Downloaded 518 times


























This document is a PowerPoint presentation on machine learning (ML), outlining its definitions, types (supervised, unsupervised, semi-supervised, and reinforcement learning), and key concepts like features and labels. It also details the steps involved in the ML process, including data collection, preparation, model selection, training, evaluation, parameter tuning, and making predictions. The applications of ML in various fields, such as spam detection and fraud detection, are highlighted along with its increasing importance in imitating human learning.
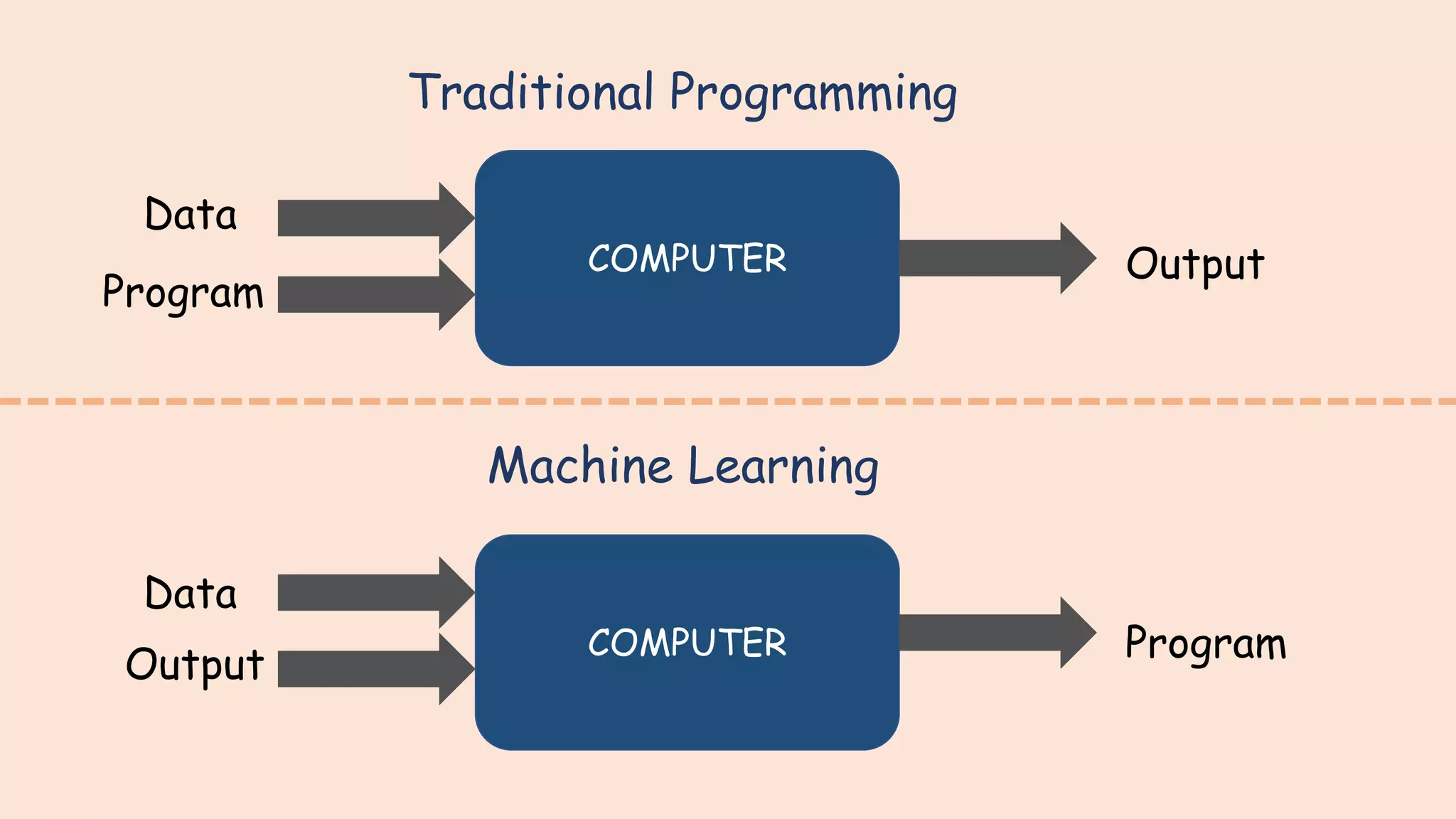
Overview of machine learning and its definitions, emphasizing its applications and data-driven nature.
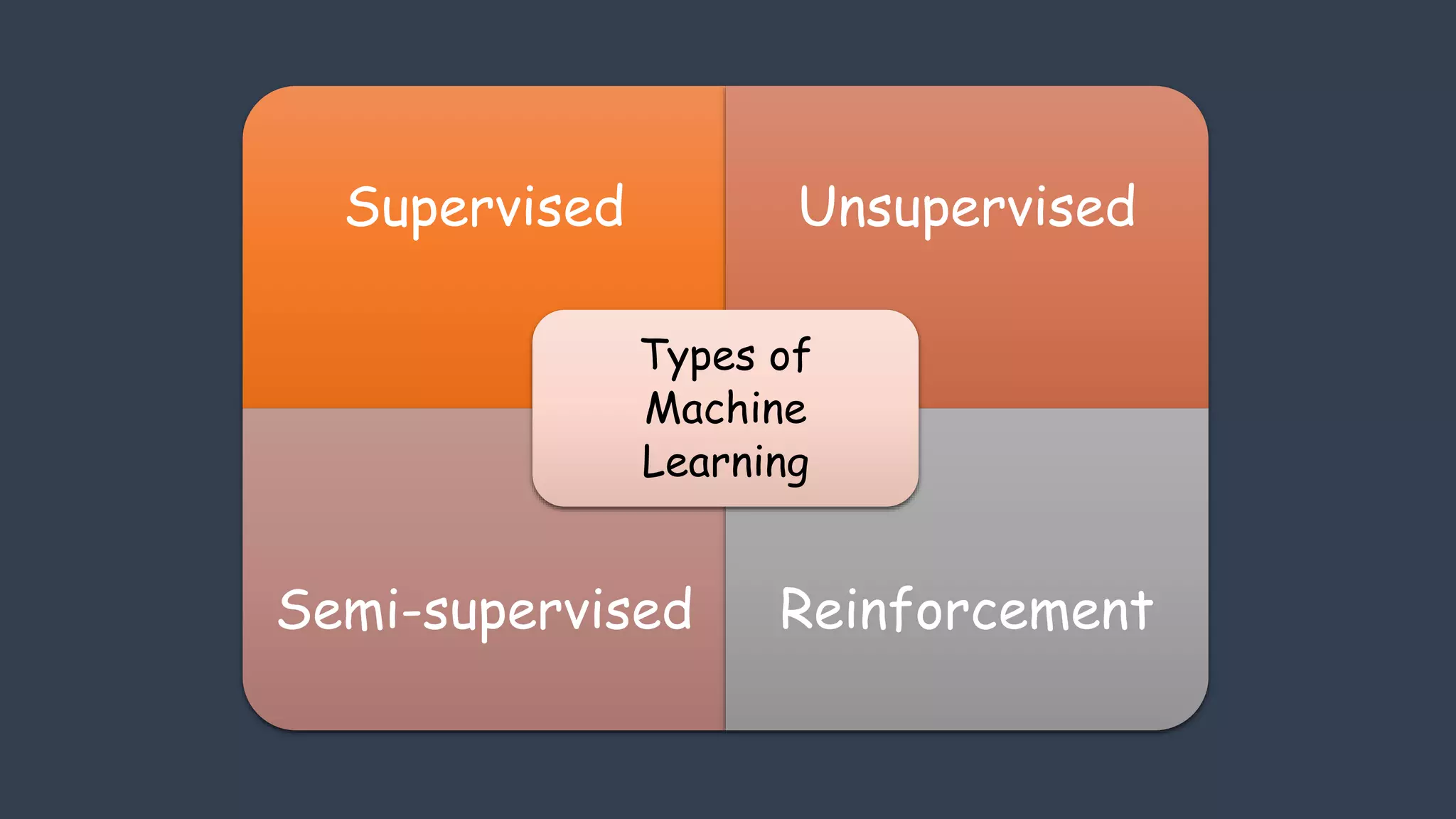
Explains four types: Supervised, Unsupervised, Semi-supervised, and Reinforcement learning, with advantages and disadvantages for each.
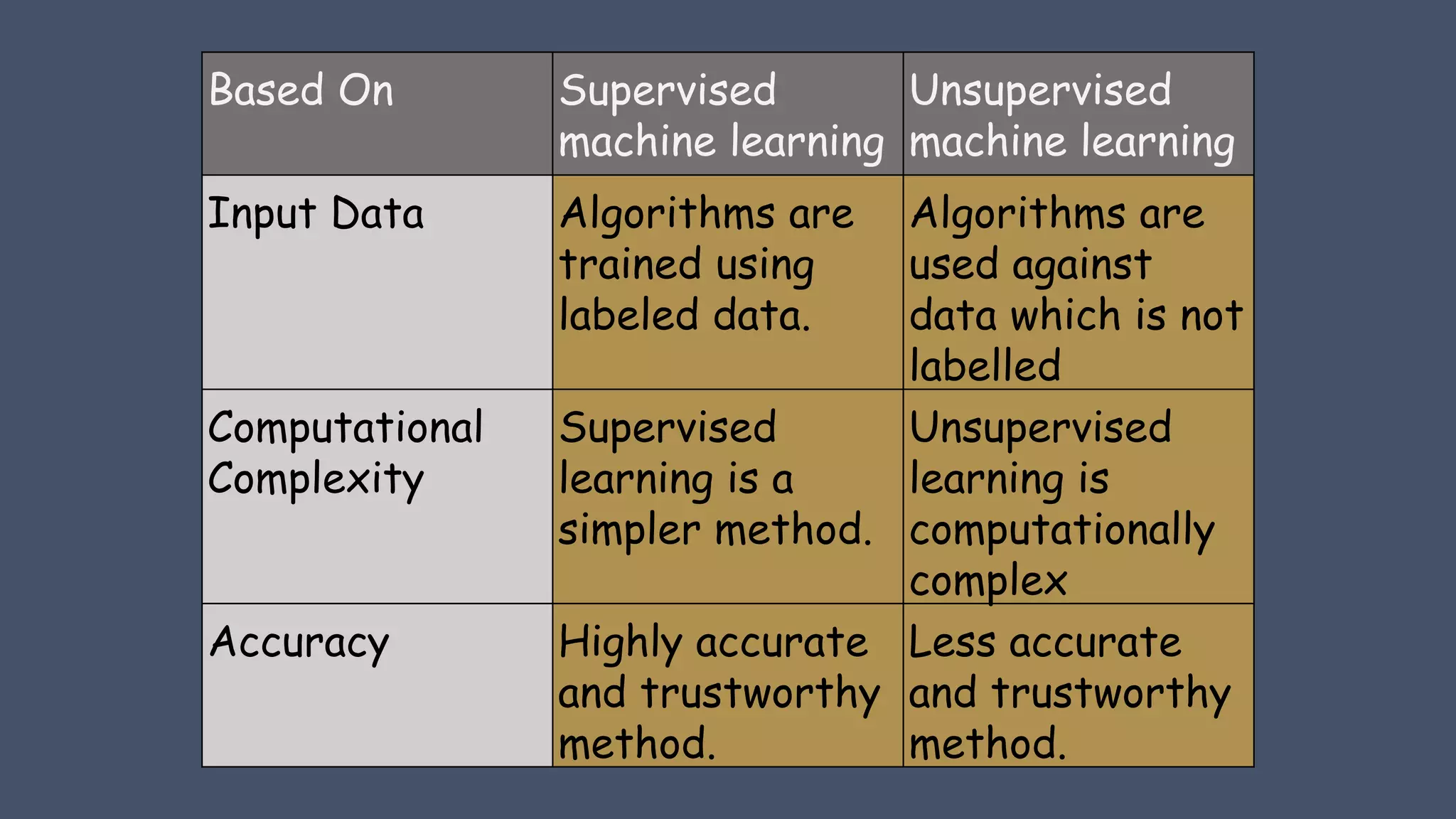
Comparison of supervised and unsupervised learning in terms of input data, complexity, and accuracy.
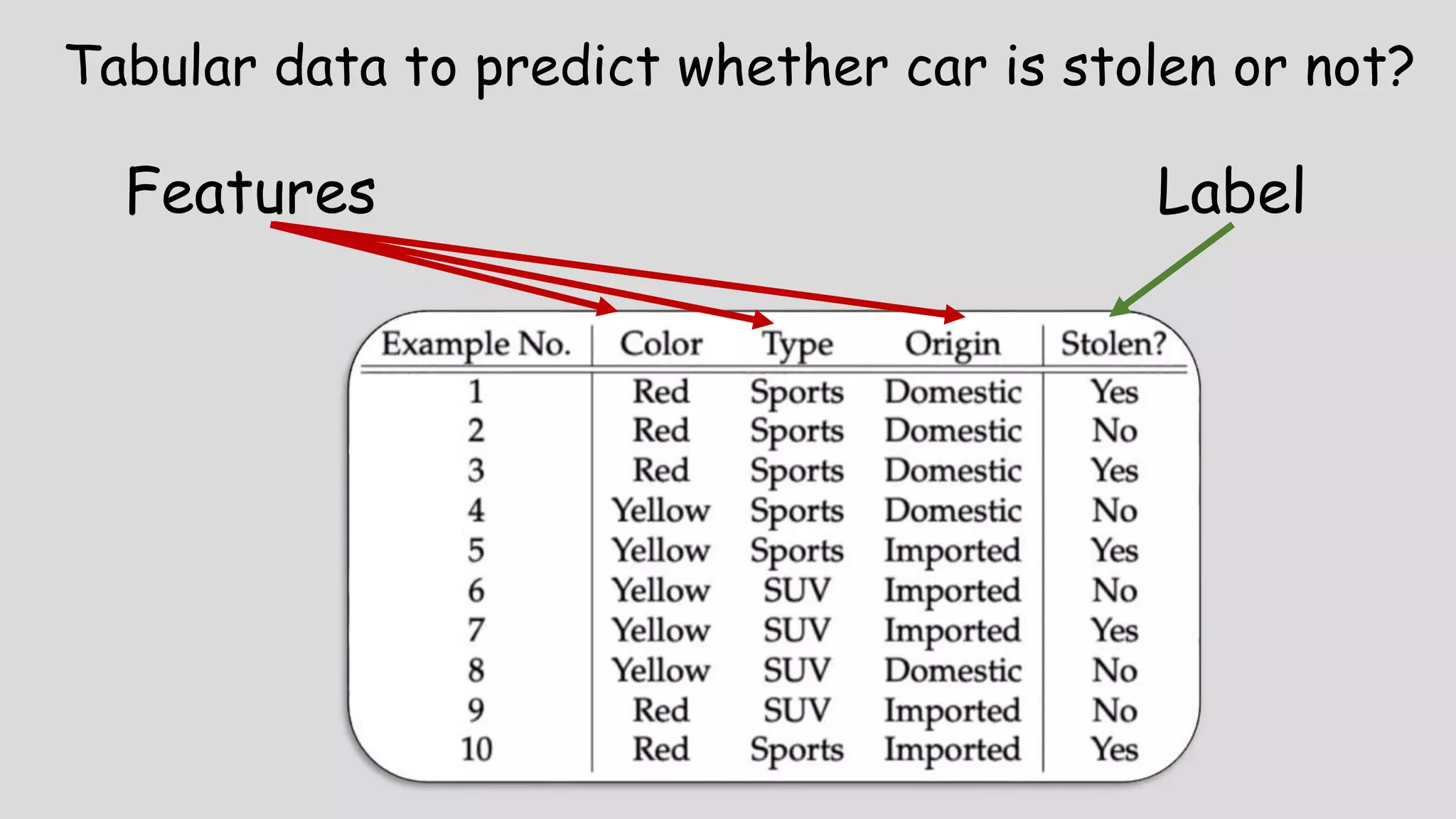
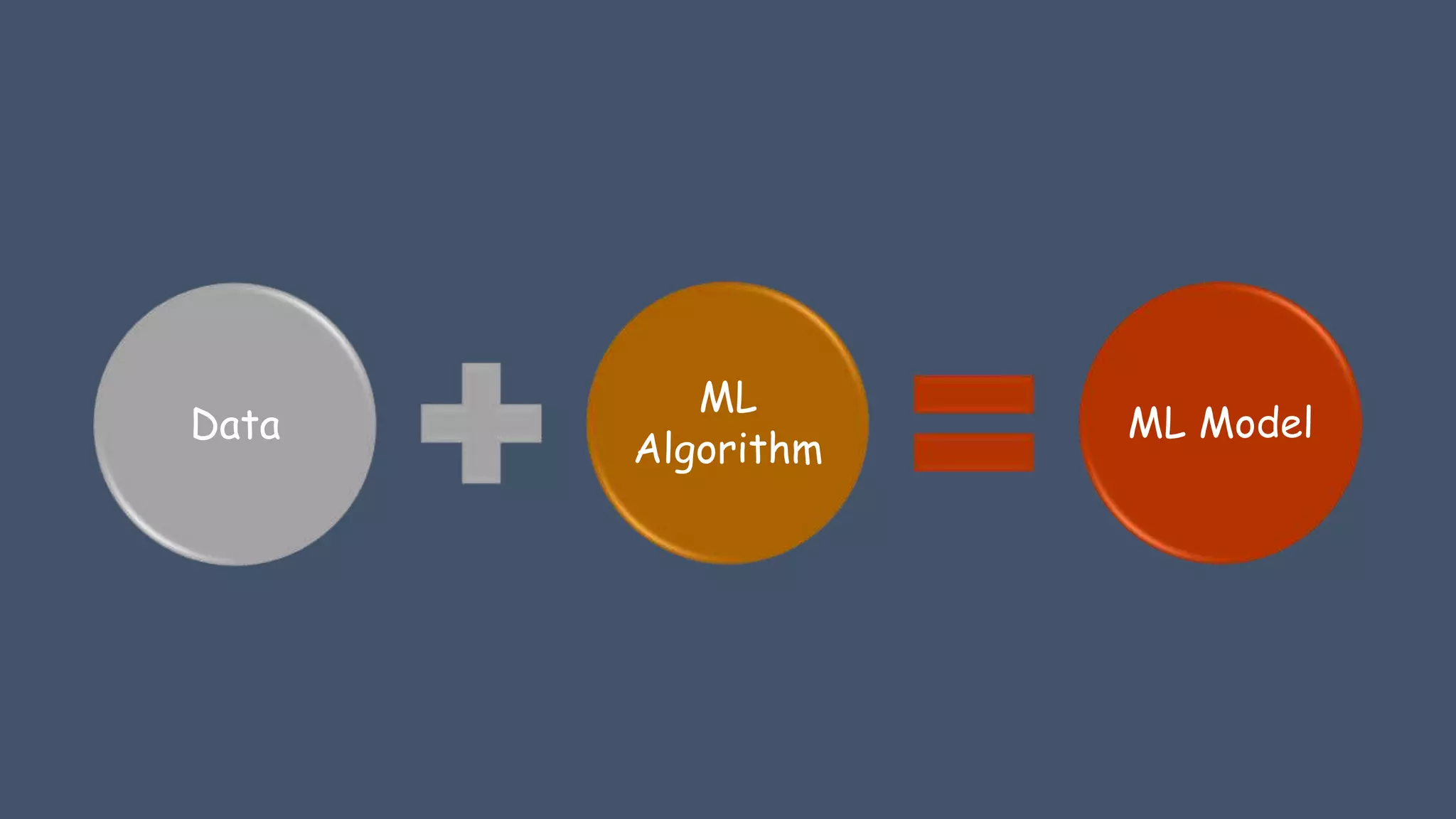
Describes goals of ML to identify patterns in data, along with key terms such as features, labels, and models.
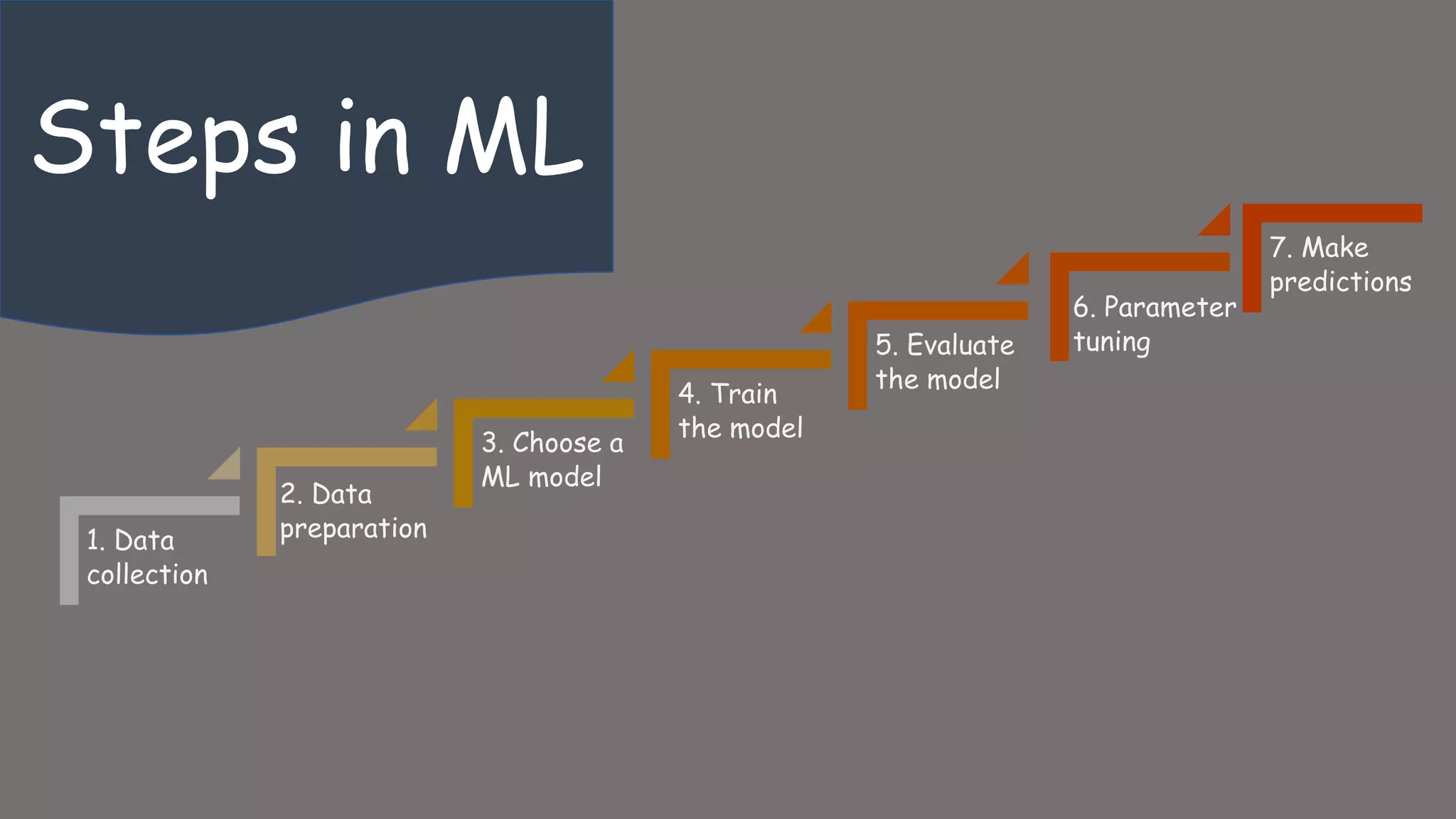
Details the steps in the ML process from data collection, preparation, to training, evaluating, tuning, and making predictions.
Highlights various fields where ML is applied, including traffic alerts, social media, and self-driving cars.
Thanks for attending the presentation by Swati Tripathi, encouraging further exploration of ML.





































![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)



































