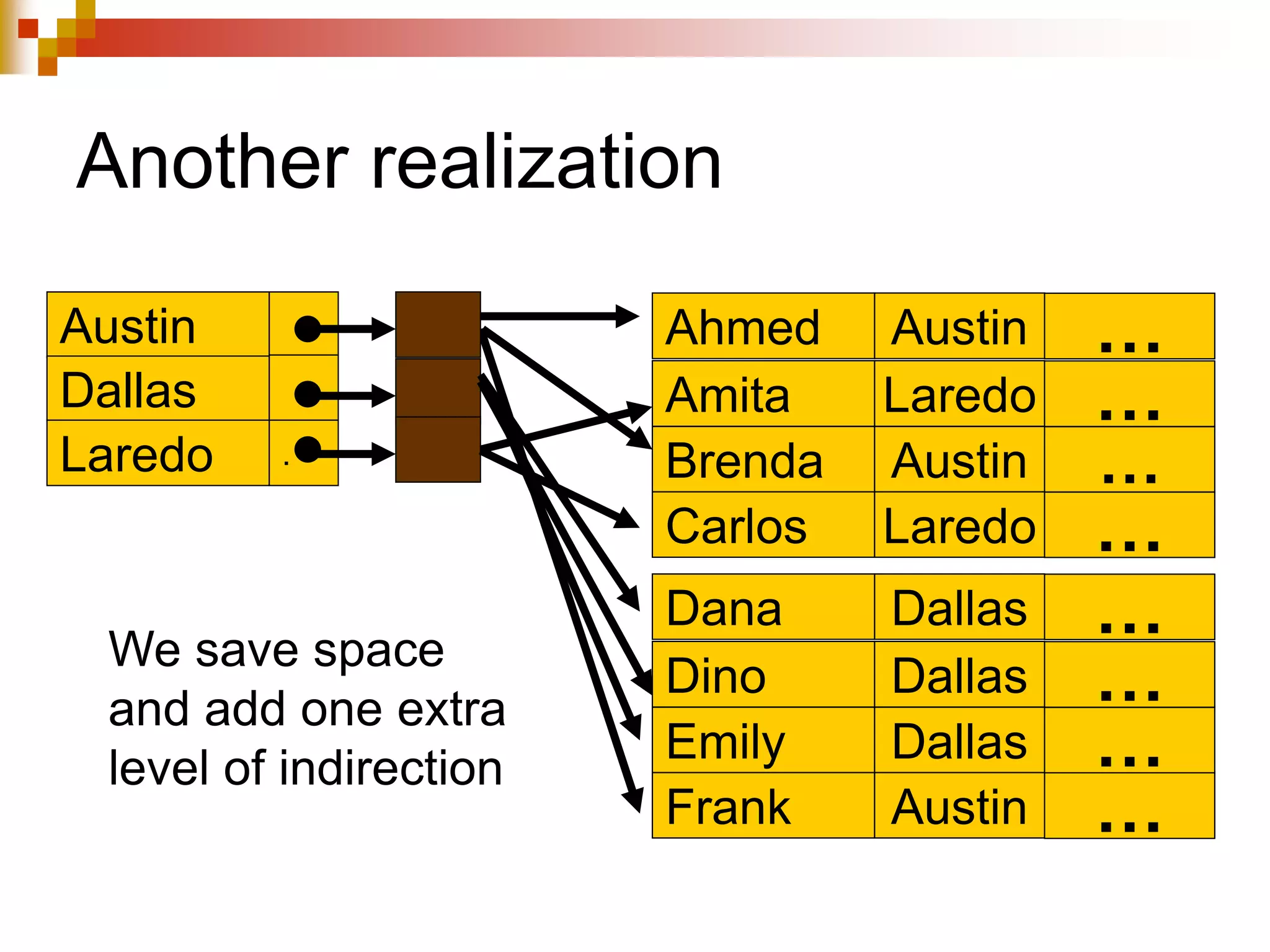
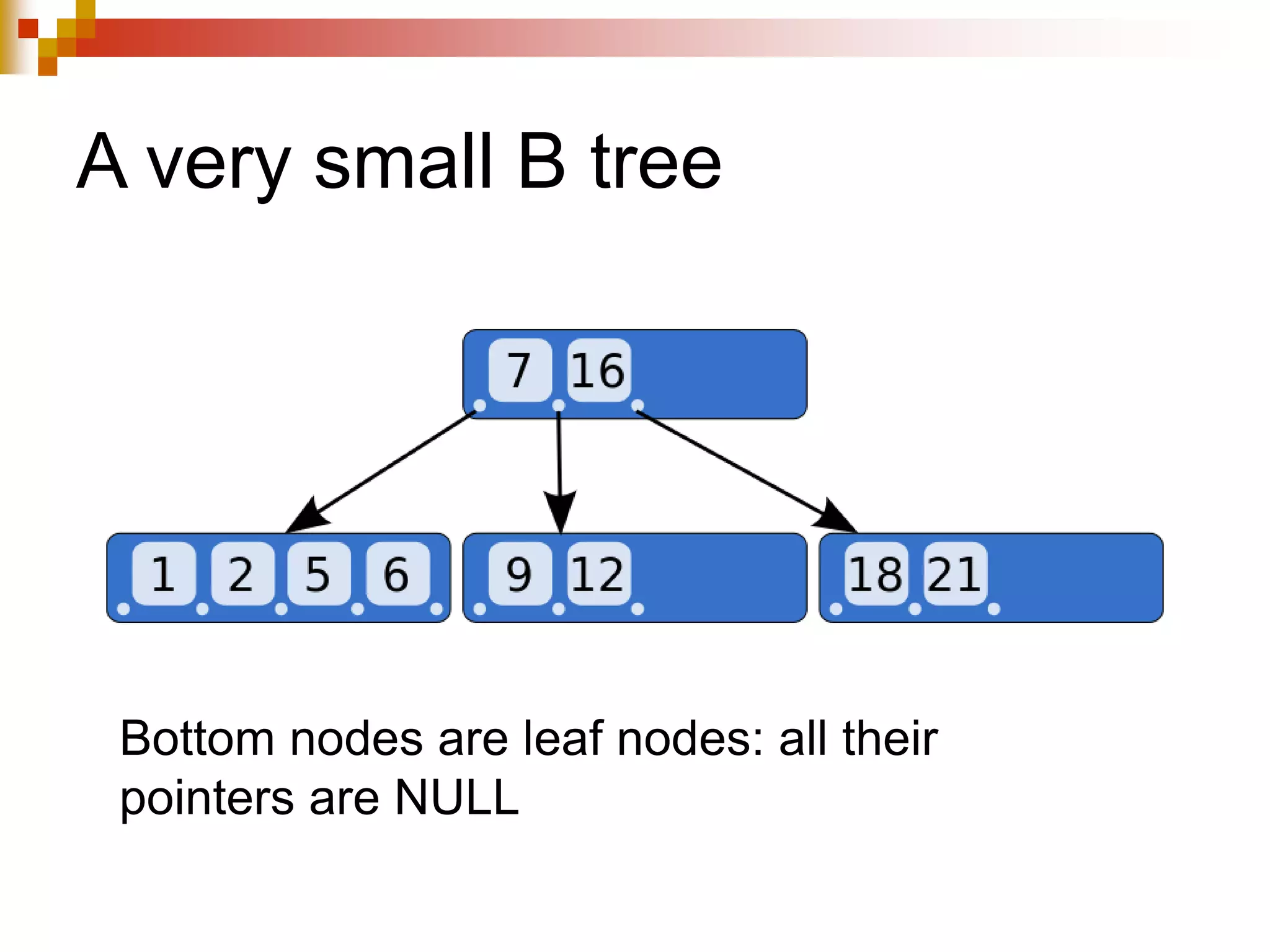
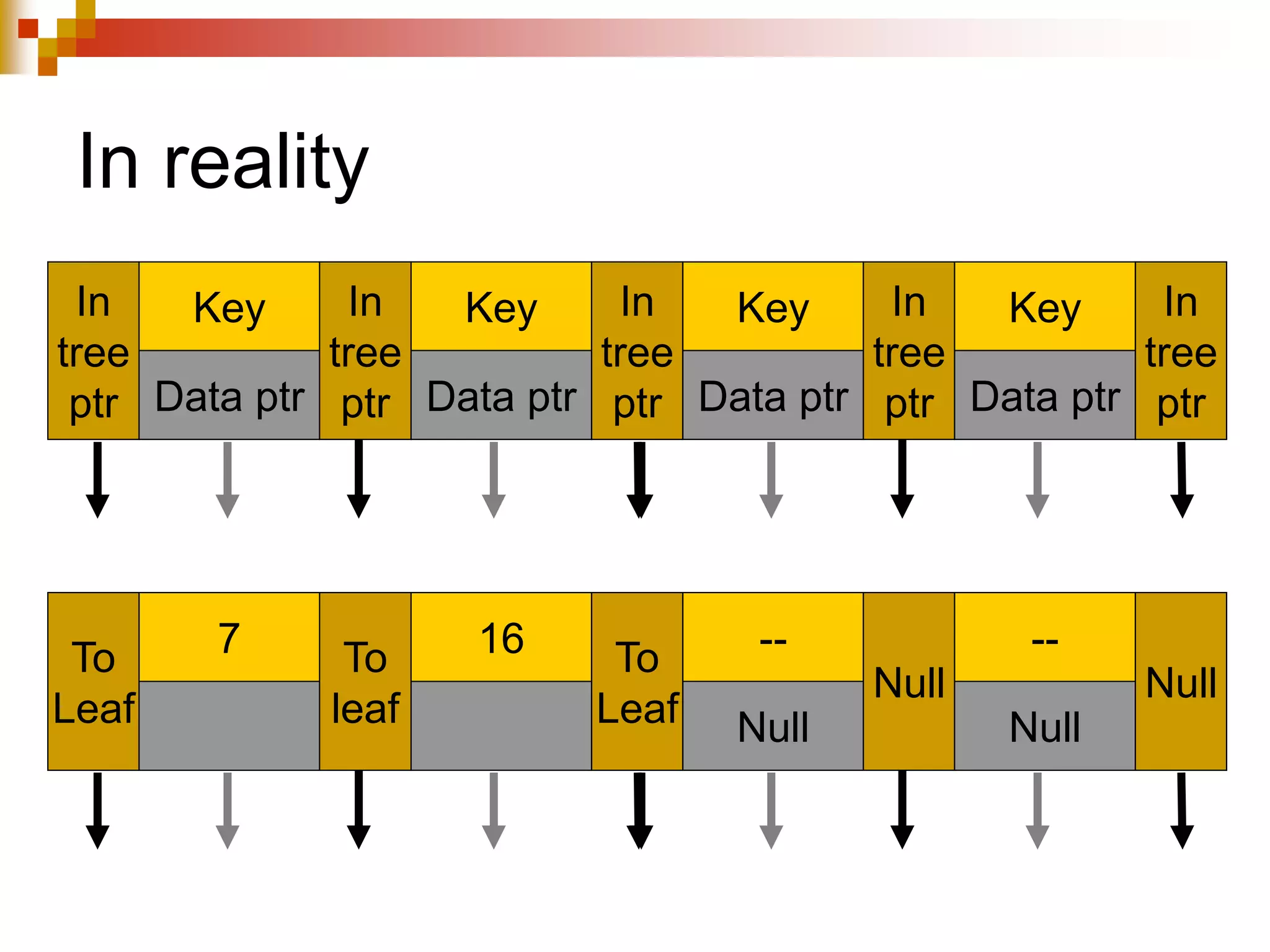
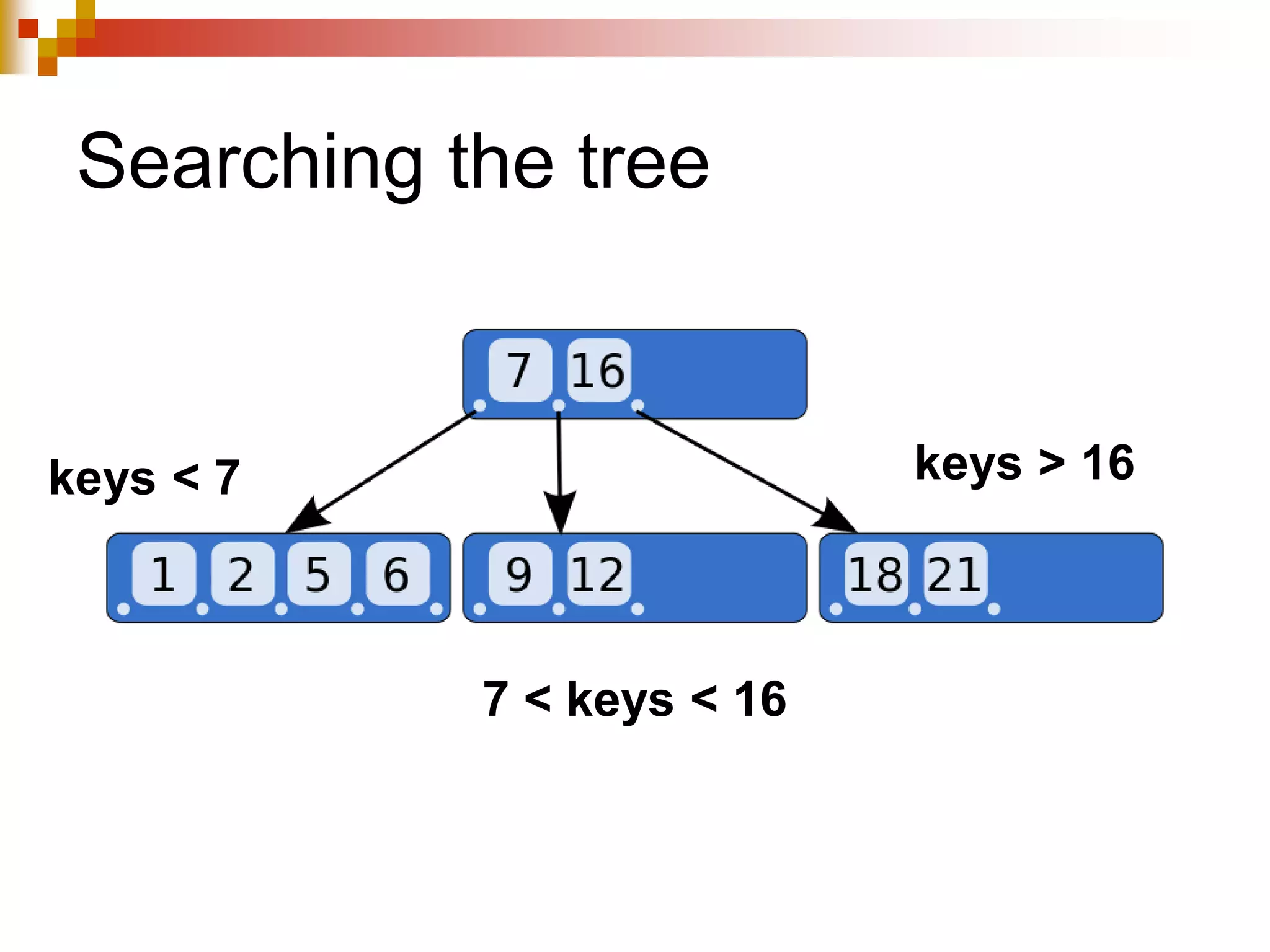
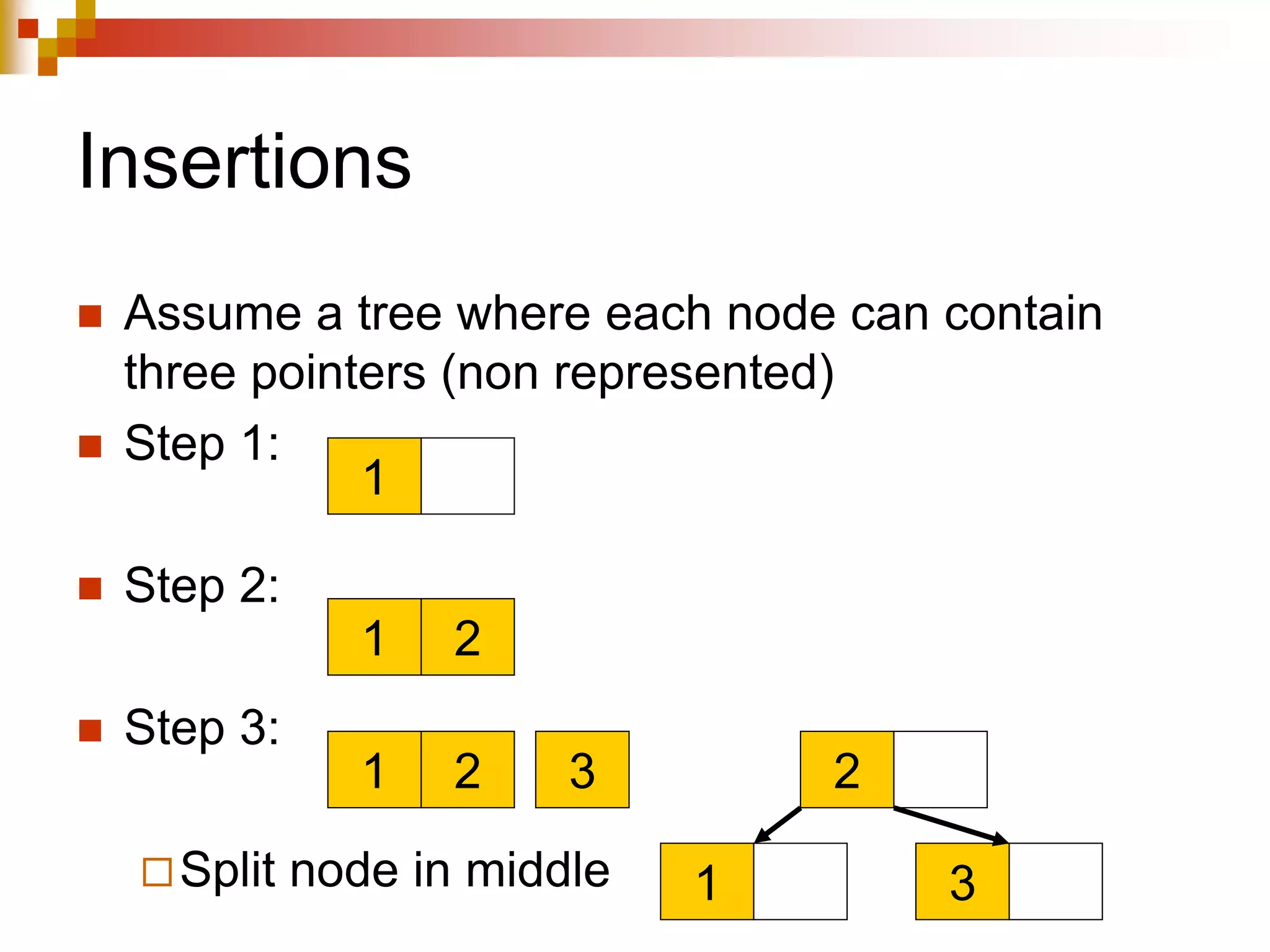
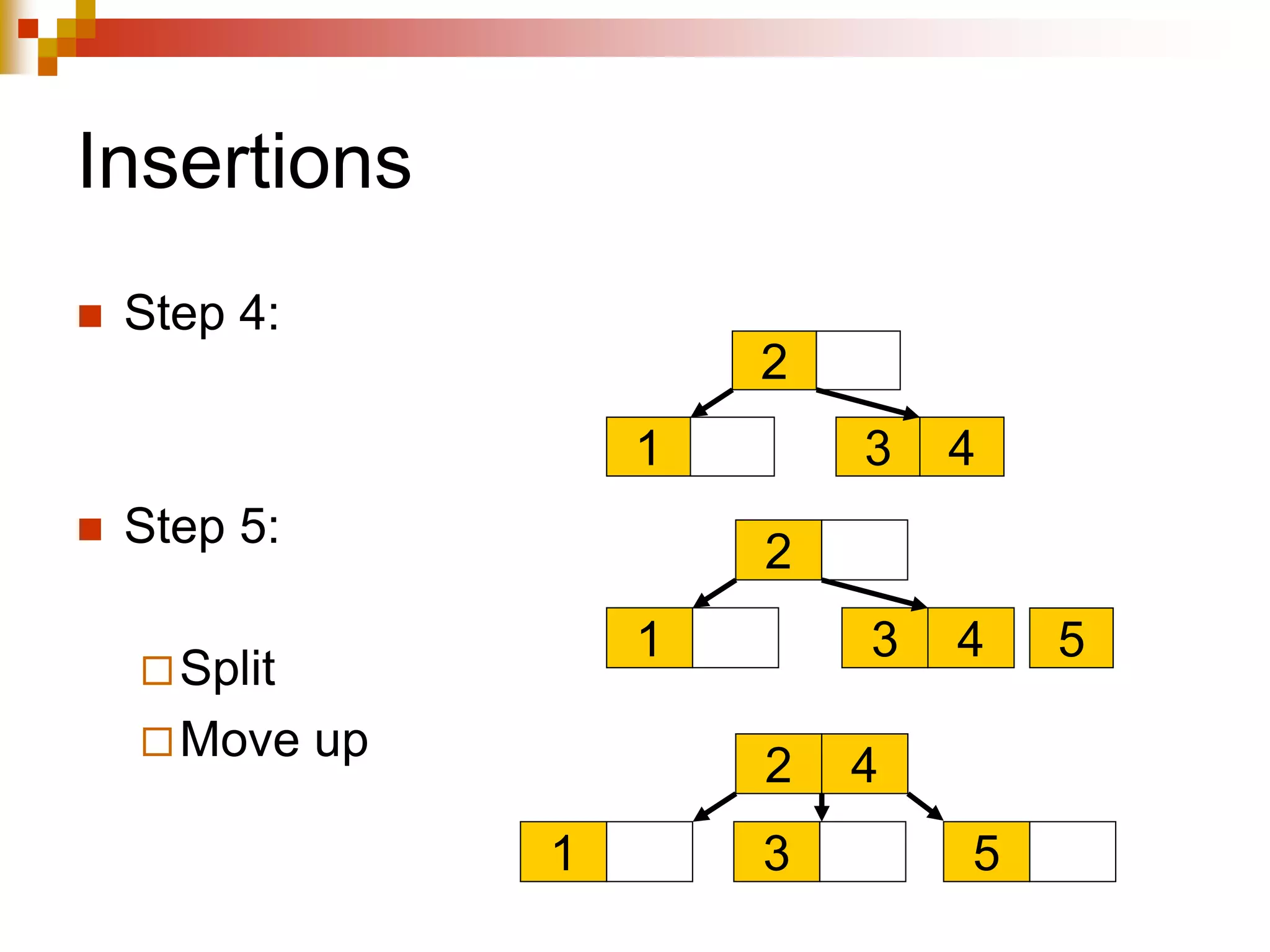
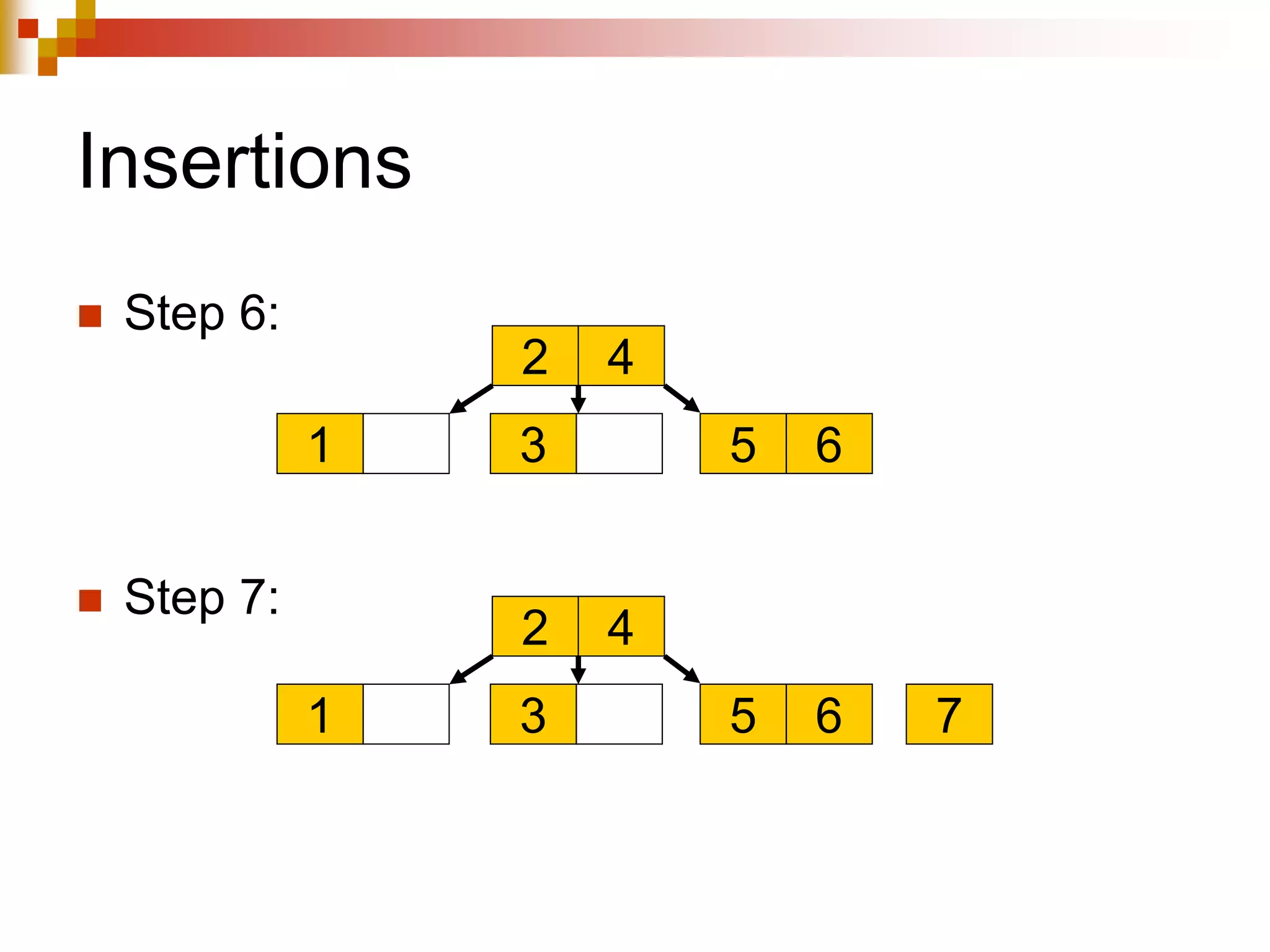
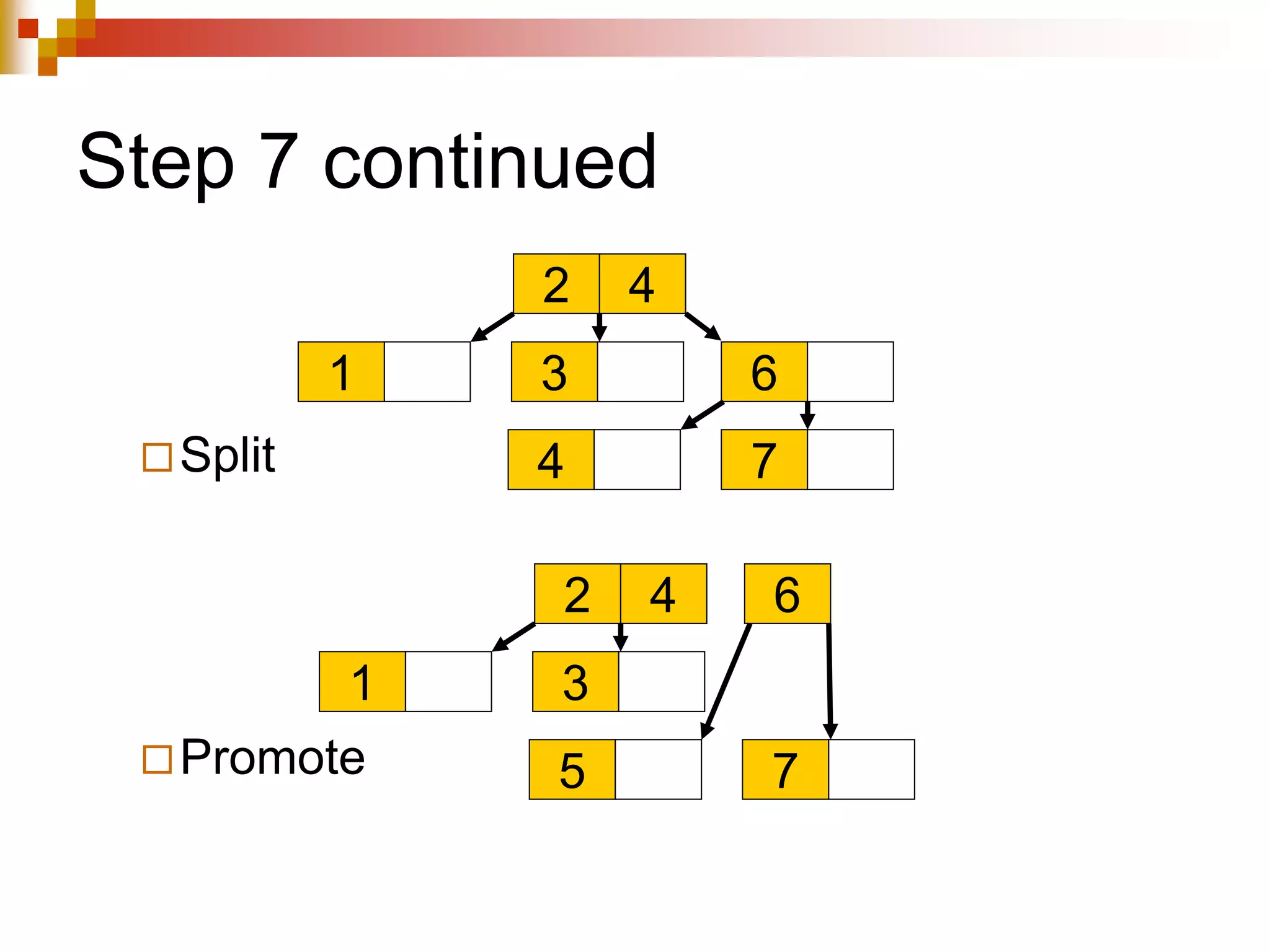
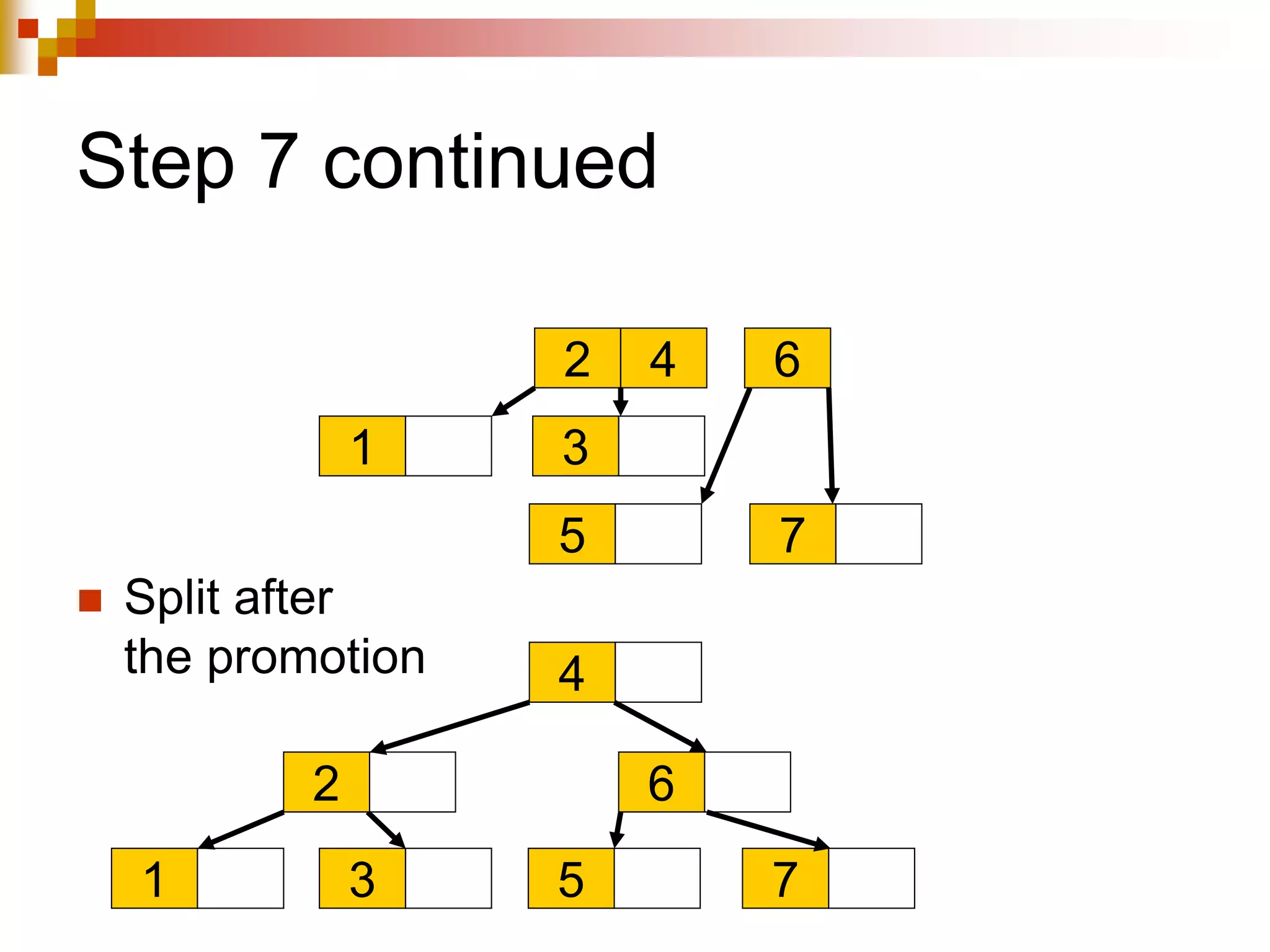
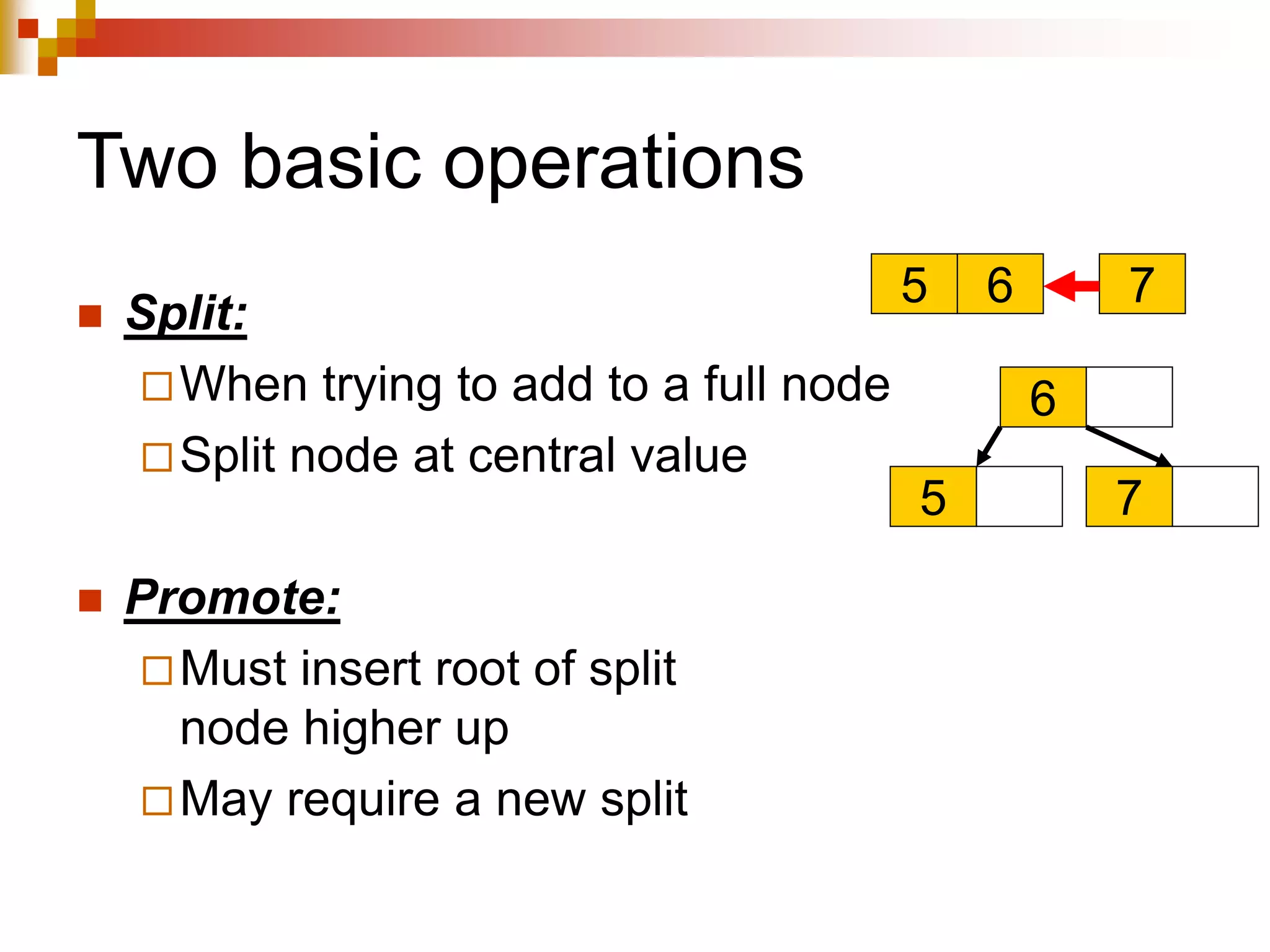
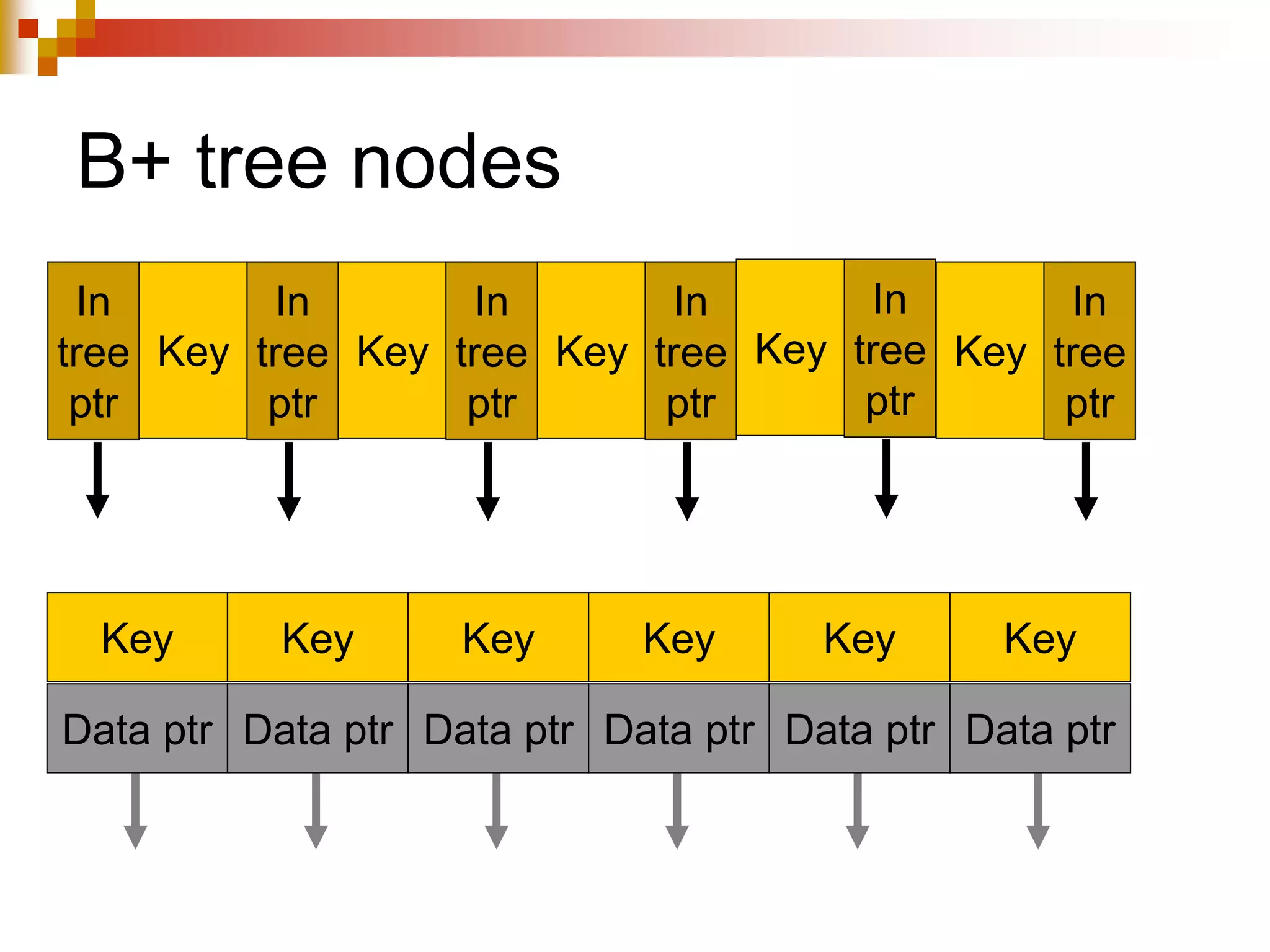
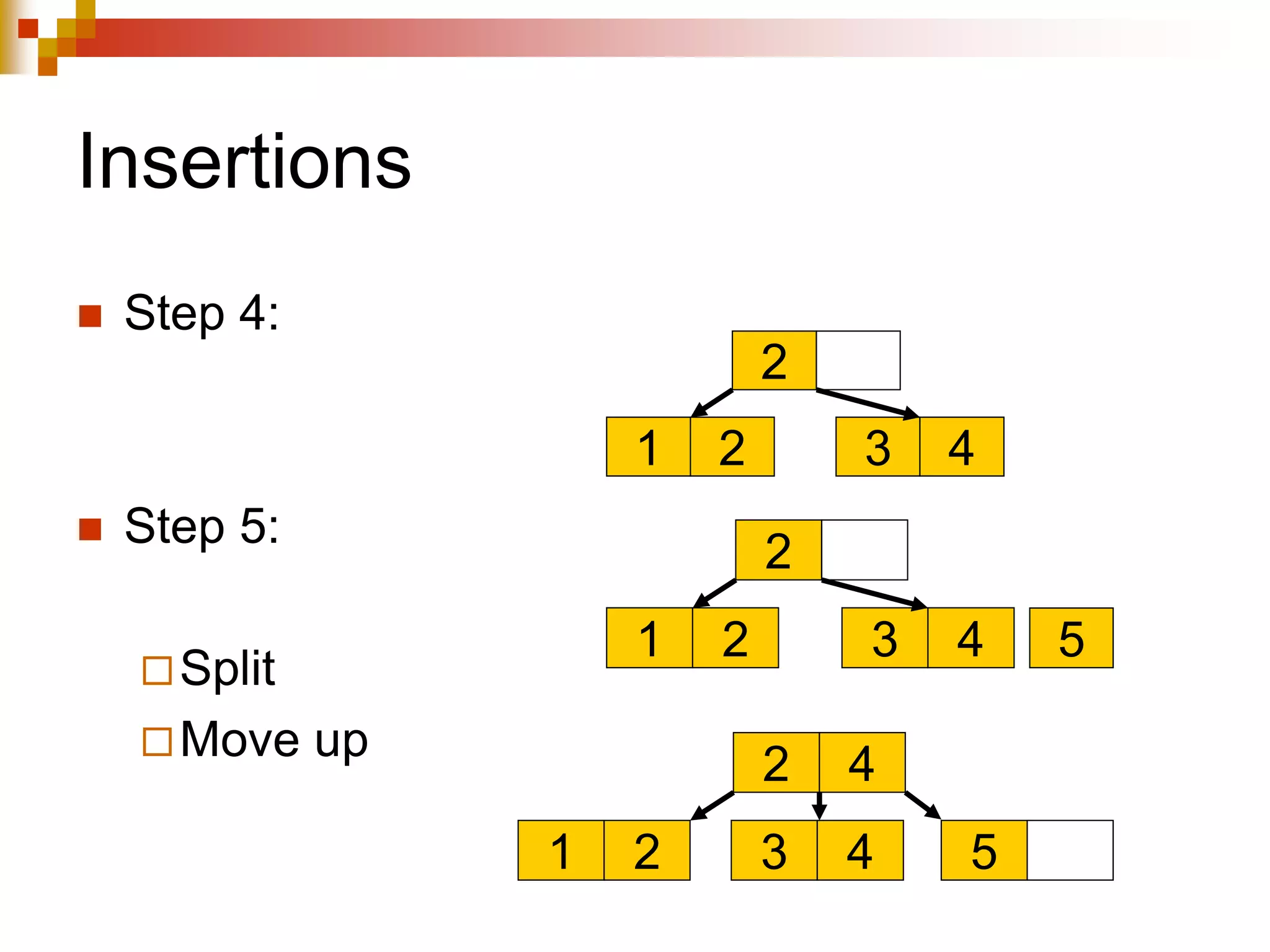
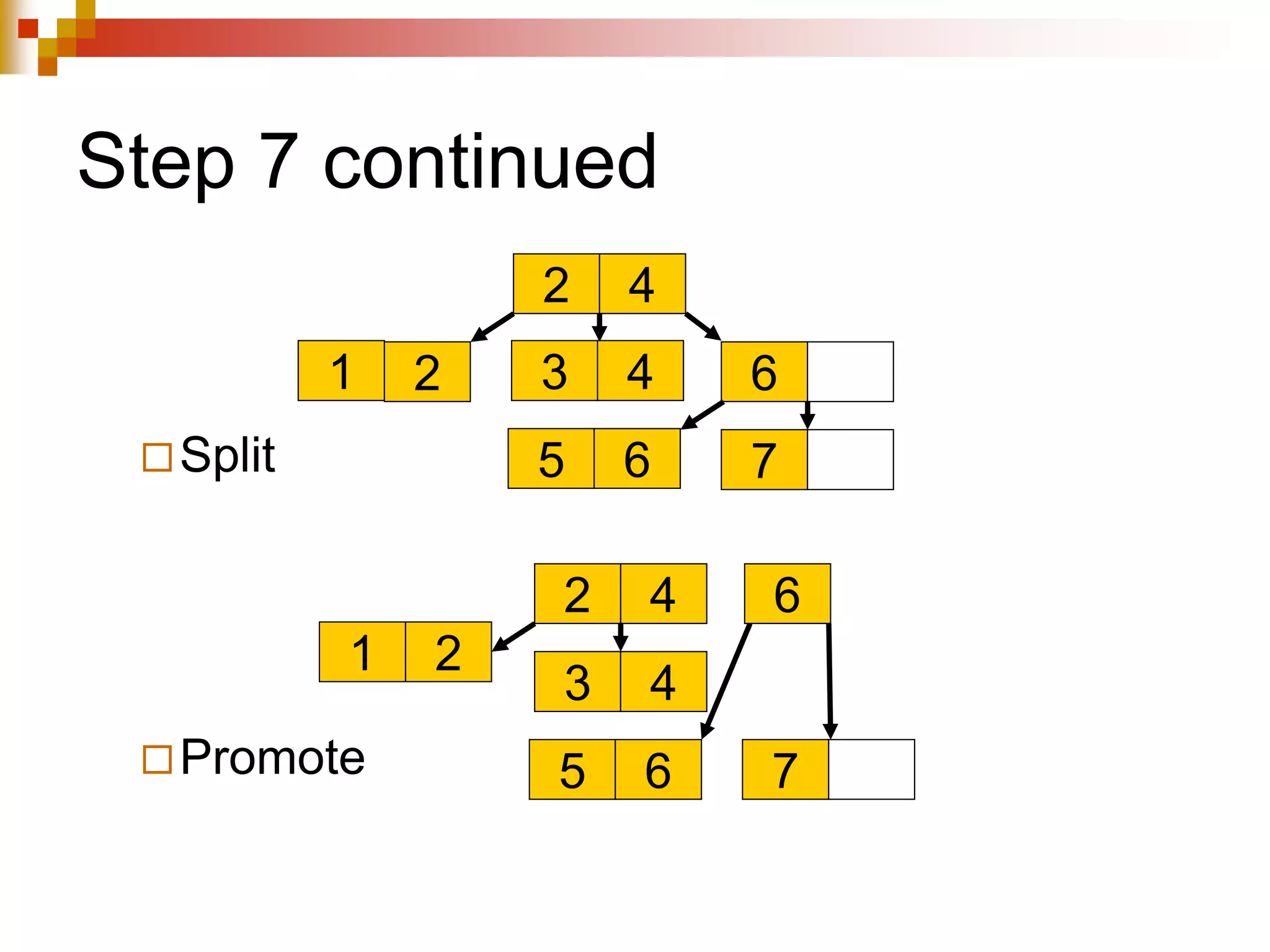
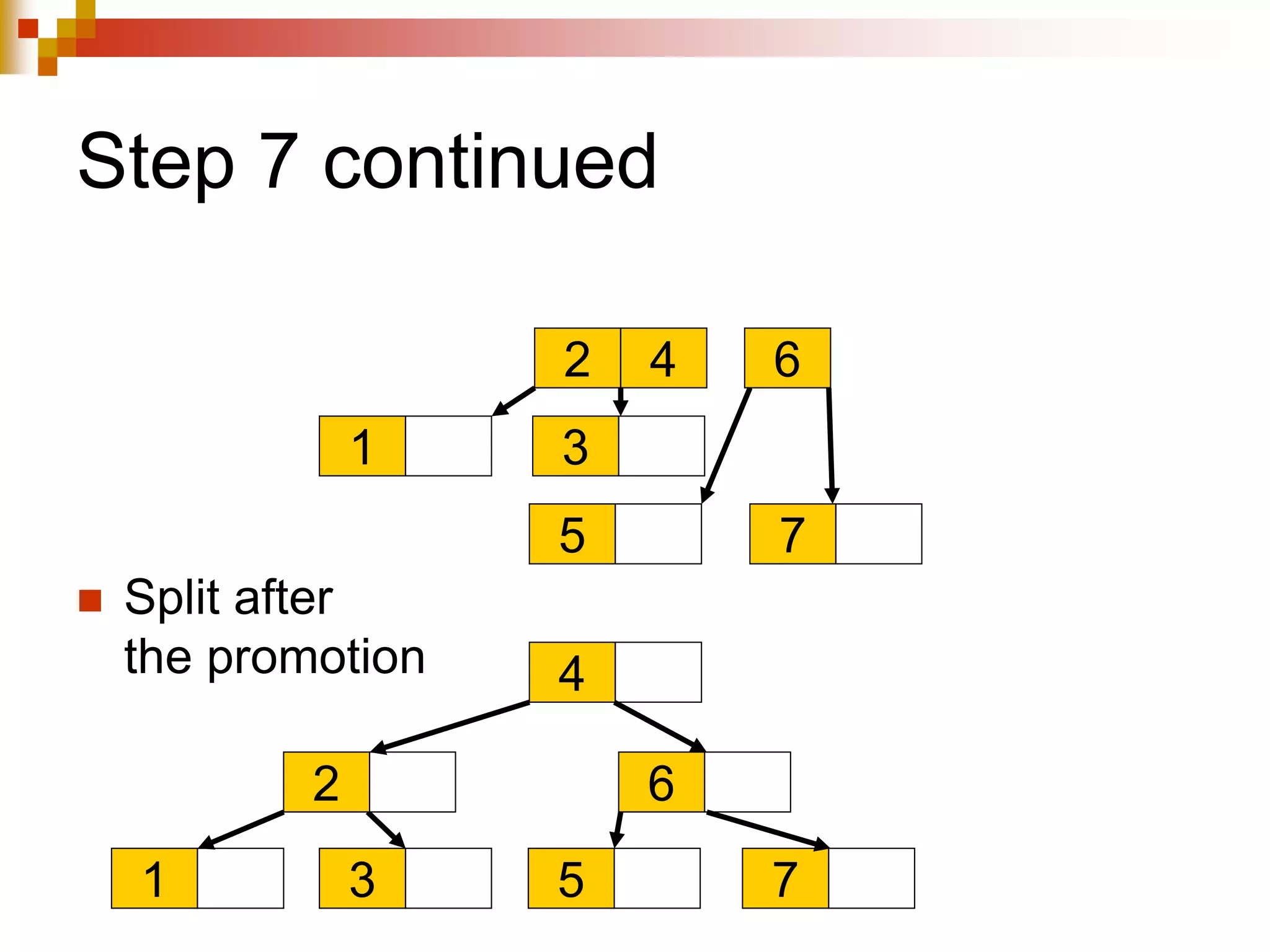
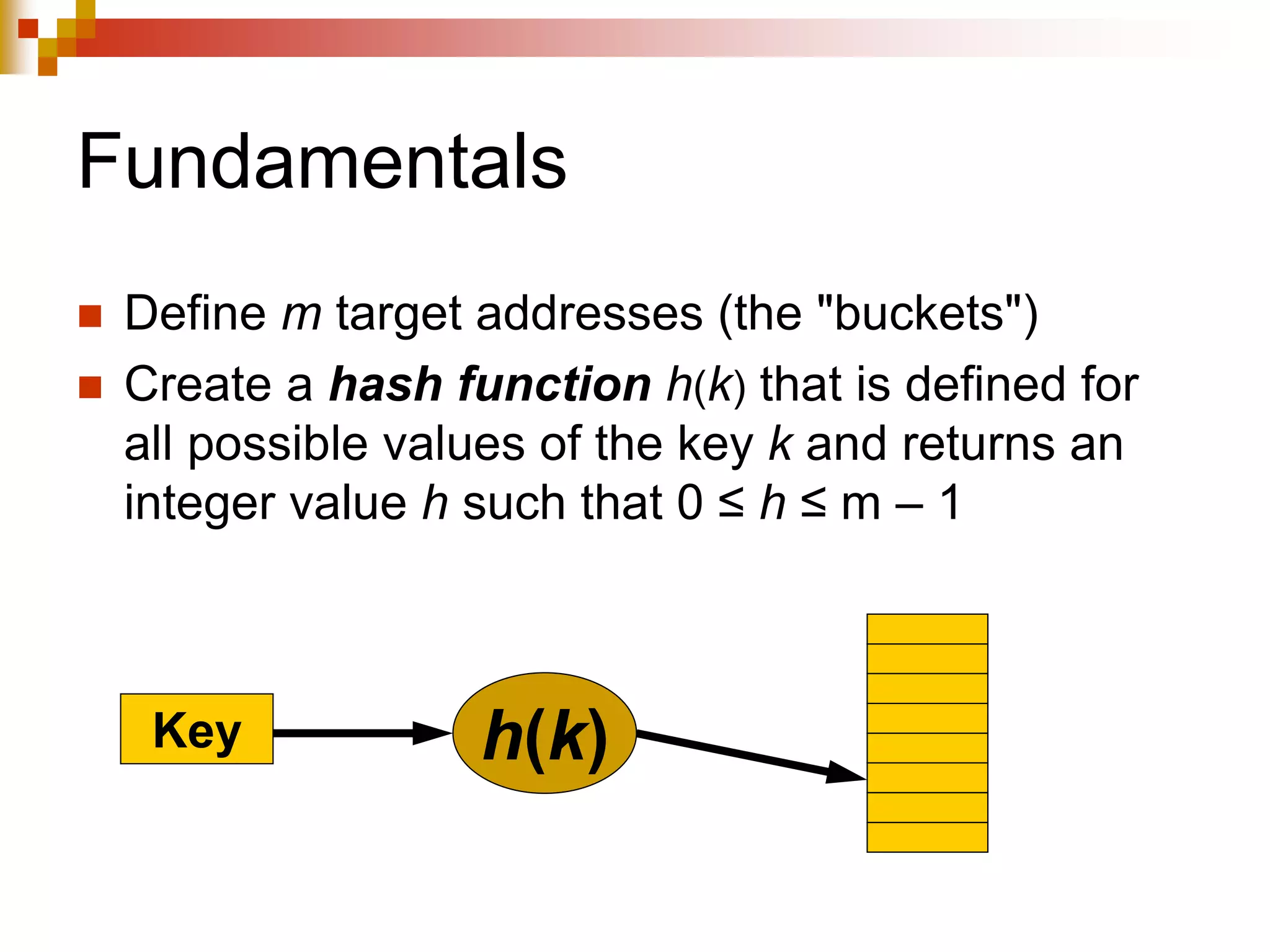
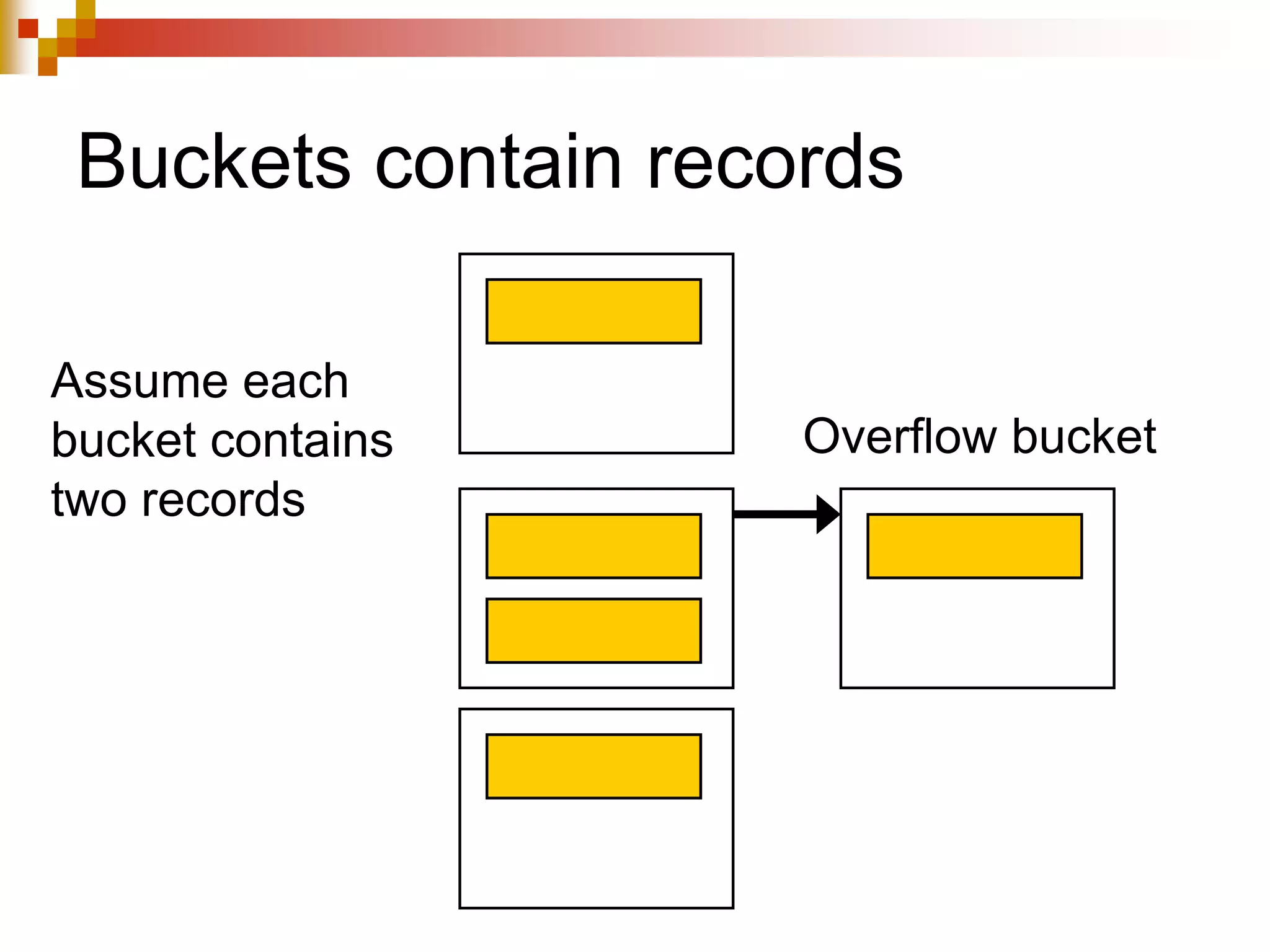
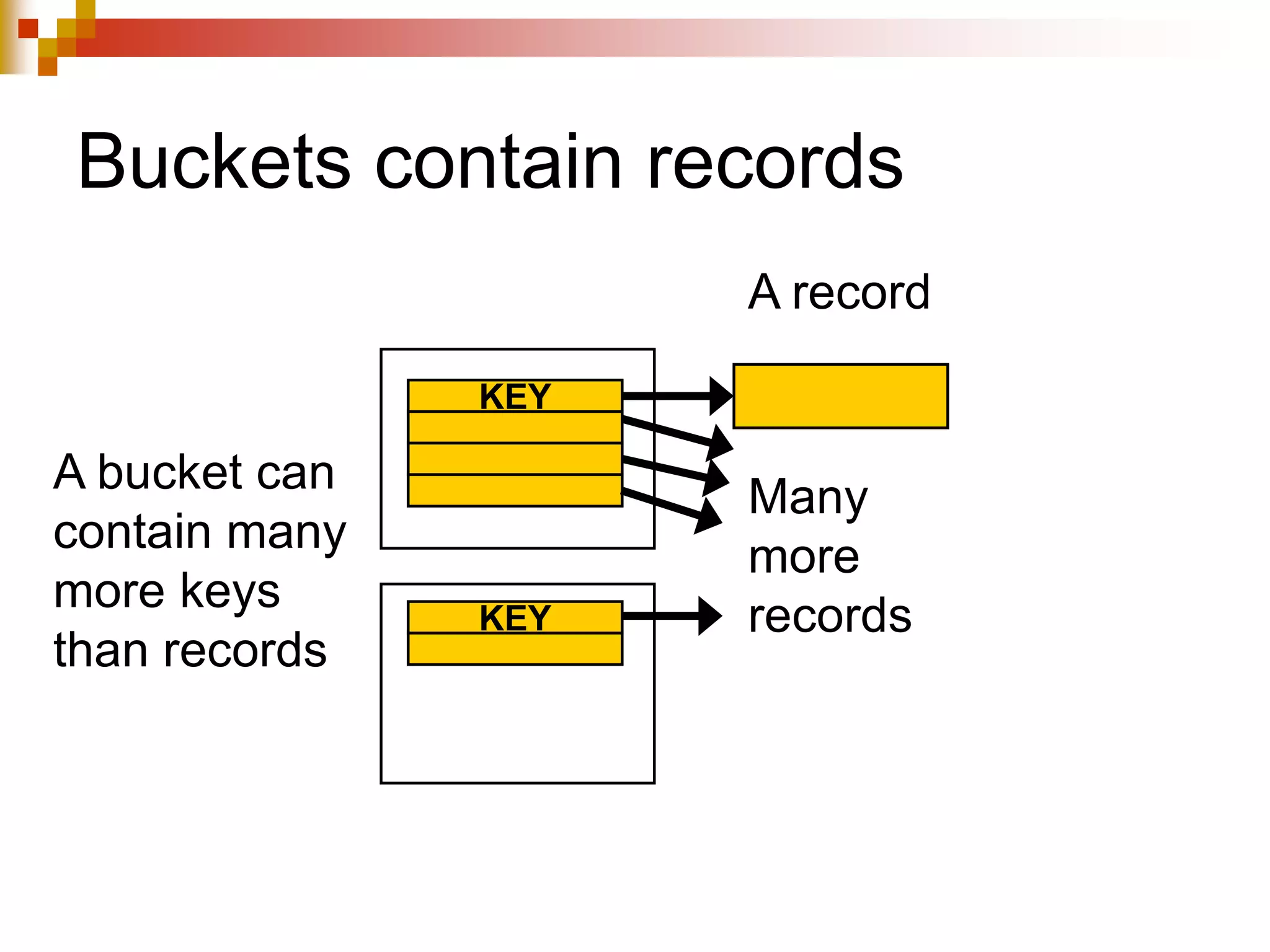
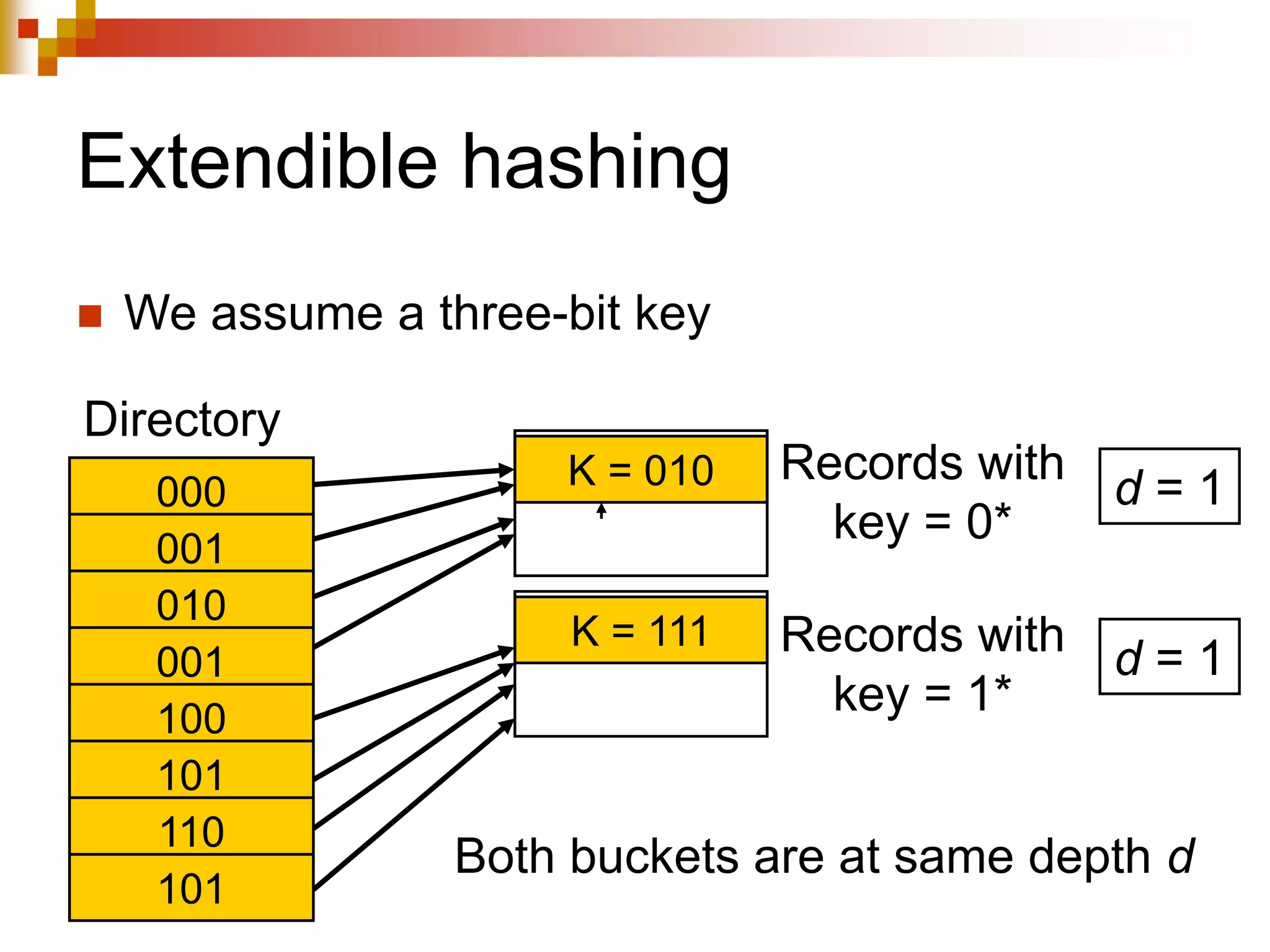
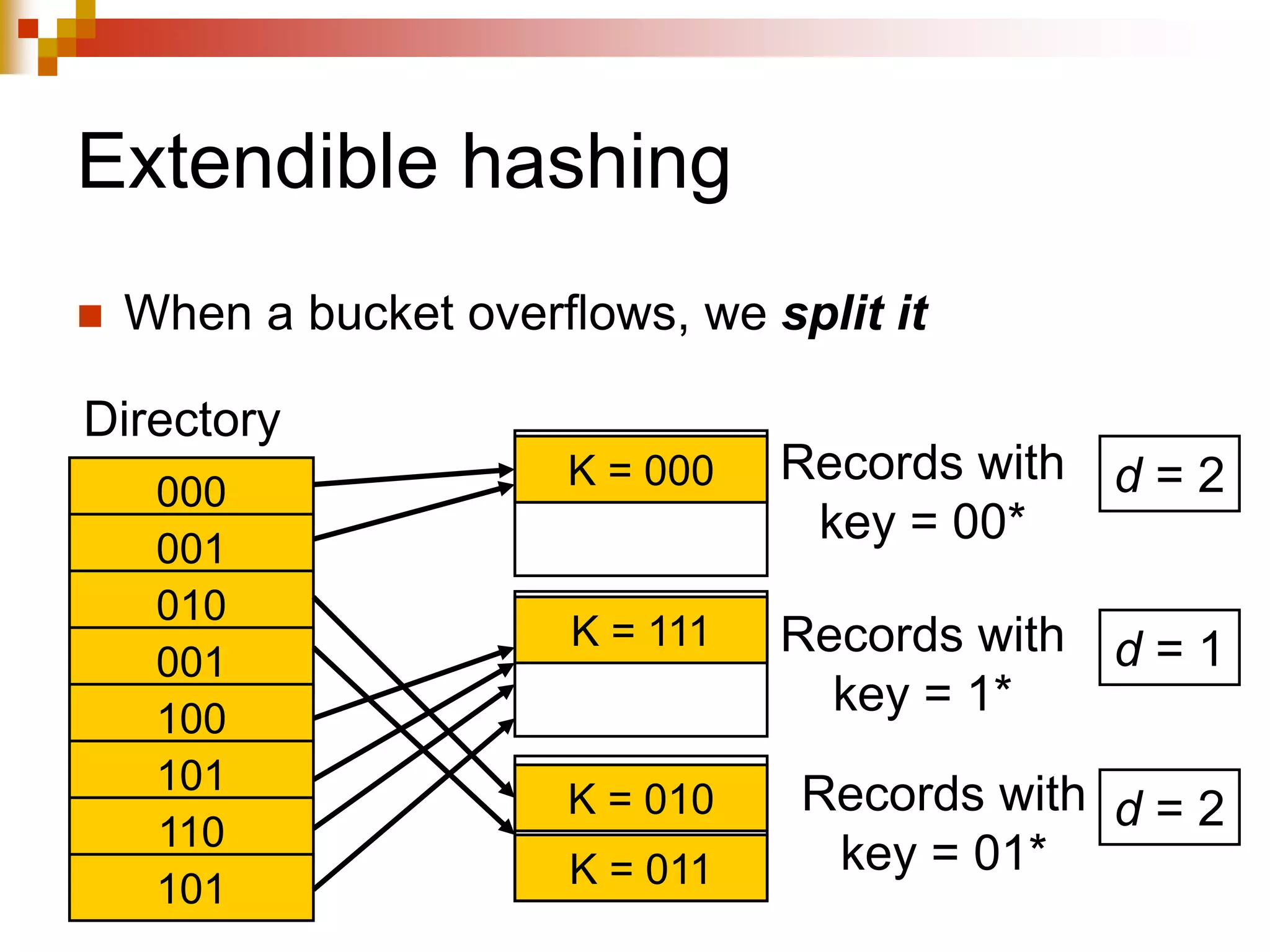
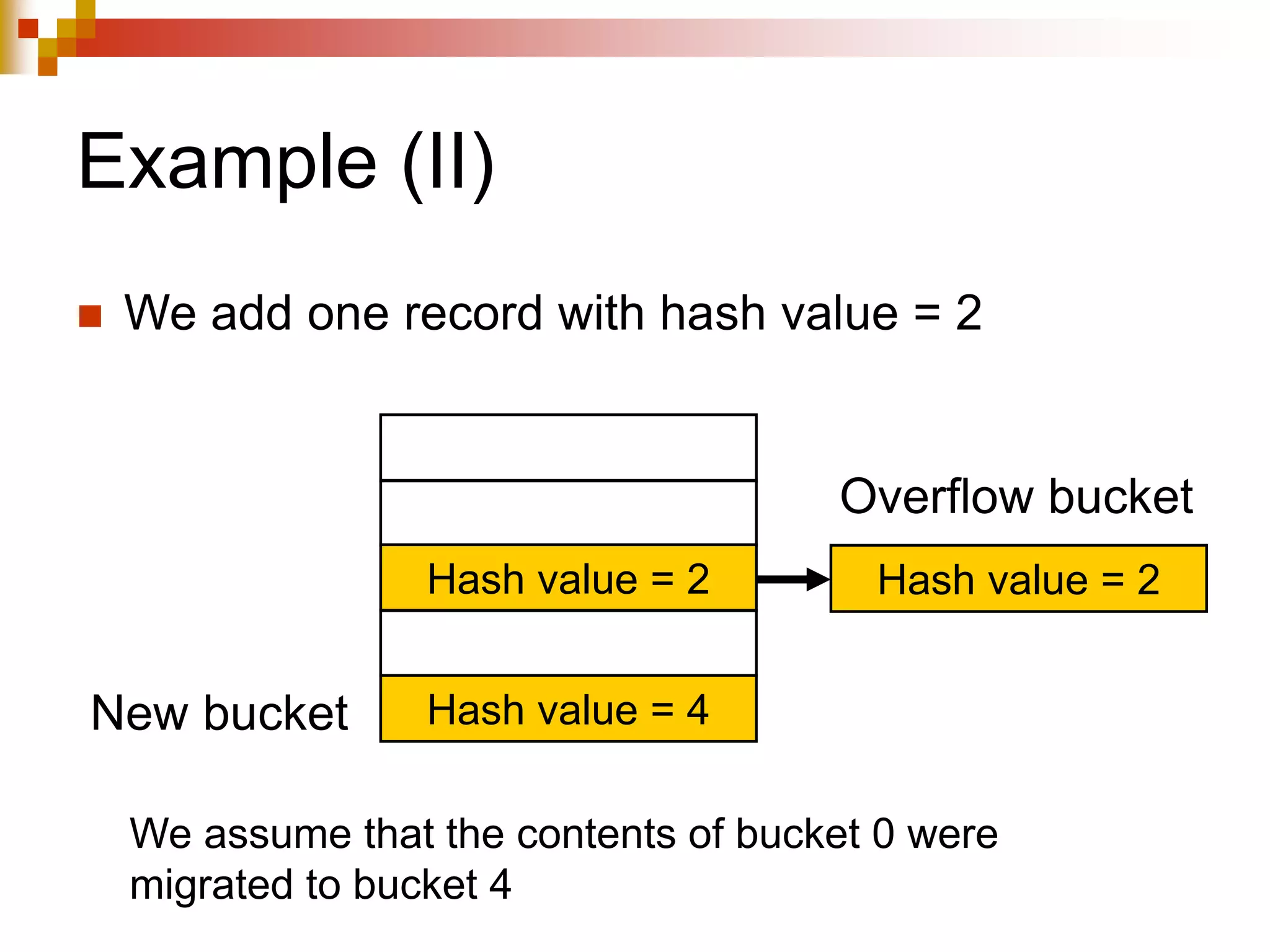
The document discusses different techniques for indexing databases, including conventional indexes, B-trees, and hashing. Conventional indexes can be sparse or dense depending on whether the data is sorted. B-trees and B+-trees allow for dynamic indexing and efficient insertion and deletion of records. B+-trees improve on B-trees by separating internal nodes and leaf nodes. Hashing maps keys to buckets using a hash function, but collisions require overflow buckets. The goal is to distribute records evenly among buckets with a good hash function.





























































![[Www.pkbulk.blogspot.com]file and indexing](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comfileandindexing-130615034648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![Presentation on b trees [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/presentationonbtreesautosaved-210209155822-thumbnail.jpg?width=640&height=640&fit=bounds)






















































