Hakkımda
§ 9+ Java, Java EE
§ 3+ Hadoop,Spark,Pig,Hive,Oozie
§ Big Data Developer - Comodo
§ Blogger/Trainer - buyukveri.co
3.
İçerik
• Hadoop Nedir?
• HDFS Mimarisi
• YARN Mimarisi
• MapReduce Mimarisi
• Hadoop Kurulum Modları
• Hadoop Hangi Durumlarda Tercih Edilmemeli
• Cloudera Kurulumu
• Cloudera üzerinde örnek MapReduce uygulaması
• Pig ve Hive Nedir ?
4.
Hadoop Nedir?
● Büyükveri kümeleri ile birden fazla makinada paralel olarak işlem yapmamızı
sağlar
● Java ile yazılmıştır
● Açık kaynak kodludur
● Büyük verileri saklar (HDFS)
● Büyük veriler üzerinde paralel işlem
yapmamızı sağlar (MapReduce)
● Birden fazla makinede kaynak
yönetimini(ram,cpu) sağlar (YARN)
5.
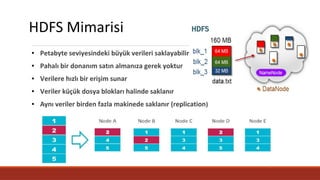
HDFS Mimarisi
● Petabyteseviyesindeki büyük verileri saklayabilir
● Pahalı bir donanım satın almanıza gerek yoktur
● Verilere hızlı bir erişim sunar
● Veriler küçük dosya blokları halinde saklanır
● Aynı veriler birden fazla makinede saklanır (replication)
6.
HDFS Mimarisi
● Enönemli bileşenler NameNode ve DataNode
● NameNode verilerin adreslerini tutar
● DataNode verileri saklar
● NameNode(Single point of failure)
7.
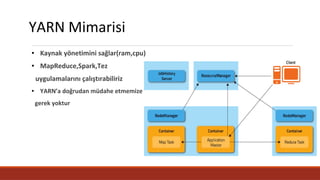
YARN Mimarisi
● Kaynakyönetimini sağlar(ram,cpu)
● MapReduce,Spark,Tez
uygulamalarını çalıştırabiliriz
● YARN’a doğrudan müdahe etmemize
gerek yoktur
8.
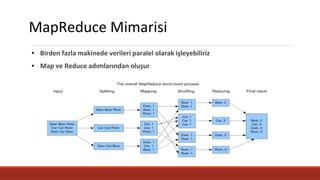
MapReduce Mimarisi
● Birdenfazla makinede verileri paralel olarak işleyebiliriz
● Map ve Reduce adımlarından oluşur
9.
Hadoop Kurulum Modları
●Standalone Mode
– Test veya debug amaçlı
– HDFS sistemini kullanamayız
● Single Node Cluster
– Tek bir makine üzerinde çalışır
– HDFS replication factor değeri 1 olarak ayarlanır
● Multiple node cluster
– HDFS replication factor değeri 1 değerinden büyük olabilir
– Birden fazla makine olduğu için Master ve Worker farklı makinelerde
bulunabilir
Apache Hive
● ApacheHive tabanlı SQL sorguları geliştirilebilir
select country,count(distinct user_id) from data
where log_date >= '2015-04-17' and log_date <= '2015-04-18'
group by country;