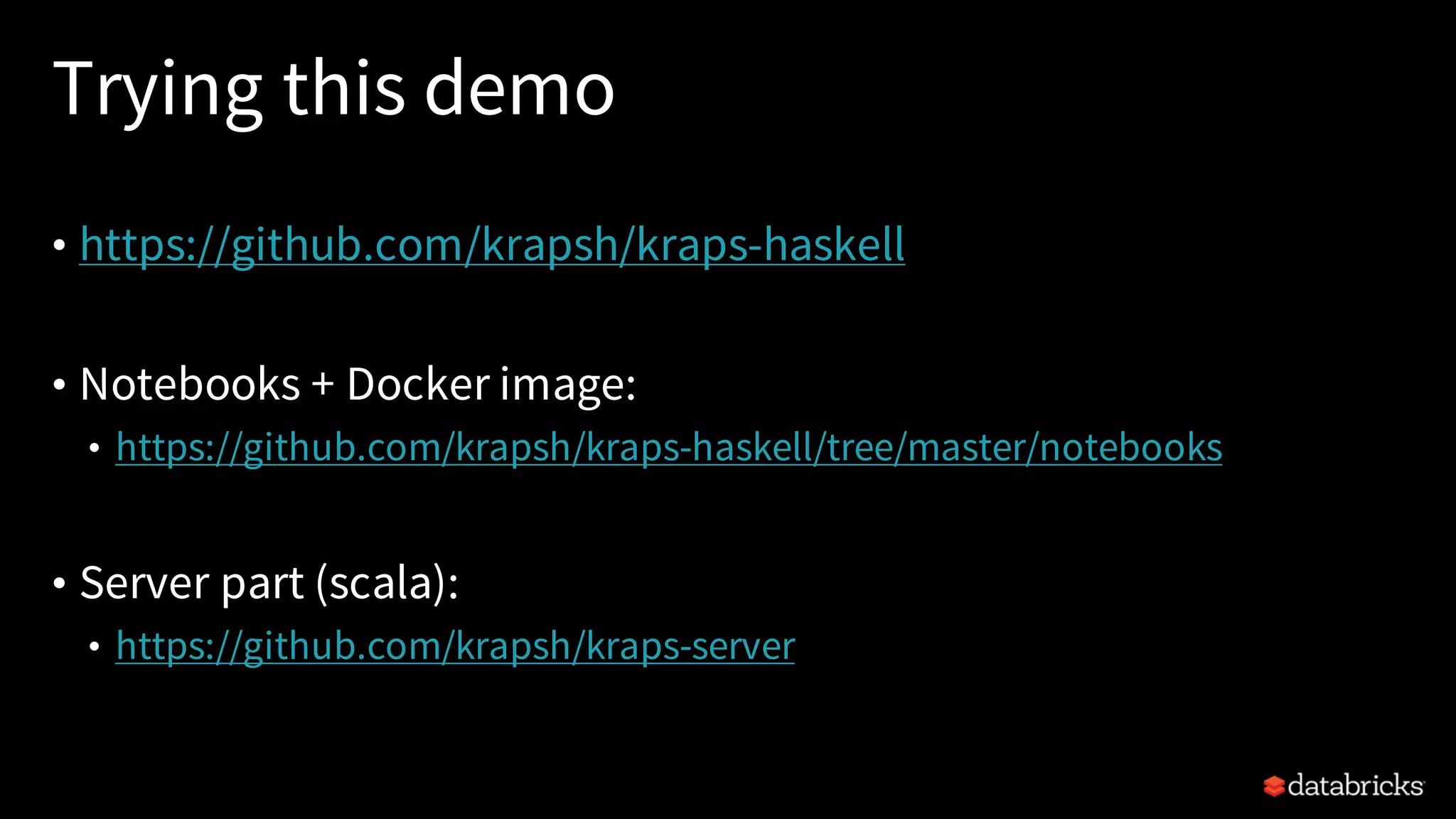
Download as PDF, PPTX
















![Theoretical foundations for a data system
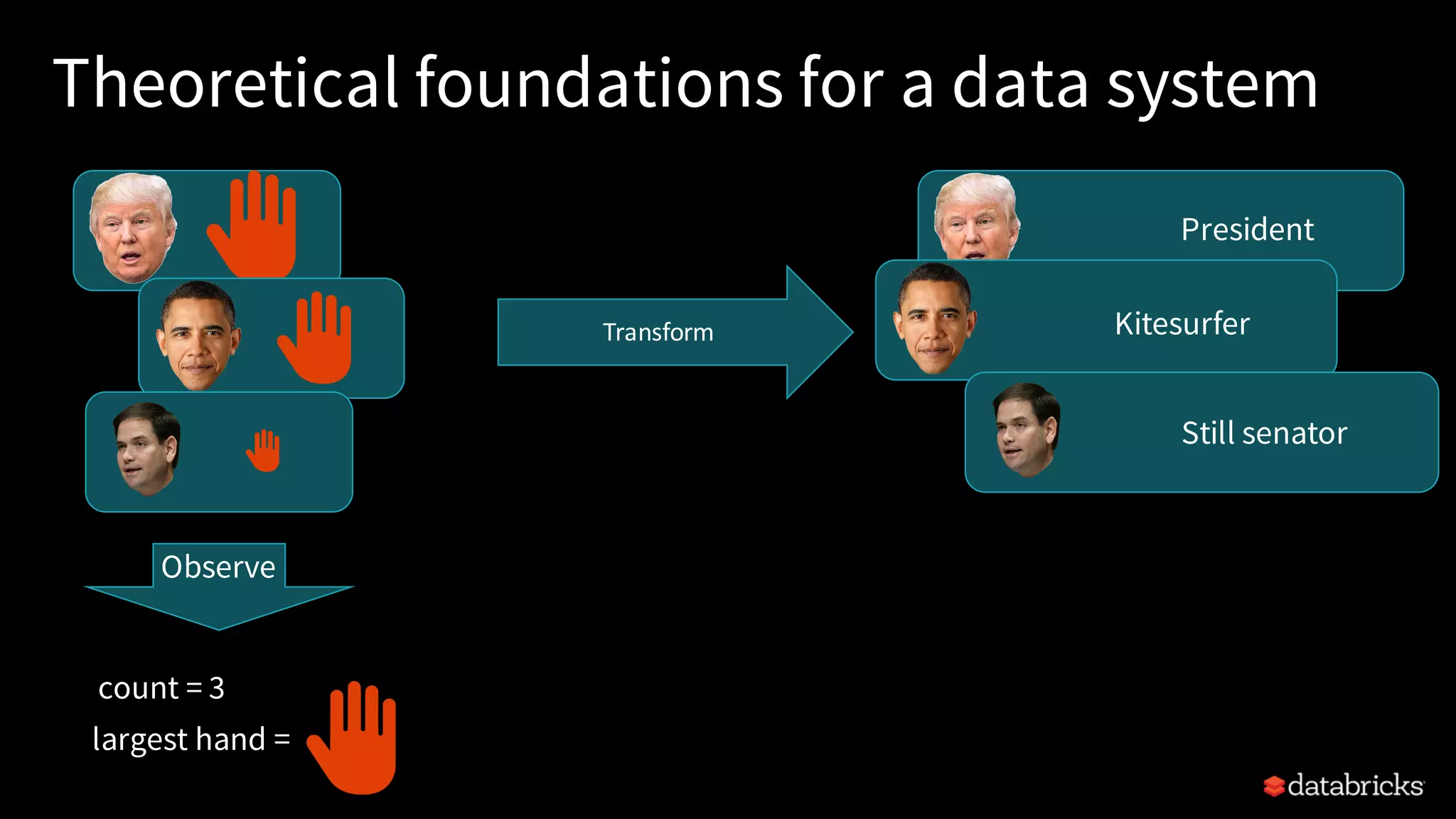
• A dataset is a collection of elements, all of the same type
• Scala: Dataset[T]
• Principle: the content of a dataset cannot be accessed directly
• A dataset can be queried
• An observable is a single element, with a type
• intuition: datasetwith a singlerow
• Scala: Observable[T]](https://image.slidesharecdn.com/17-04-25sparkmeetup-frompipelinestorefineries2-170512211233/75/From-Pipelines-to-Refineries-Scaling-Big-Data-Applications-19-2048.jpg)


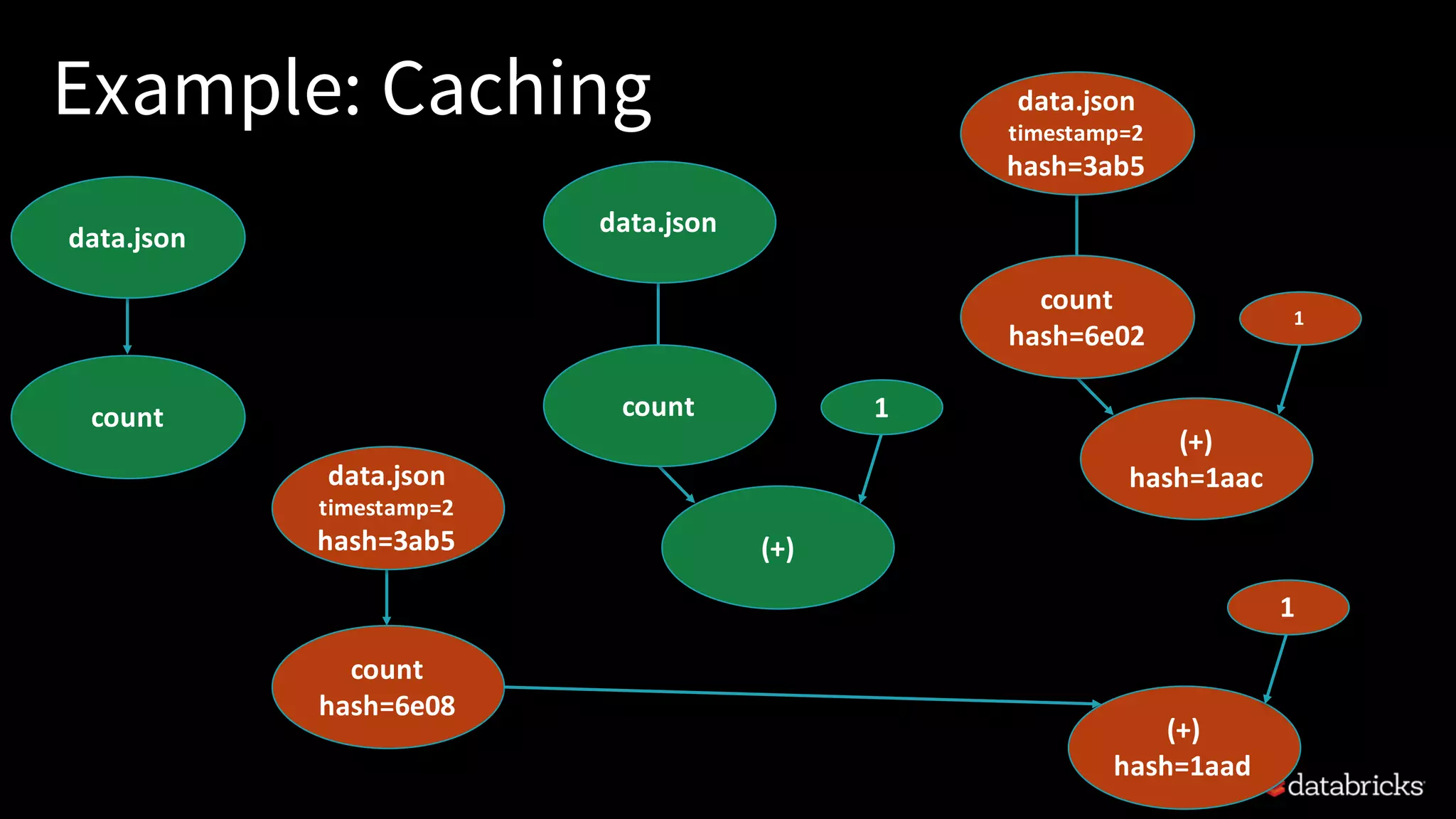
![Examples of operations
• They are what you expect:
• Dataset[Int] : a datasetof integers
• Observable[Int]: an observationon a dataset
• max: Dataset[Int] => Observable[Int]
• union: (Dataset[Int], Dataset[Int]) => Dataset[Int]
• collect: Dataset[Int] => Observable[List[Int]]](https://image.slidesharecdn.com/17-04-25sparkmeetup-frompipelinestorefineries2-170512211233/75/From-Pipelines-to-Refineries-Scaling-Big-Data-Applications-23-2048.jpg)










The document presents a discussion on the challenges and foundations of scaling big data applications using Apache Spark, as shared by Tim Hunter, a software engineer. Hunter emphasizes the future structural complexity of data processing systems and the importance of theoretical foundations to manage this complexity efficiently. Key topics include evolving data pipelines, programming models in Spark, and the necessity of determinism and performance optimizations in large-scale data processing.























































































