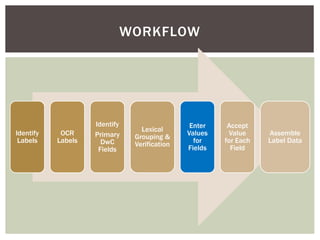
This document describes a method for digitizing specimen label data using crowdsourced labor. Labels are scanned using OCR software to extract text. Volunteers then view the OCR output and images to identify fields like scientific names, dates, and locations. They assign values to these fields which are assembled into structured occurrence records. The records are exported in formats like Darwin Core and made available via web services. Volunteers earn tokens for their work that can be used to support science-related causes through an online store, creating a sustainable model where collections are digitized at low cost while benefiting volunteer contributors.