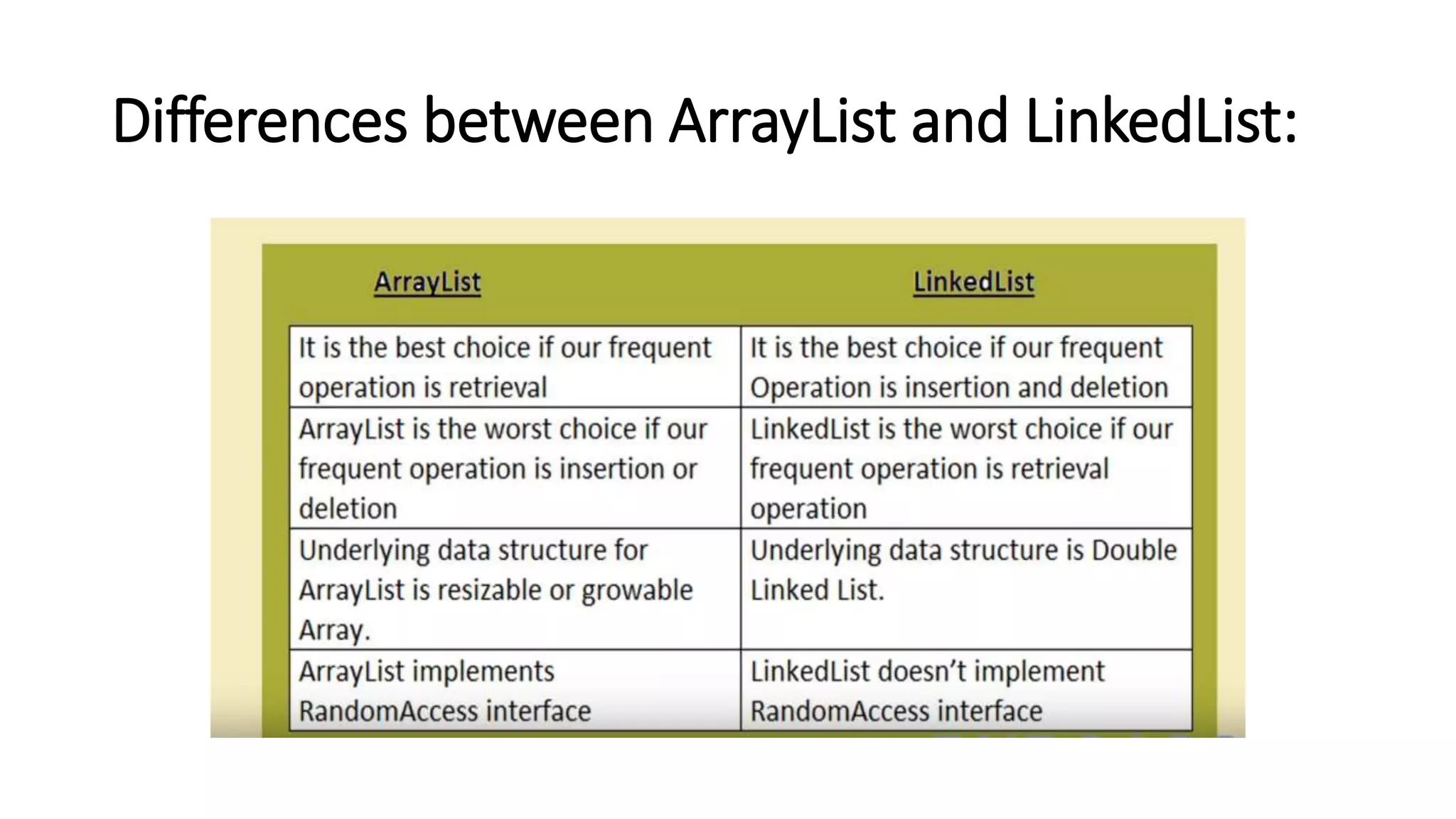
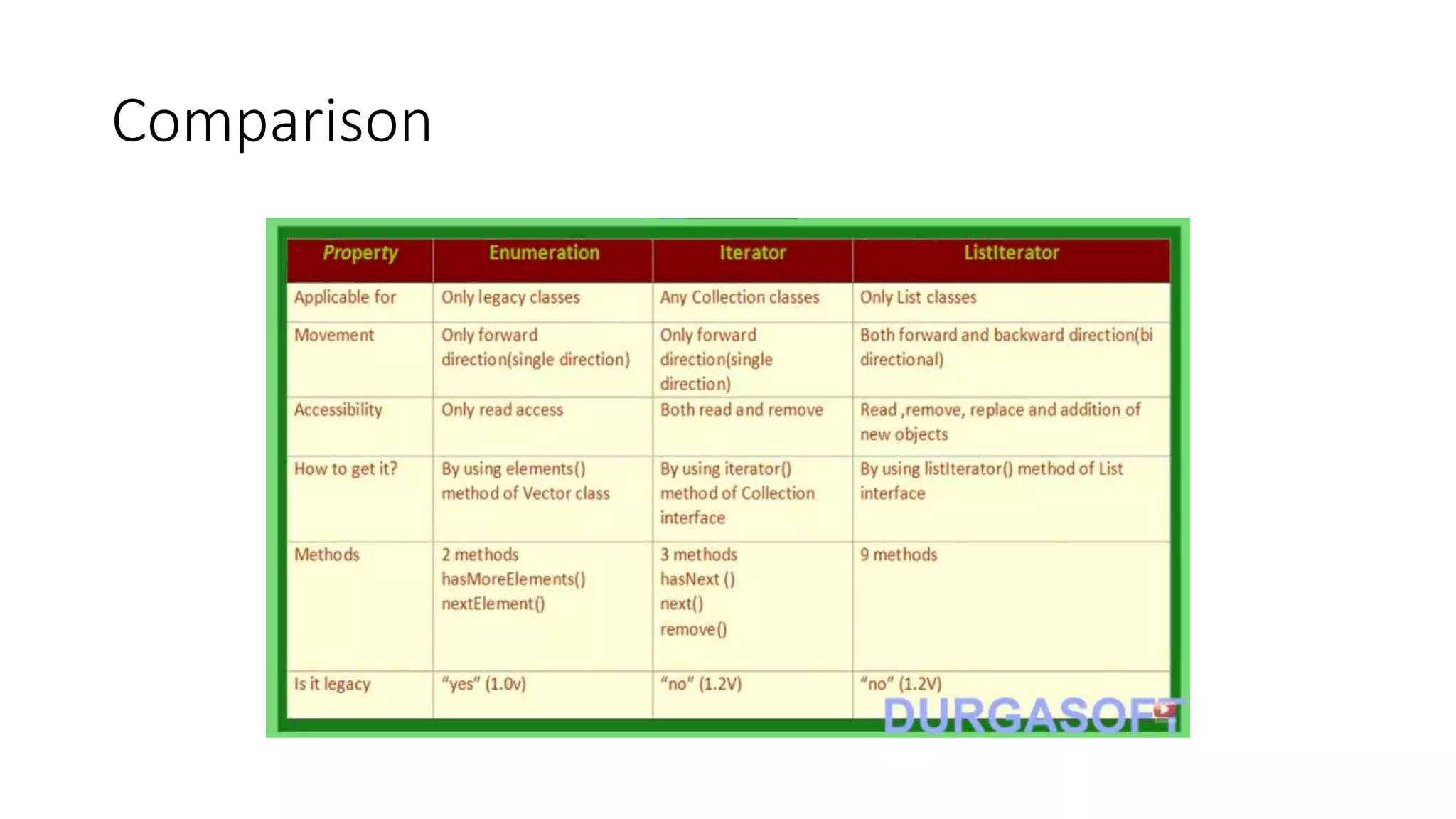
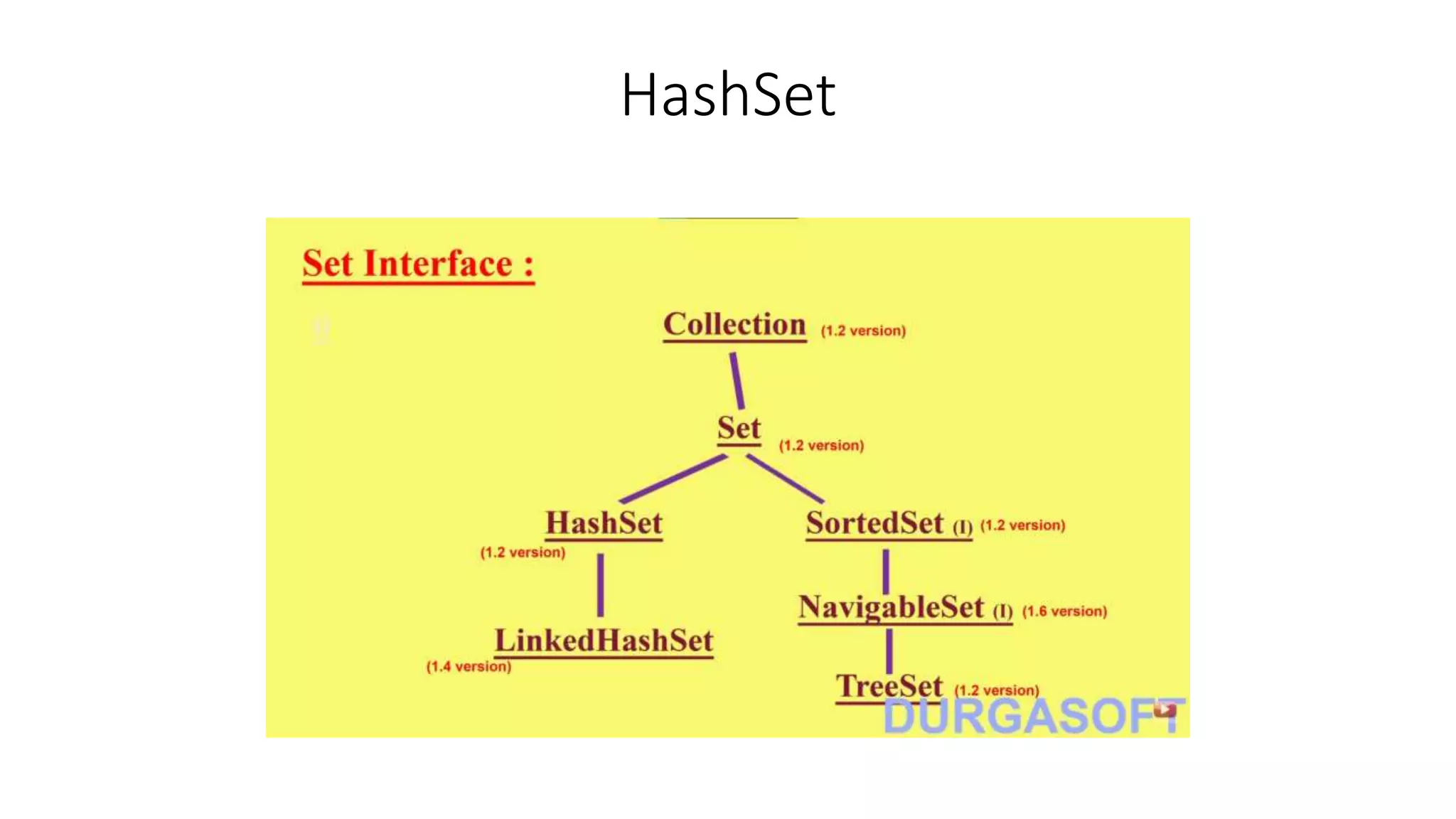
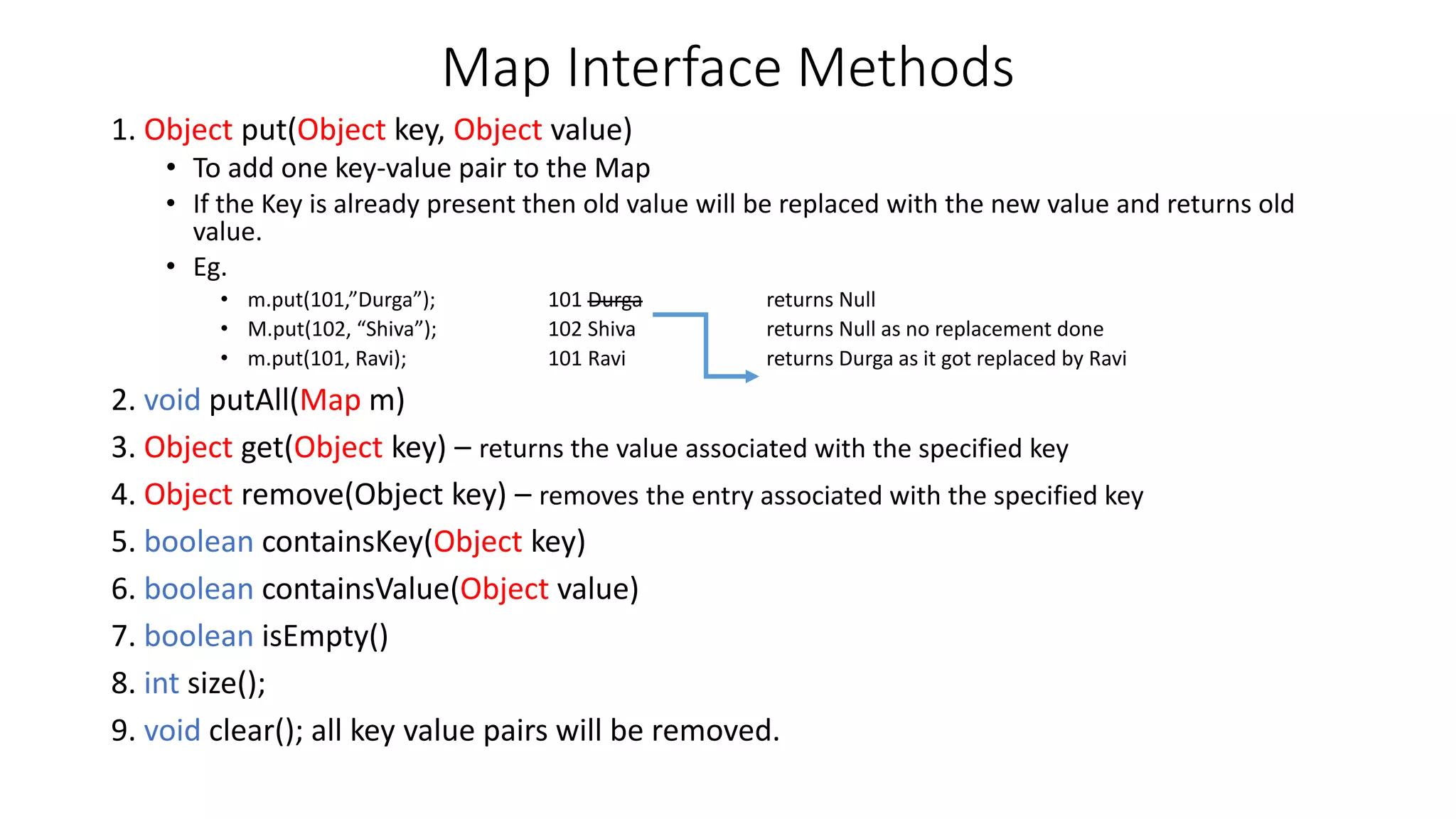
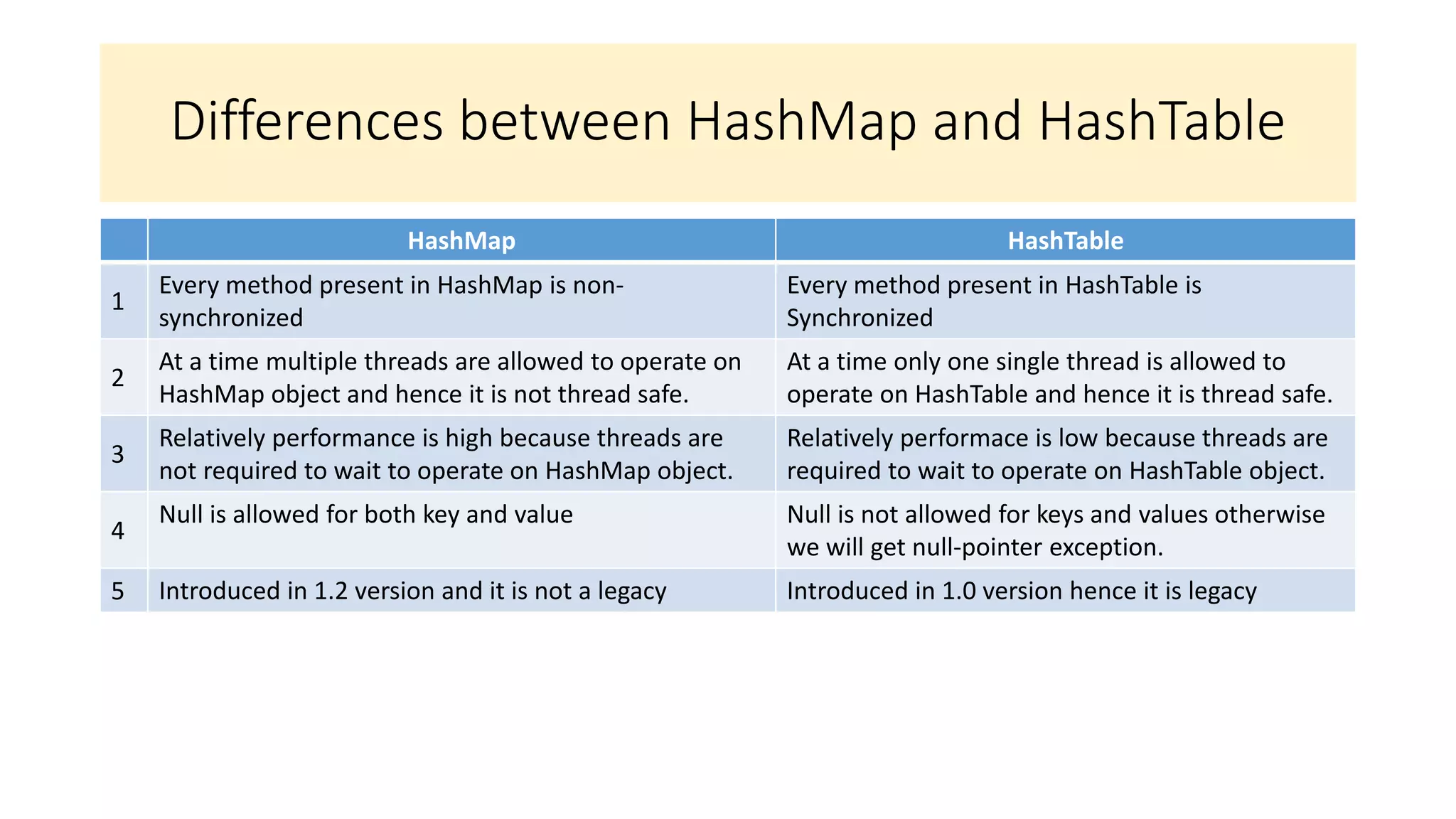
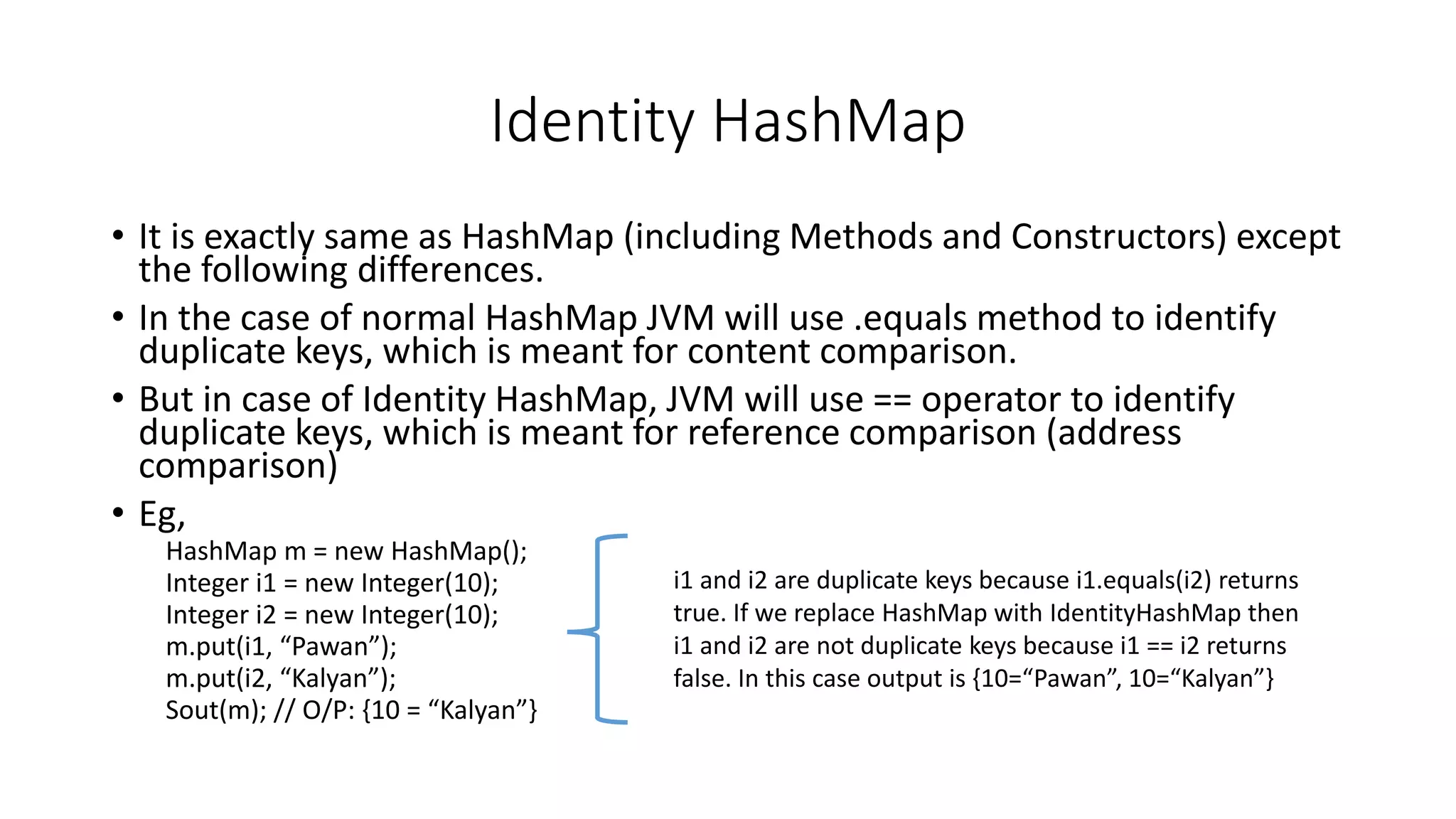
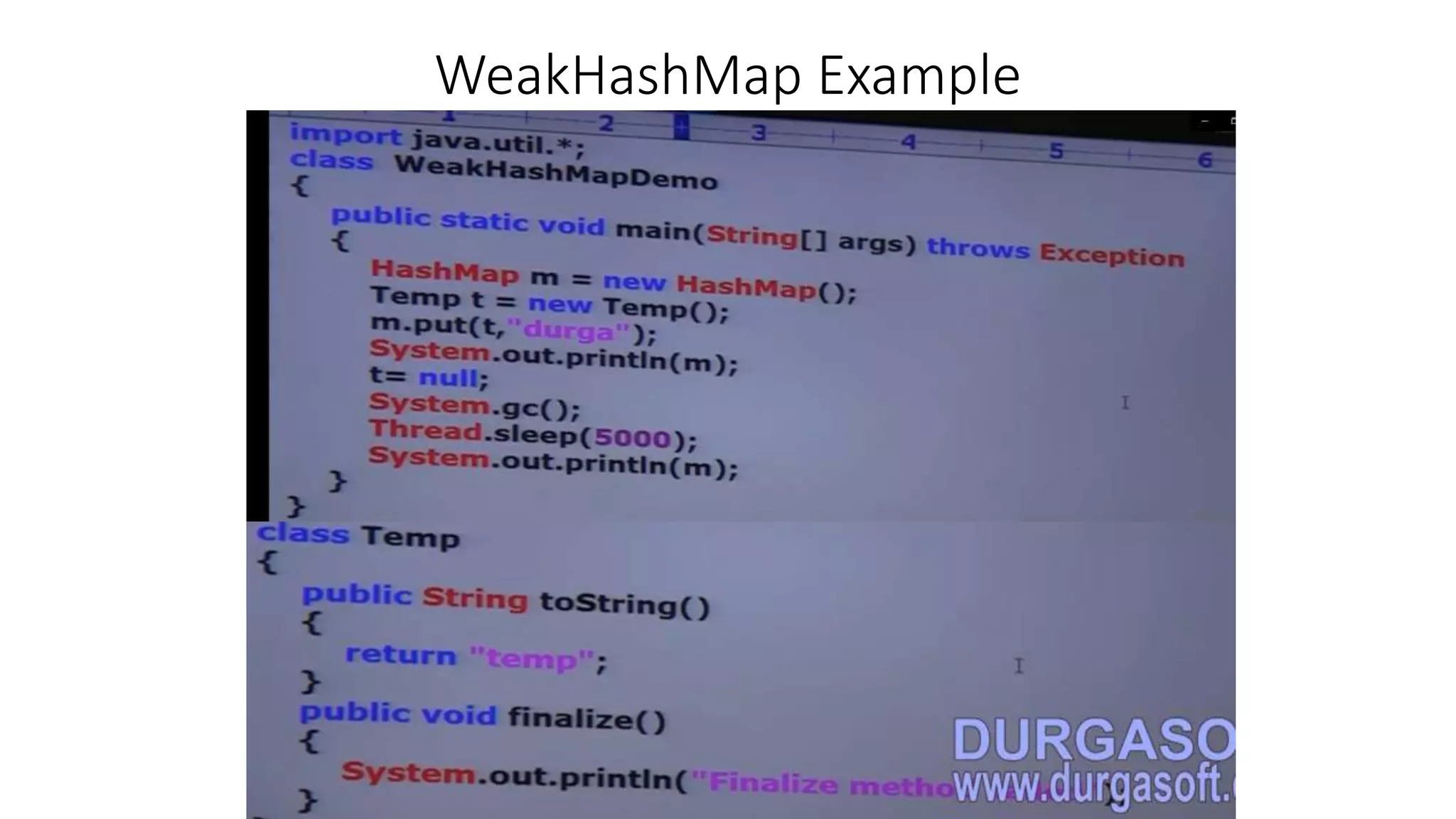
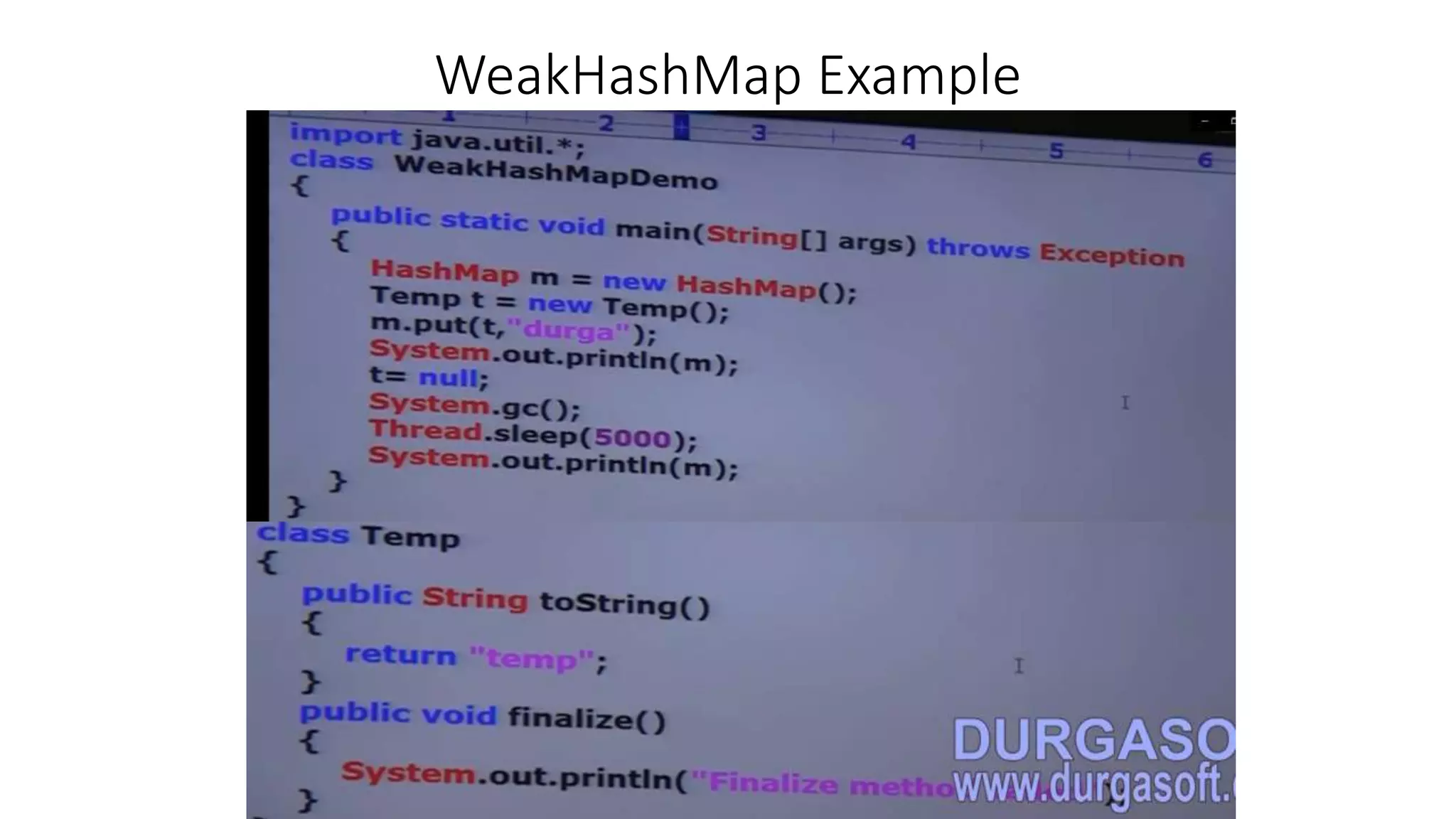
This document provides an overview of Java collections and key interfaces in the collection framework. It discusses Collection, List, Set, SortedSet, Queue, Map interfaces and their implementations like ArrayList, LinkedList, HashSet, TreeSet, PriorityQueue, HashMap, TreeMap. It covers differences between various collections, constructors, methods, and examples. Key differences between implementations like ArrayList vs LinkedList, HashMap vs HashTable are explained. Concepts like iterators, comparators are also summarized.