Downloaded 43 times













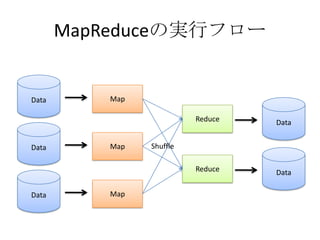

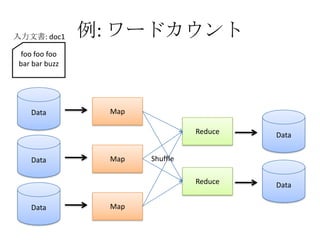
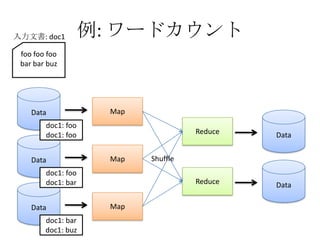
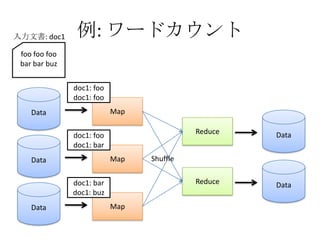
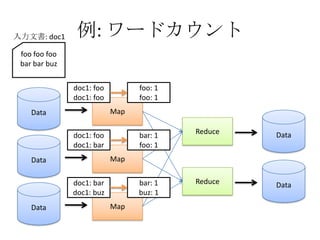
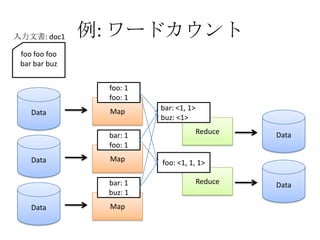
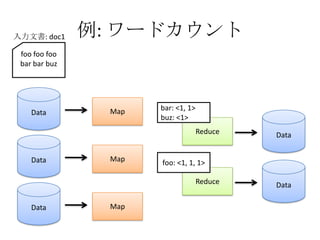
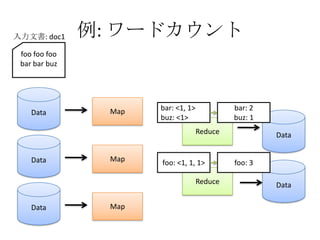
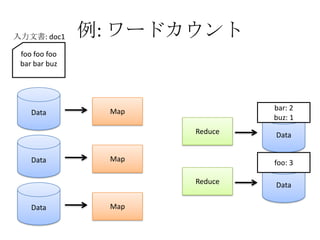
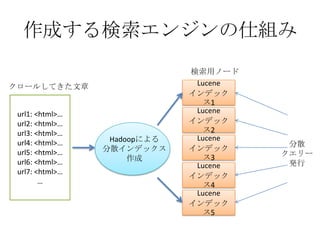
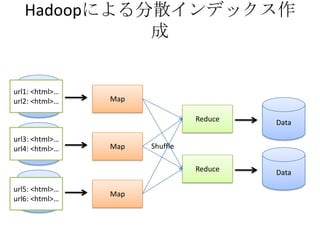
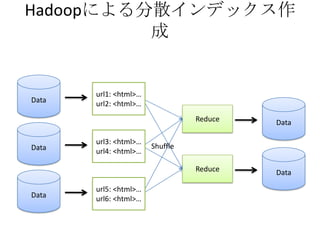
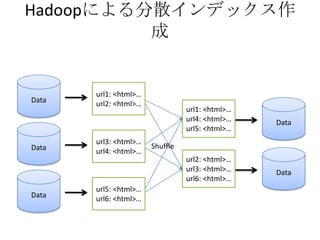
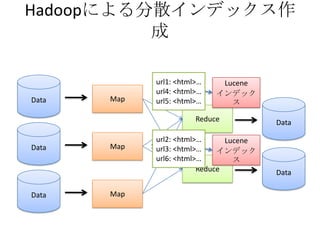
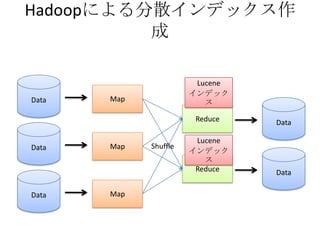
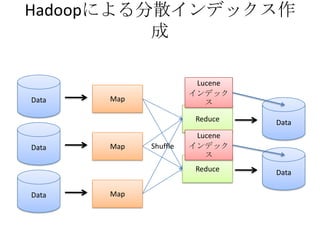
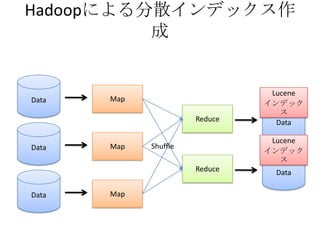




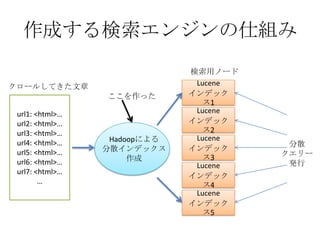





- The document discusses using Lucene and Hadoop to build large-scale search engines. Lucene is introduced as a Java-based search engine library, while Hadoop is a framework for distributed storage and processing of large datasets. - Code examples are provided for creating a Lucene index from files and for performing searches on the indexed data. - The presentation agenda indicates it will cover Lucene, Hadoop, building search engines with Lucene+Hadoop, and questions. Reference materials on Lucene and Hadoop are also listed.



























