Downloaded 19 times



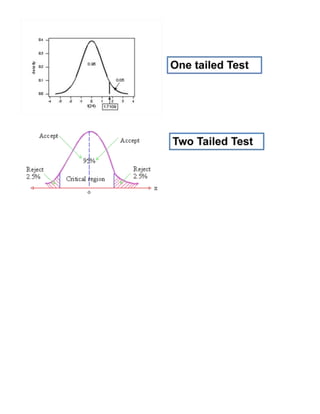

Inferential statistics allow researchers to draw conclusions about populations based on data from samples. They estimate population parameters and test hypotheses about populations that extend beyond the sample data. Hypothesis testing provides objective criteria for deciding whether to accept or reject research hypotheses as true or false based on the probability that any observed differences are due to chance. It involves selecting a test statistic, significance level, computing the test statistic, and comparing it to critical values to determine whether to reject the null hypothesis. Type I and Type II errors can occur but the significance level controls the risk of Type I errors.













































































