HBase is an open source, distributed, versioned, non-relational database modeled after Google's BigTable. It is built on top of HDFS for storage, and provides BigTable-like capabilities for Hadoop. HBase provides fast random access and strong consistency for large amounts of unstructured and semi-structured data across commodity servers. It is tightly integrated with Hadoop's MapReduce for distributed processing of large data sets.












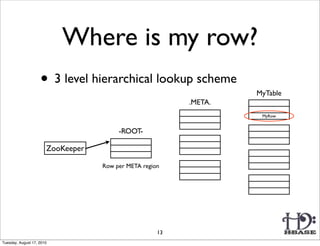
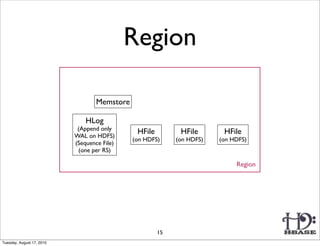
![Region
Memstore
HLog
(Append only
WAL on HDFS)
HFile HFile
(on HDFS) (on HDFS)
(Sequence File)
(one per RS)
Region
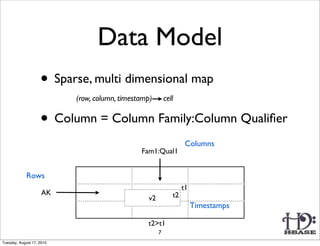
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-21-320.jpg)
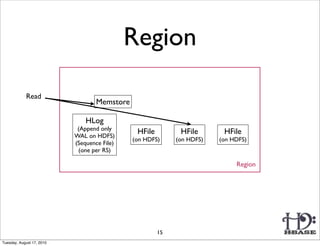
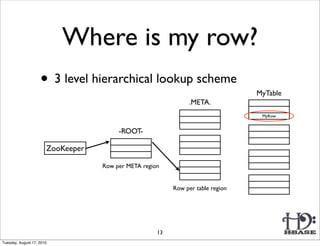
![Region
Write
Memstore
HLog
(Append only
WAL on HDFS)
HFile HFile
(on HDFS) (on HDFS)
(Sequence File)
(one per RS)
Region
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-22-320.jpg)
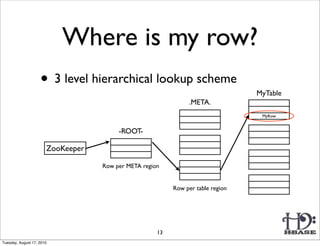
![Region
Memstore
HLog
(Append only
WAL on HDFS)
HFile HFile
(on HDFS) (on HDFS)
(Sequence File)
(one per RS)
Region
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-23-320.jpg)
![Region
Memstore Flush
HLog
(Append only Small
WAL on HDFS)
HFile HFile
(Sequence File)
(on HDFS) (on HDFS) HFile
(one per RS)
Region
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-24-320.jpg)
![Region
Memstore
HLog
(Append only Small
WAL on HDFS)
HFile HFile
(Sequence File)
(on HDFS) (on HDFS) HFile
(one per RS)
Region
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-25-320.jpg)
![Region
Memstore
HLog
(Append only Small
WAL on HDFS)
HFile HFile
(Sequence File)
(on HDFS) (on HDFS) HFile
(one per RS) Compaction
Region
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-26-320.jpg)
![Region
Memstore
HLog
(Append only
WAL on HDFS)
(Sequence File)
(one per RS) Compaction
Region
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-27-320.jpg)
![Region
Memstore
HLog
(Append only
WAL on HDFS)
HFile
(on HDFS)
(Sequence File)
(one per RS)
Region
HFile: Immutable sorted map (byte[] byte[])
(row, column, timestamp) cell value
14
Tuesday, August 17, 2010](https://image.slidesharecdn.com/hbasehadoopdayaug14seattle-100817022540-phpapp01/85/HBase-Hadoop-Day-Seattle-28-320.jpg)