Recommended
PDF
지적 대화를 위한 깊고 넓은 딥러닝 PyCon APAC 2016
PDF
Deep Learning In Agriculture
PPTX
PDF
[패스트캠퍼스] Outbrain Click Prediction
PDF
[데이터를 부탁해] 비전공자가 데이터 분석가로 거듭나기 by 황준식
PDF
PPTX
PPTX
머신러닝 시그 세미나_(deep learning for visual recognition)
PPTX
★강의교재_데이터 분석을 위한 통계와 확률_v2.pptx
PPTX
PDF
소재데이터 AI 실습 최종보고서_ks0014_김영기.pdf
PPTX
파이썬 활용을 위한 데이터 정리 Chapter 02. 1차원 데이터 정리.pptx
PDF
22 r data manipulation 2 pt 20140404
PPTX
PDF
PDF
Algorithm for Analyzing Parameter Similarity of Semiconductor Facilities
PDF
밑바닥부터 시작하는 딥러닝 - 학습관련기술들 스크립트
More Related Content
PDF
지적 대화를 위한 깊고 넓은 딥러닝 PyCon APAC 2016
PDF
Deep Learning In Agriculture
PPTX
PDF
[패스트캠퍼스] Outbrain Click Prediction
PDF
[데이터를 부탁해] 비전공자가 데이터 분석가로 거듭나기 by 황준식
PDF
PPTX
PPTX
머신러닝 시그 세미나_(deep learning for visual recognition)
Similar to 머신러닝 In 충치 진단
PPTX
★강의교재_데이터 분석을 위한 통계와 확률_v2.pptx
PPTX
PDF
소재데이터 AI 실습 최종보고서_ks0014_김영기.pdf
PPTX
파이썬 활용을 위한 데이터 정리 Chapter 02. 1차원 데이터 정리.pptx
PDF
22 r data manipulation 2 pt 20140404
PPTX
PDF
PDF
Algorithm for Analyzing Parameter Similarity of Semiconductor Facilities
PDF
밑바닥부터 시작하는 딥러닝 - 학습관련기술들 스크립트
머신러닝 In 충치 진단 1. 머신러닝 in 충치 진단
목차
1. 기계 학습(machine learning)
1) 지도 학습(supervised learning)
(0) 평가 방법
(1) 서포트 벡터 머신(support vector machine)
(2) k-NN(k-nearest neighbors algorithm)
(3) 의사결정나무(classification tree)
(4) 선형판별분석(linear discriminant analysis)
(5) 지도 학습 데이터 일람
2) 자율 학습(unsupervised learning)
2. 500 nm, 650 nm 부근 피크 강도비
1) 평가 방법
2. 1. 기계 학습(machine learning)
1) 지도 학습(supervised learning)
(0) 평가 방법
a. 진단할 치아 부위에 405 nm 레이저를 조사.
b. 레이저가 조사된 치아 부위에서 반사된 빛을 분광기(spectrometer)로 읽음.
c. 분광기로 읽은 치아 스펙트럼 데이터를 컴퓨터로 전송하여 저장.
d. 임의로 선택한 치아의 스펙트럼 데이터와 해당 치아를 사람의 눈으로 진단한 값(건전한 치
아=1, 우식 치아=2)을 통해 지도학습(supervised learning) 모델 생성.
e. 학습에 사용하지 않은 치아 중 임의선택하여 위의 과정에서 학습한 모델을 통해 우식 여부
를 예측한 후 사람의 눈으로 분류해 놓은 값(건전한 치아=1, 우식 치아=2)과 비교.
f. 임의의 치아를 선택하고 예측하는 것을 100번 반복하여 적중률 계산.
g. 적중률 계산을 100회 반복. 총 10,000개의 치아를 예측하는 동안 수행시간(cputime) 측정.
계산된 적중률 100회의 평균, 표준편차 계산.
h. 지도학습 모델 생성에 사용하는 치아 데이터의 수를 2개에서 100개까지 증가시키면서 위의
과정을 반복한다.
(1) 서포트 벡터 머신(support vector machine)
주어진 자료에 대해서 그 자료들을 분리하는 초평면 중에서, 자료들과 가장 거리가 먼 초평면을
찾는 방법을 사용.
Vladimir Vapnik이 제안한 알고리즘. 90년대 필기인식 분야에서 우수한 성능으로 알려짐. 특히
두 그룹으로 분류하는 성능이 우수. 건전한 치아와 우식 치아 두 그룹으로 나누기에 적합할 것으
로 판단.
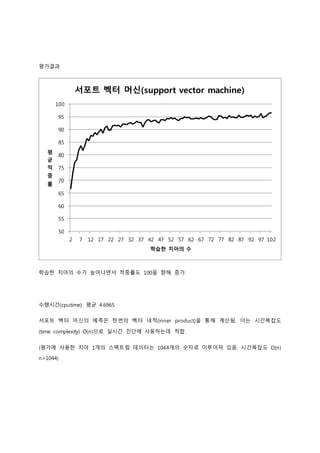
3. 평가결과
100
95
90
85
80
75
70
65
60
55
50
서포트 벡터 머신(support vector machine)
학습한 치아의 수가 늘어나면서 적중률도 100을 향해 증가.
수행시간(cputime) 평균 4.6965
서포트 벡터 머신의 예측은 한번의 벡터 내적(inner product)을 통해 계산됨. 이는 시간복잡도
(time complexity) O(n)으로 실시간 진단에 사용하는데 적합.
(평가에 사용한 치아 1개의 스펙트럼 데이터는 1044개의 숫자로 이루어져 있음. 시간복잡도 O(n)
n=1044)
2 7 12 17 22 27 32 37 42 47 52 57 62 67 72 77 82 87 92 97 102
평
균
적
중
률
학습한 치아의 수
5. (2) k-NN(k-nearest neighbors algorithm)
관찰치 특성을 기준으로 훈련 샘플 중에서 가장 가까운 관찰치들을 분류하는 방법. 기계 학습의
방법 중에 가장 간단한 방법 중 하나. 서포트 벡터 머신(support vector machine)의 대조군으로
설정.
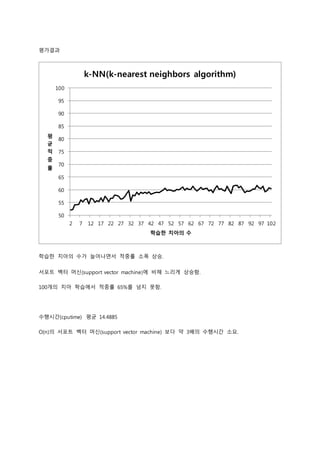
6. 평가결과
100
95
90
85
80
75
70
65
60
55
50
k-NN(k-nearest neighbors algorithm)
2 7 12 17 22 27 32 37 42 47 52 57 62 67 72 77 82 87 92 97 102
평
균
적
중
률
학습한 치아의 수
학습한 치아의 수가 늘어나면서 적중률 소폭 상승.
서포트 벡터 머신(support vector machine)에 비해 느리게 상승함.
100개의 치아 학습에서 적중률 65%를 넘지 못함.
수행시간(cputime) 평균 14.4885
O(n)의 서포트 벡터 머신(support vector machine) 보다 약 3배의 수행시간 소요.
7. (3) 의사결정나무(classification tree)
의사결정규칙을 도표화하여 관심대상이 되는 집단을 몇 개의 소집단으로 분류하거나 예측을 수
행하는 분석방법.
데이터를 구성하는 속성의 수가 불필요하게 많을 경우에도 모형 구축시 분류에 영향을 미치지
않는 속성을 자동으로 제외시키기 때문에 데이터 선정이 용이.
데이터에 다수의 연속형 변수(속성)가 포함되어 있을 경우 값들을 그룹화하여 이산형(discrete)이
나 범주형 값으로 변환시킬 필요가 있는데, 그룹화하는 과정에서 발생하는 치우침을 배제할 수
없음.
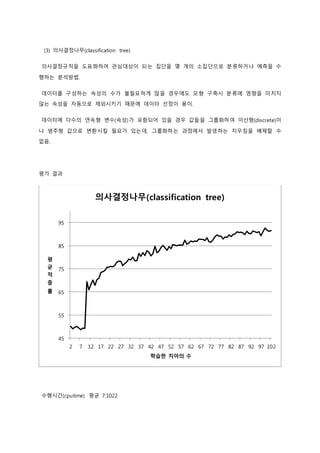
평가 결과
95
85
75
65
55
45
의사결정나무(classification tree)
2 7 12 17 22 27 32 37 42 47 52 57 62 67 72 77 82 87 92 97 102
평
균
적
중
률
수행시간(cputime) 평균 7.1022
학습한 치아의 수
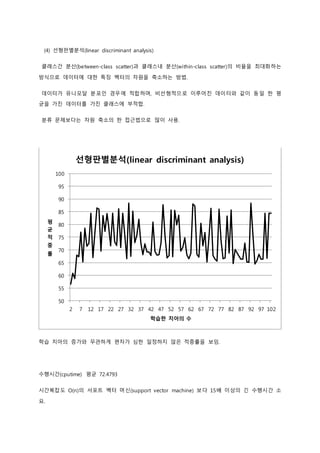
8. (4) 선형판별분석(linear discriminant analysis)
클래스간 분산(between-class scatter)과 클래스내 분산(within-class scatter)의 비율을 최대화하는
방식으로 데이터에 대한 특징 벡터의 차원을 축소하는 방법.
데이터가 유니모달 분포인 경우에 적합하며, 비선형적으로 이루어진 데이터와 같이 동일 한 평
균을 가진 데이터를 가진 클래스에 부적합.
분류 문제보다는 차원 축소의 한 접근법으로 많이 사용.
100
95
90
85
80
75
70
65
60
55
선형판별분석(linear discriminant analysis)
학습 치아의 증가와 무관하게 편차가 심한 일정하지 않은 적중률을 보임.
수행시간(cputime) 평균 72.4793
시간복잡도 O(n)의 서포트 벡터 머신(support vector machine) 보다 15배 이상의 긴 수행시간 소
요.
50
2 7 12 17 22 27 32 37 42 47 52 57 62 67 72 77 82 87 92 97 102
평
균
적
중
률
학습한 치아의 수
9. (5) 지도 학습 데이터 일람
(1) 서포트 벡터 머신(support vector machine) (2) 의사결정나무(decision tree) (3) k-NN(k-nearest neighbors algorithm) (4) LDA(linear discriminant analysis)
학습수 평균 표준편차 수행시간 학습수 평균 표준편차 수행시간 학습수 평균 표준편차 수행시간 학습수 평균 표준편차 수행시간
2 66.71 19.9009 4.524 2 50.16 4.8236 6.8484 2 52.08 9.9032 12.3085 2 56.54 12.595 70.3097
3 72.77 16.0125 4.6176 3 49.01 5.5985 6.942 3 52.16 9.9318 13.3381 3 60.81 13.2426 70.3409
4 77.01 12.509 4.7112 4 49.81 5.1241 6.8952 4 54.08 8.9066 14.2117 4 58.81 12.5406 70.4969
5 78.14 11.9325 4.5708 5 50.07 4.6845 6.7704 5 54.15 9.9599 13.9465 5 68.01 13.5598 70.4969
6 81.91 10.7065 4.68 6 49.36 5.5277 6.8796 6 54.23 7.9517 14.1025 6 67.26 15.8571 70.4657
7 83.57 10.1894 4.4616 7 48.67 5.3467 6.864 7 55.94 8.6408 14.8045 7 76.98 12.8165 70.6841
8 81.72 11.1628 4.3836 8 49.41 4.7484 6.8328 8 55.14 8.8922 14.1805 8 65.21 15.498 70.2629
9 83.64 8.4561 4.524 9 49.17 5.3183 6.942 9 56.23 6.7298 12.9013 9 78.52 13.6245 70.6061
10 86.36 8.2993 4.524 10 69.46 11.1078 6.9888 10 56.52 7.7765 13.1197 10 71.45 15.8658 70.7777
11 85.6 9.2594 4.4928 11 66.01 11.8104 7.0824 11 54.49 8.5676 13.4005 11 72.54 15.3797 74.5841
12 87.7 7.5338 4.4304 12 68.17 10.563 6.8328 12 56.57 8.7355 13.2601 12 84.35 10.4537 72.4469
13 87.27 8.656 4.4148 13 70.18 10.7029 6.8172 13 56.3 6.9435 13.1977 13 67.03 17.2776 74.0381
14 88.79 6.0257 4.5084 14 67.92 12.1636 6.8484 14 55.04 7.49 13.3225 14 76.76 15.8504 74.6933
15 88.02 7.5972 4.6956 15 70.27 10.5523 6.8796 15 55.67 8.3146 13.2601 15 86.52 7.6969 75.9101
16 89.12 6.4952 4.8204 16 70.93 11.1873 6.8484 16 55.44 7.9599 13.2913 16 85.96 8.4721 75.8477
17 90.02 5.7013 4.8672 17 73.35 10.2281 6.8796 17 56.79 7.5348 13.1665 17 69.58 12.338 77.9849
18 88.56 7.0558 4.9764 18 73.73 9.1617 6.864 18 55.29 8.5662 13.1353 18 83.52 9.6132 86.175
19 90.66 5.7493 5.148 19 74.26 9.0717 6.8172 19 57.37 7.8479 13.2133 19 77.37 14.2437 79.5137
20 91.35 5.4223 4.836 20 75.68 8.7385 6.864 20 56.4 8.3931 13.4005 20 84.27 11.241 85.3169
21 89.63 6.6129 5.0388 21 75.76 9.7671 6.8328 21 55.19 8.1584 13.3537 21 79.28 13.5327 77.6573
22 89.71 6.2898 5.0544 22 76.09 8.3727 6.8328 22 56.58 8.2709 13.3849 22 71.65 13.0704 74.7401
23 91.44 4.9915 4.7424 23 75.85 7.8552 6.7704 23 56.71 7.3571 13.4317 23 84.41 11.5942 71.1833
24 91.54 5.5731 4.6176 24 76.45 8.839 7.2852 24 57.87 7.3864 13.4785 24 73.17 10.9702 73.6793
25 91.42 5.0296 4.6644 25 77.8 8.0966 7.0824 25 57.67 8.44 13.3225 25 71.75 13.7315 76.0349
26 91.56 5.7565 5.0544 26 78.32 8.1065 7.41 26 57.48 7.7218 13.5097 26 86.09 9.0007 74.8961
27 91.05 4.6218 5.1012 27 78.24 8.38 7.4568 27 56.37 7.8992 13.4473 27 71.03 12.2857 75.2081
28 92.07 4.3537 4.914 28 76.39 8.2766 7.722 28 56.45 7.3063 13.5409 28 84.46 10.5183 73.4297
29 92.07 4.8373 4.7892 29 77.2 7.8251 7.3632 29 57.28 7.2754 13.4941 29 76.06 12.4355 70.7309
30 91.99 4.5383 4.8828 30 78.04 7.9492 7.2852 30 58.56 7.5134 13.5253 30 66.6 11.3991 73.8821
31 92.42 4.2288 4.8516 31 79.1 8.2309 7.1916 31 59.72 5.8294 13.4785 31 88.3 6.4063 74.7401
32 92.72 4.7844 4.836 32 78.82 8.1033 7.3008 32 55.52 7.2898 13.5409 32 67.46 9.2828 73.5545
33 92.1 4.9879 5.07 33 80.02 6.9165 7.3008 33 57.92 7.6418 13.5409 33 85.23 10.3161 77.0489
34 92.63 4.5719 5.1168 34 78.46 7.9333 7.41 34 57.55 7.0114 13.6657 34 72.78 13.5524 76.9085
35 93.24 4.0255 4.68 35 78.47 7.7791 7.3164 35 58.99 6.6492 13.4941 35 75.66 12.2088 77.2673
36 92.79 4.5289 4.8204 36 81.65 7.0673 7.2852 36 58.06 7.565 13.6189 36 81.98 13.39 77.6885
37 92.74 4.9393 4.7112 37 80.38 7.7261 7.41 37 58.94 8.187 13.5097 37 72.75 12.5669 76.7369
10. 38 91.01 4.5693 4.7268 38 82.03 6.7904 7.1916 38 58.48 6.7352 13.6969 38 68.12 7.0658 77.1113
39 92.51 4.1863 4.524 39 80.69 7.0176 7.3788 39 59.06 7.717 13.6501 39 72.39 10.1274 77.0645
40 93.74 3.7541 4.6644 40 82.81 6.8027 7.2072 40 58.49 6.7007 13.6501 40 69.17 8.0316 72.5093
41 93.9 3.7966 4.5864 41 82.09 6.9298 7.1292 41 59.12 7.9128 13.6345 41 69.15 7.9014 71.4173
42 93.07 4.3047 4.8984 42 80.54 7.2229 7.332 42 58.28 7.2448 13.7125 42 67.85 9.6236 71.5265
43 93.29 4.5467 4.7892 43 81.65 7.9078 7.1604 43 58.5 6.9246 13.6657 43 80.9 12.979 71.5733
44 93.72 3.9545 4.7892 44 84.73 6.6906 7.176 44 58.87 6.897 13.7281 44 69.39 10.1771 71.4953
45 92.96 4.8261 4.7112 45 81.98 7.5156 7.3008 45 59.08 7.3604 13.7593 45 67.99 8.4918 71.8229
46 92.58 3.6658 4.5864 46 82.68 7.6222 7.2696 46 58.81 7.4396 13.8841 46 68.1 8.5191 71.7761
47 93.87 3.8393 4.5708 47 84.25 7.0544 7.1604 47 59.3 7.2286 13.8529 47 72.74 12.5647 71.9165
48 93.79 4.1275 4.6488 48 85.03 6.8023 7.2696 48 59.84 7.2456 13.9153 48 87.79 5.2229 71.0429
49 93.56 4.5756 4.524 49 84 7.1732 7.3008 49 60.66 8.5932 13.8997 49 75.33 12.4309 71.0741
50 94.34 4.5176 4.5708 50 83 8.5788 7.2852 50 59.66 7.4606 13.7749 50 66.9 10.3831 70.8557
51 94.22 3.8339 4.5552 51 84.61 7.3111 7.1916 51 59.93 7.2282 13.7437 51 67.75 8.2528 70.8557
52 94.54 3.9426 4.5552 52 83.7 7.8939 7.0512 52 59.76 8.0618 14.0089 52 85.63 7.8053 70.8557
53 94.11 4.6208 4.5708 53 85.39 8.0853 7.2228 53 59.43 6.9052 14.2741 53 67.29 7.7802 70.9493
54 94.39 3.4696 4.602 54 85.35 7.22 7.1916 54 59.44 8.558 14.9605 54 85.52 7.2606 70.8089
55 93.87 4.3127 4.6176 55 84.97 6.6126 7.41 55 60.17 8.0592 14.5237 55 79.85 11.5026 70.9805
56 93.49 4.6482 4.5552 56 85.36 8.0044 7.3944 56 59.98 7.101 14.1181 56 83.59 10.1326 70.6529
57 94.34 3.7959 4.4928 57 85.35 7.6902 7.2228 57 60.42 7.5293 13.8997 57 69.52 8.4393 70.9649
58 94.25 4.2507 4.5396 58 85.25 6.6597 7.3944 58 60.99 7.0718 14.0557 58 70.97 12.1642 70.9181
59 94.87 4.1357 4.68 59 87.37 7.0677 7.1292 59 59.73 8.0802 15.1477 59 74.79 10.7217 70.7465
60 94.55 4.011 4.6644 60 85.68 7.8559 7.2696 60 60.61 7.4195 14.7421 60 68.14 10.6969 70.8713
61 94.78 4.2701 4.6176 61 86.1 7.1259 7.3476 61 60.12 7.09 14.6485 61 66.48 7.3505 70.8713
62 94.22 4.4143 4.6488 62 86.95 6.8422 7.2384 62 60.14 6.9921 15.4909 62 68.54 7.8334 70.7465
63 94.14 4.4154 4.5864 63 86.66 7.2811 7.3164 63 61.35 8.0118 15.9901 63 88.13 5.4987 71.0117
64 94.26 4.4395 4.6488 64 86.96 6.7103 7.3164 64 60.24 7.9291 15.7873 64 87.29 5.6269 71.0117
65 94.41 3.9774 4.6644 65 86.86 7.1577 7.2696 65 59.45 8.0734 15.5689 65 68.21 7.6874 71.2613
66 94.21 4.2362 4.5864 66 87.93 7.8589 7.3944 66 60.12 8.3633 15.8185 66 67.13 8.5796 70.7777
67 94.62 3.8106 4.602 67 87.78 6.5298 7.6596 67 60.97 7.2717 15.0229 67 80.5 10.2922 70.9493
68 94.16 4.4192 4.5708 68 87.64 7.2718 7.644 68 60.19 8.146 14.8825 68 71.6 10.5361 71.0741
69 94.26 4.1962 4.5396 69 87.25 7.36 7.2696 69 60.44 7.2868 15.7717 69 76.77 14.3646 70.9181
70 94.73 4.2232 4.6488 70 88.48 7.2565 7.3632 70 60.66 7.5655 15.4753 70 65.22 8.2946 71.1833
71 95.33 4.0052 4.524 71 86.76 7.8278 7.2228 71 59.52 7.7856 14.7733 71 75.02 15.1231 70.9337
72 94.86 4.6363 4.68 72 86.52 6.8615 7.2696 72 60.03 8.3066 15.0229 72 86.28 6.5706 70.7933
73 94.18 4.3886 4.5396 73 87.47 7.3022 7.2696 73 58.79 7.7098 15.3193 73 67.72 8.2033 71.5421
74 93.9 4.587 4.5084 74 88.9 7 7.5036 74 60.39 8.0263 15.5689 74 66.34 8.6319 70.7777
75 94.03 5.256 4.5864 75 89.7 6.6142 7.2228 75 61.56 8.4091 16.0213 75 65.52 11.2479 70.9337
76 95.45 3.7561 4.7112 76 89.14 6.7764 6.9576 76 60.06 7.7314 15.3505 76 85.99 9.0971 70.9337
77 95.24 3.83 4.7424 77 89.09 6.3693 6.9576 77 60.38 9.5079 15.4129 77 73.59 13.4803 70.9961
11. 78 94.41 4.9054 4.5552 78 87.87 8.0021 6.8796 78 59.88 9.0367 15.3817 78 66.48 8.7669 70.8869
79 94.77 4.5123 4.6644 79 88.69 7.4301 6.9576 79 59.49 8.9798 15.1633 79 66.84 10.9791 71.6201
80 94.37 4.6071 4.9764 80 88.55 7.0243 6.8796 80 61.4 9.0966 15.7873 80 83.25 11.8282 71.2769
81 95.47 4.2816 4.8204 81 89.57 7.1354 6.8484 81 59.83 8.9545 15.8497 81 68.73 9.5715 70.9337
82 94.7 4.587 4.7268 82 88.95 6.9448 6.8484 82 58.48 9.9499 15.1009 82 85.74 6.8233 71.3549
83 94.92 4.972 4.758 83 89.82 7.0773 6.942 83 61.38 9.1296 15.3505 83 64.57 9.4669 71.0273
84 94.68 4.6273 4.8672 84 90.14 7.6753 7.1136 84 61.69 8.678 15.0541 84 70.16 12.9019 70.9181
85 94.63 4.3244 4.7268 85 91.05 7.5403 6.9732 85 61.72 10.0535 15.4909 85 68.8 13.919 71.0273
86 95.59 4.5596 4.7736 86 90.69 6.6586 6.8484 86 60.78 10.0911 15.3661 86 67.62 8.7083 70.9493
87 94.77 6.3227 4.7112 87 90.79 6.4358 6.7704 87 61.33 8.882 15.5533 87 66.44 10.4072 71.1053
88 94.78 4.2369 4.7112 88 90.45 7.3969 6.8952 88 60.05 10.501 15.3193 88 66.37 9.5681 70.9025
89 95.13 5.0144 4.758 89 89.84 7.1742 6.9108 89 58.89 10.8124 15.6781 89 72.69 13.9535 70.8557
90 95.6 4.9909 4.7424 90 91.22 6.8705 6.8172 90 59.55 10.6841 15.8809 90 65.29 9.9821 71.1989
91 95.2 5.3144 4.8516 91 90.28 7.4129 6.7548 91 59.26 10.353 15.4909 91 65.1 11.8505 71.1053
92 95.63 4.6027 4.7892 92 90.2 7.6343 6.8796 92 59.66 12.2096 15.6781 92 88.36 7.8836 71.1209
93 94.6 5.4551 4.68 93 91.3 7.0216 6.8796 93 60.35 12.0499 15.9589 93 76.15 14.198 71.3081
94 95.23 4.9663 4.758 94 90.97 6.608 6.7548 94 60.2 11.2851 15.9121 94 64.5 12.9821 71.1677
95 94.77 6.4414 4.6956 95 90.69 8.3105 6.9108 95 61.76 11.1628 16.3177 95 65.81 12.9394 71.1209
96 95.1 5.002 4.6176 96 91.09 9.3215 6.8328 96 60.73 12.464 16.3489 96 68.22 11.7117 71.3549
97 96.25 4.4955 4.6488 97 89.2 8.7386 6.8172 97 60.46 13.8253 16.5049 97 66.44 12.049 71.2145
98 94.65 6.0958 4.6956 98 91.1 7.8682 7.02 98 61.34 13.8908 16.0681 98 66.38 13.6876 71.0429
99 95.05 6.0342 4.7268 99 92.59 7.1972 6.708 99 59.22 11.6737 16.4269 99 84.36 13.4506 70.9961
100 95.53 6.3349 4.758 100 91.72 8.4985 7.1916 100 59.61 15.5465 16.6609 100 66.62 16.4444 71.1521
2) 자율 학습(unsupervised learning)
사람의 눈으로 건전한 치아와 우식 치아를 구분하는 것은 주관적이므로 이를 토대로 학습하여
진단하는 지도 학습(supervised learning)은 한계가 있음.
객관적인 진단 장비를 만들기 위해서는 사람의 판단이 들어간 사전 정보 없이 주어진 치아 정보
만을 자율 학습(unsupervised learning)하여 내리는 진단이 필요.
추후 인공신경망(artificial neural network), 딥러닝(deep learning) 모델 등의 자율 학습이 진단모
형을 만드는데 응용될 것으로 기대.
12. 2. 500 nm, 650 nm 부근 피크 강도비
1) 평가 방법
a. 진단할 치아 부위에 405 nm 레이저를 조사함.
b. 레이저가 조사된 치아 부위에서 반사된 빛을 분광기(spectrometer)로 읽음.
c. 분광기로 읽은 스펙트럼 데이터를 실시간으로 컴퓨터로 전송.
d. 500 nm 부근의 가장 높은 피크 값(n1)과 650 nm 부근의 가장 높은 피크 값(n2)을 구함.
e. 강도 보정을 위해 두 피크에서 일정한 값을 뺌.
f. n2/(n1+n2) 값의 크기로 치아 우식 여부를 판단.









![[패스트캠퍼스] Outbrain Click Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/outbrainclickprediction-161213235538-thumbnail.jpg?width=640&height=640&fit=bounds)
![[데이터를 부탁해] 비전공자가 데이터 분석가로 거듭나기 by 황준식](https://cdn.slidesharecdn.com/ss_thumbnails/dabopenlecture151120session4-151124081608-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











