







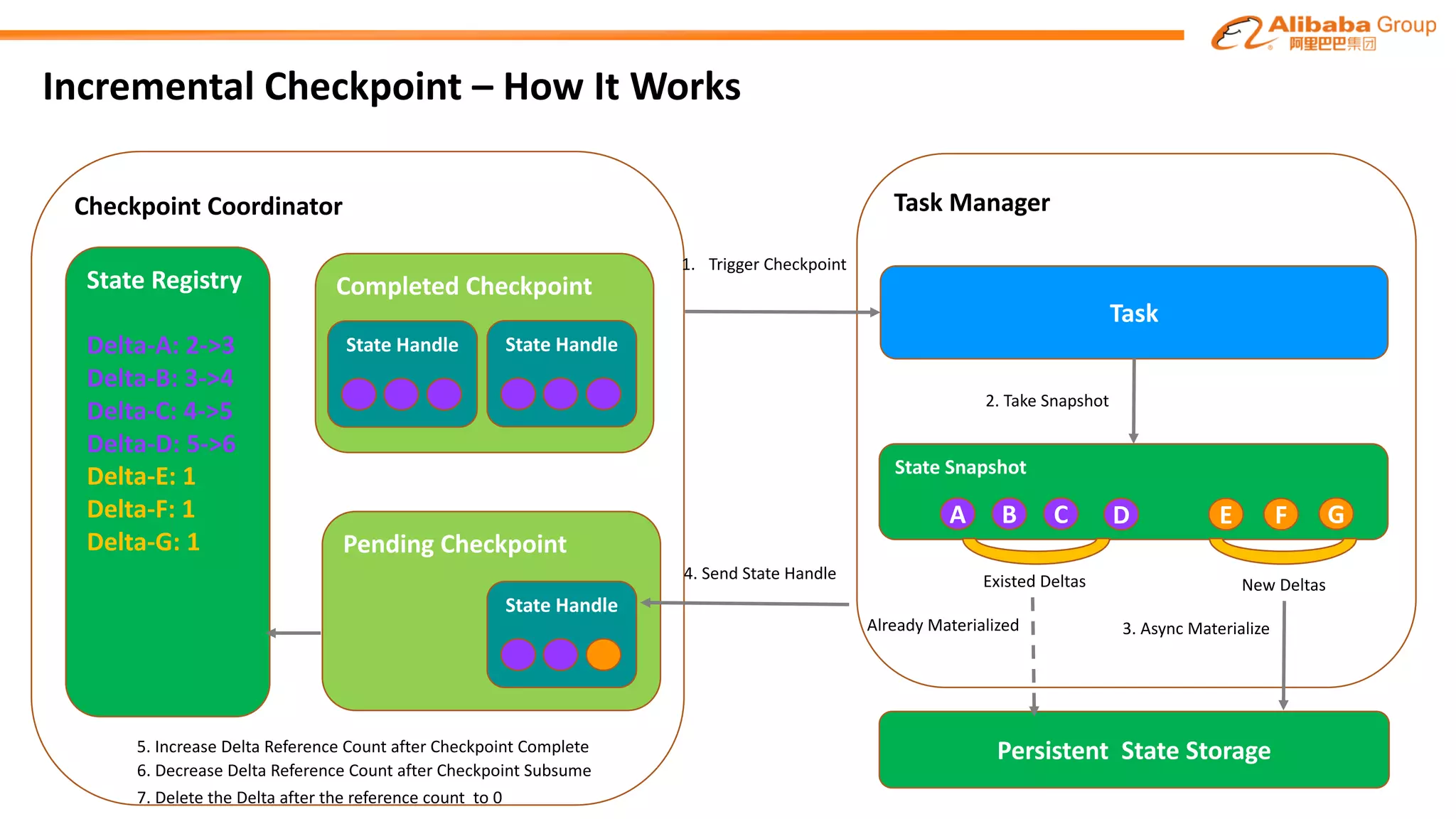
![Incremental Checkpoint - RocksDB State Backend Implementation
RocksDB Instance in TM for KeyGroups[0-m]
.sst .sst .sst
data
1.sst 2.sst 3.sst
chk-1
2.sst 3.sst 4.sst
chk-2
HDFS://user/JobID/OperatorID/KeyGroup_[0-m]
data
3.sst.chk-1 4.sst.chk-21.sst.chk-1 2.sst.chk-1
JobManager
Completed Checkpoint 1
State Handles
Completed Checkpoint 2
State Handles](https://image.slidesharecdn.com/flinkforwardsf2017fengwangzhijiangwangruntimeimprovementsinblinkforlargescalestreamingatalibaba-170414104635/75/Flink-Forward-SF-2017-Feng-Wang-Zhijiang-Wang-Runtime-Improvements-in-Blink-for-Large-Scale-Streaming-at-Alibaba-15-2048.jpg)

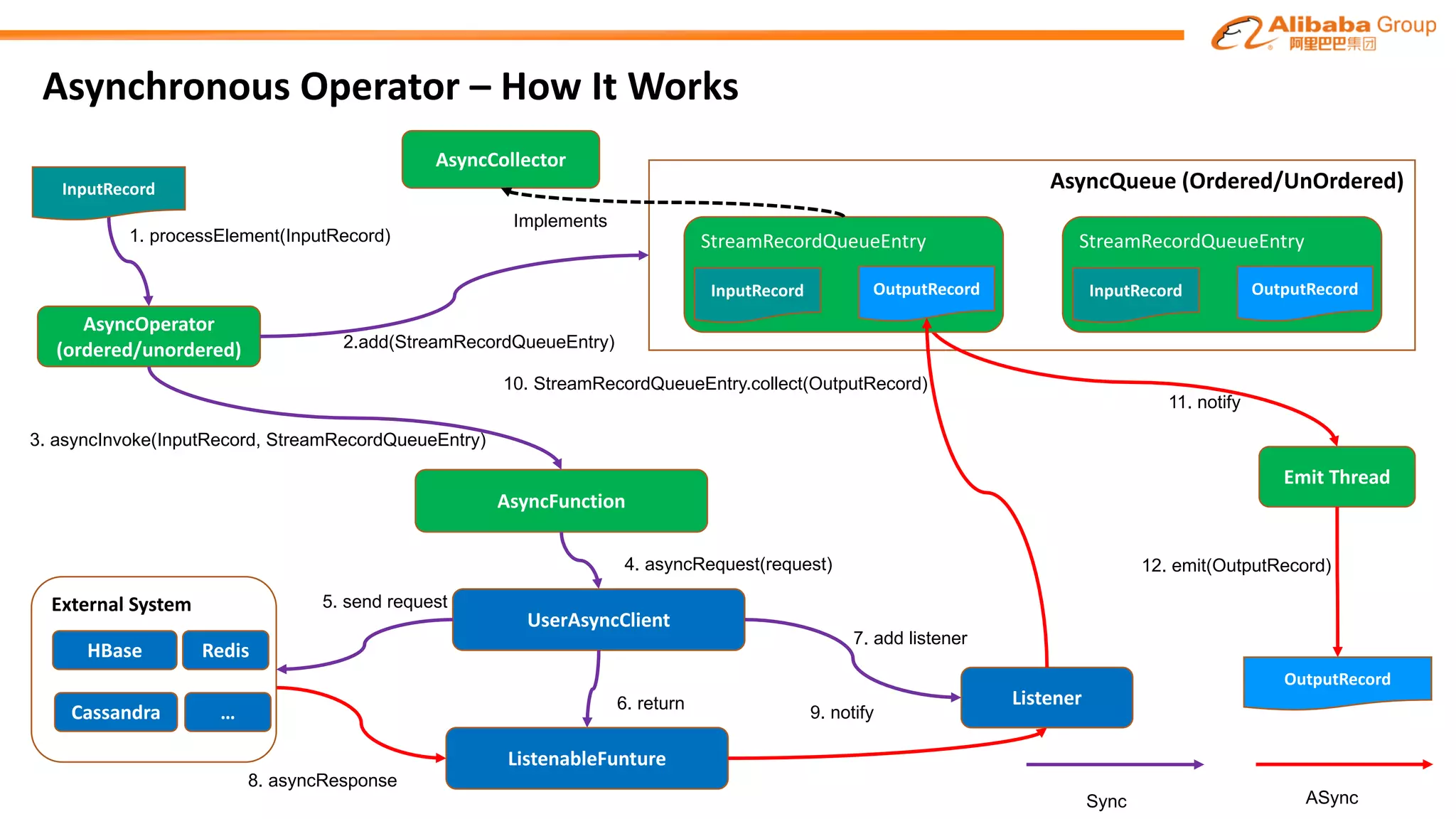
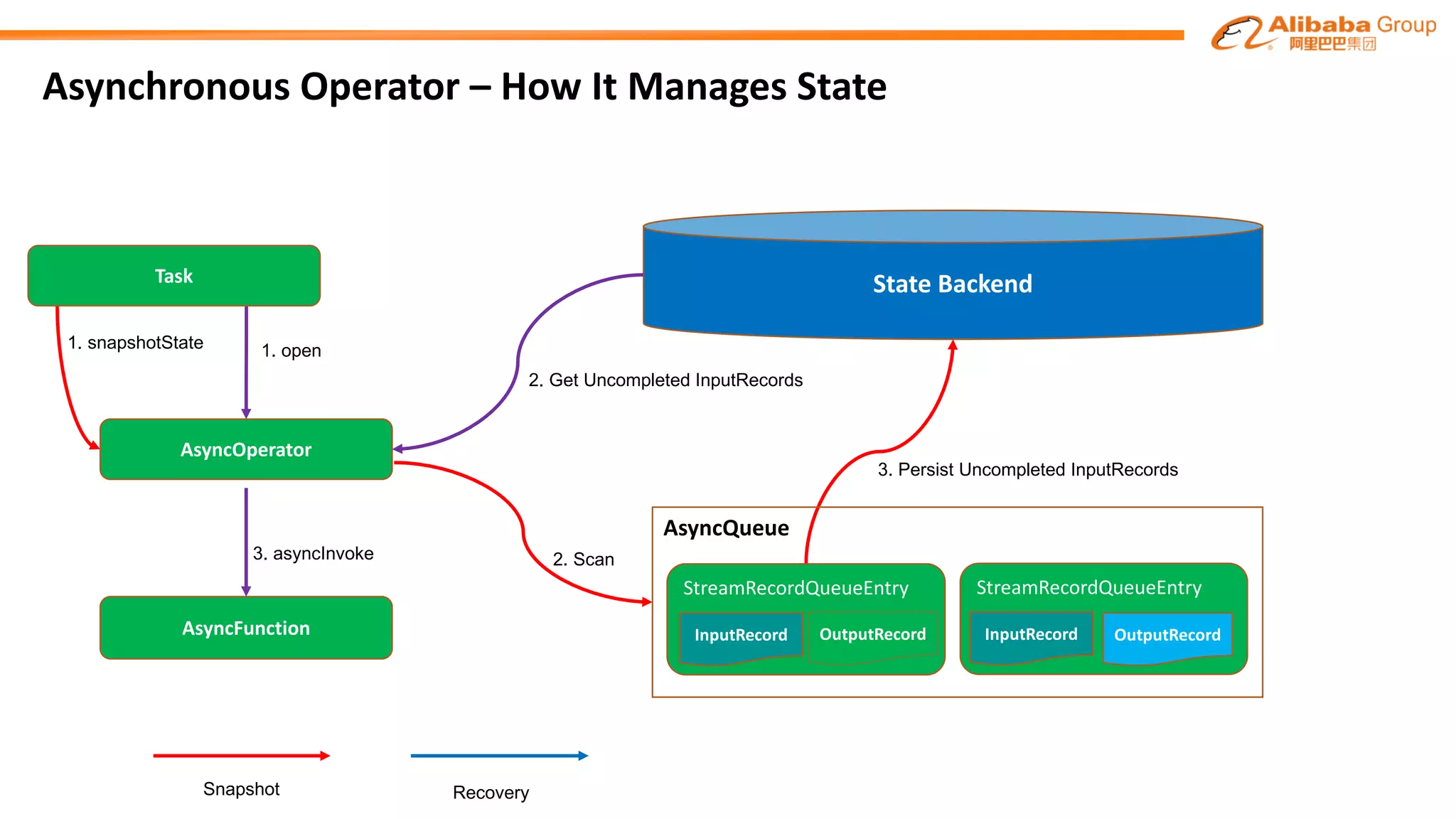

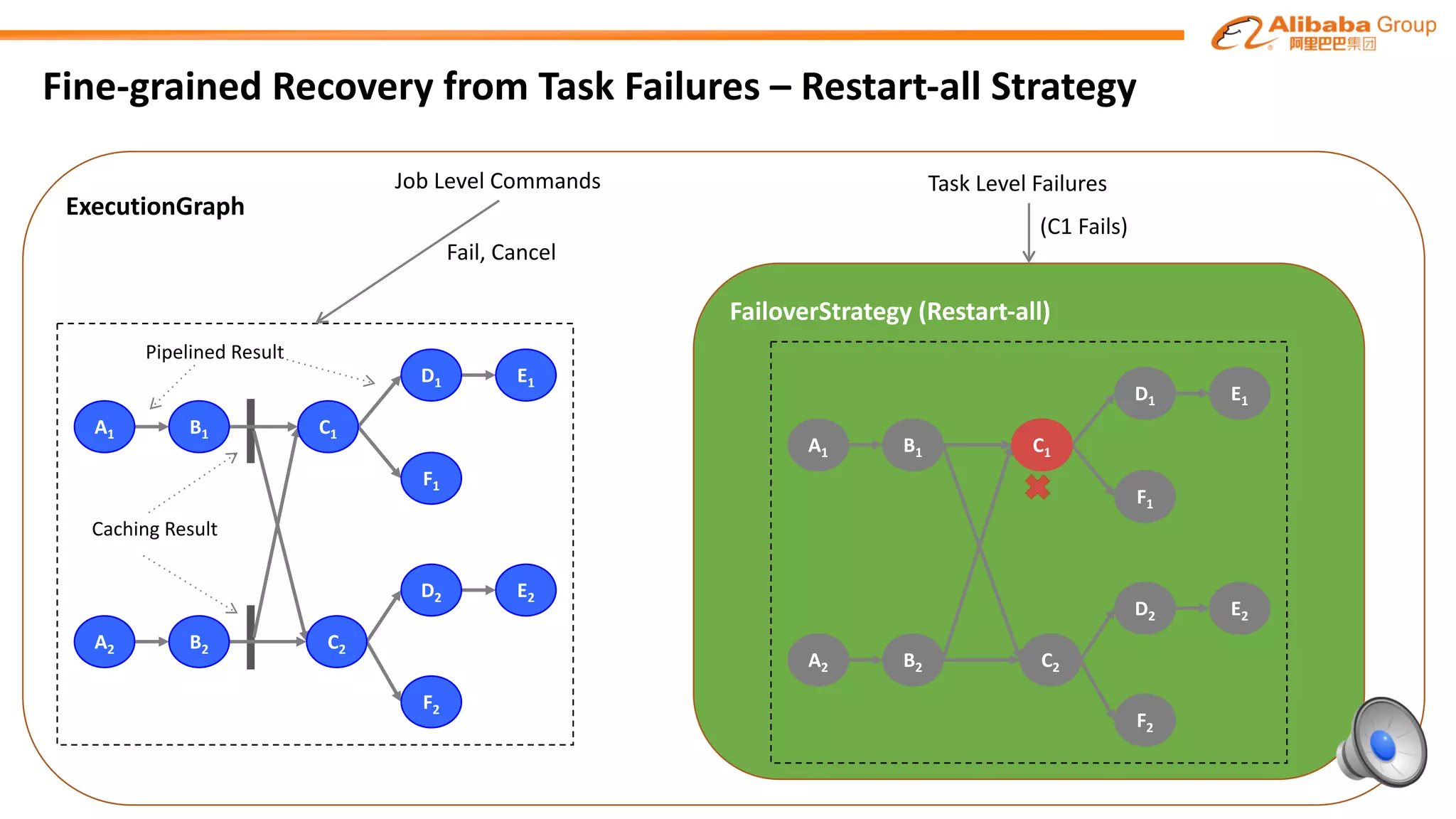
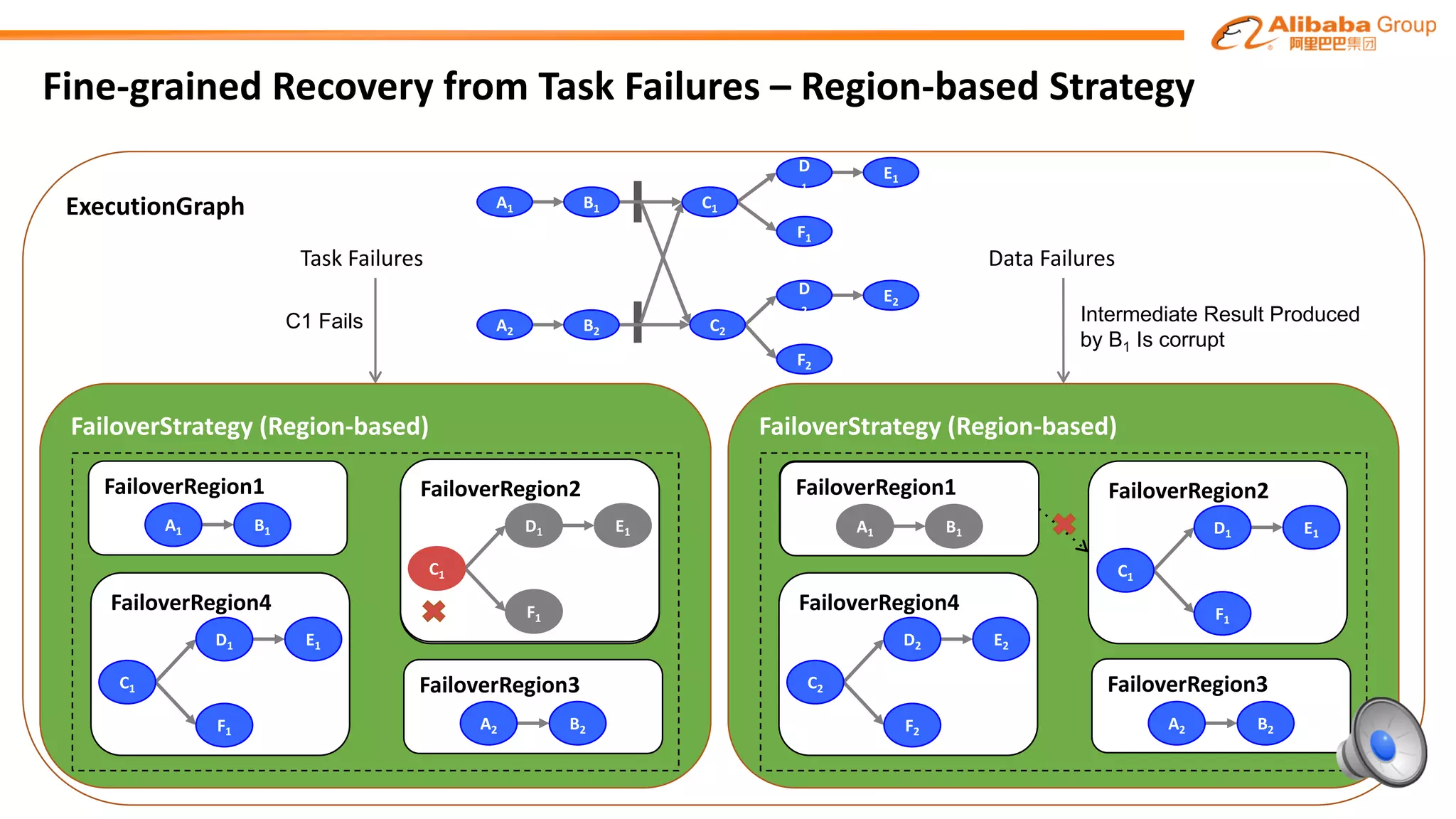

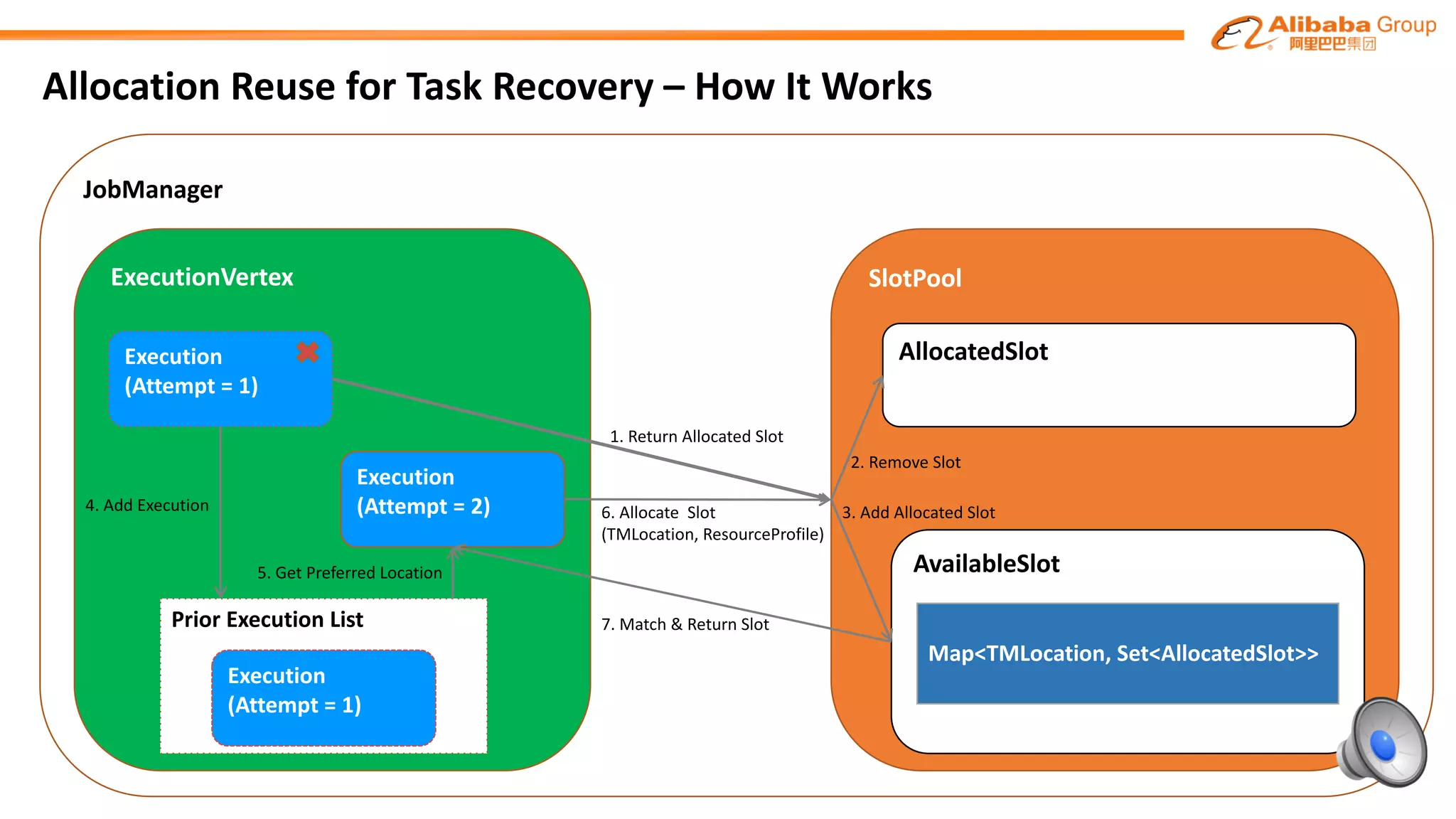

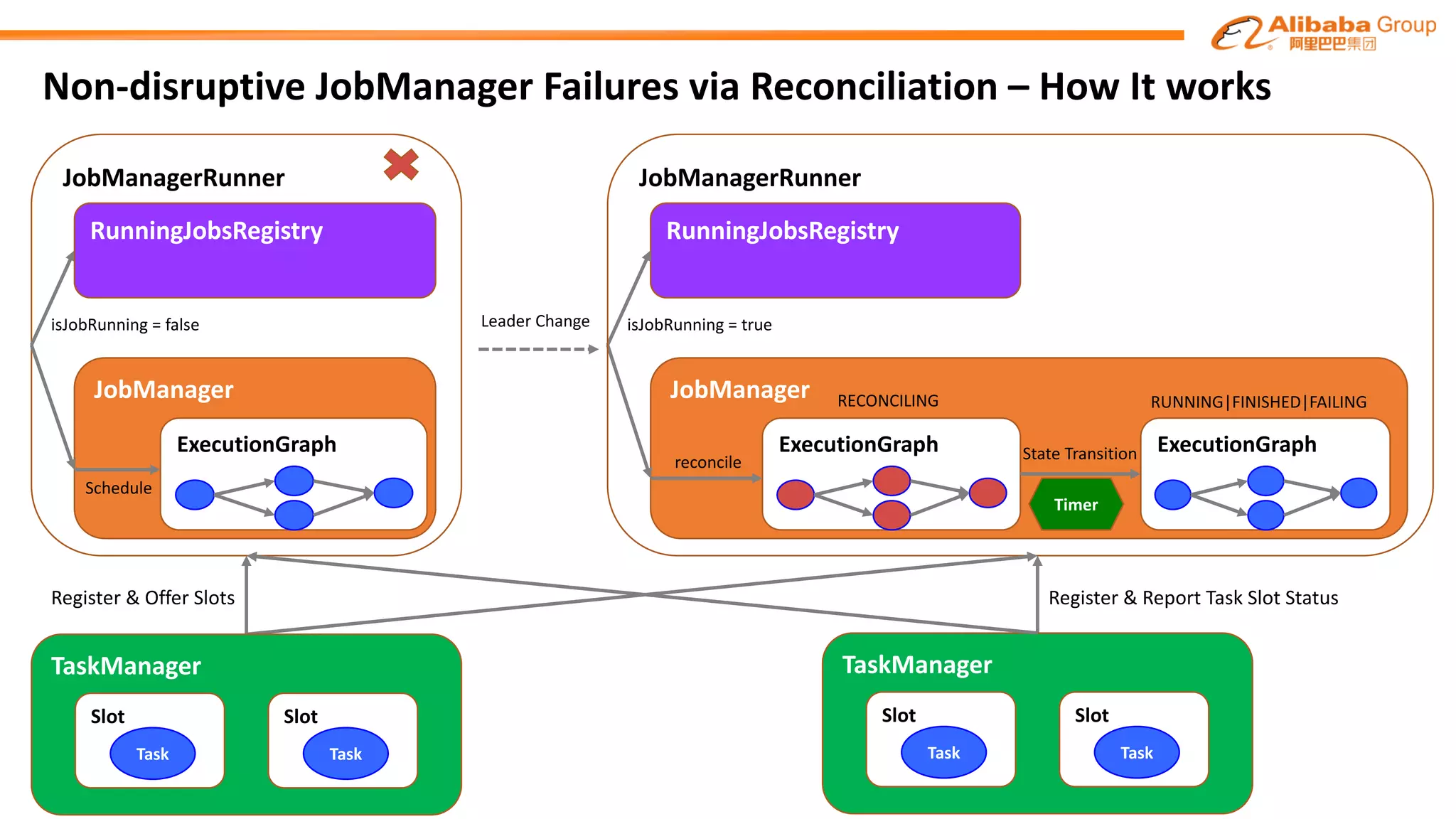




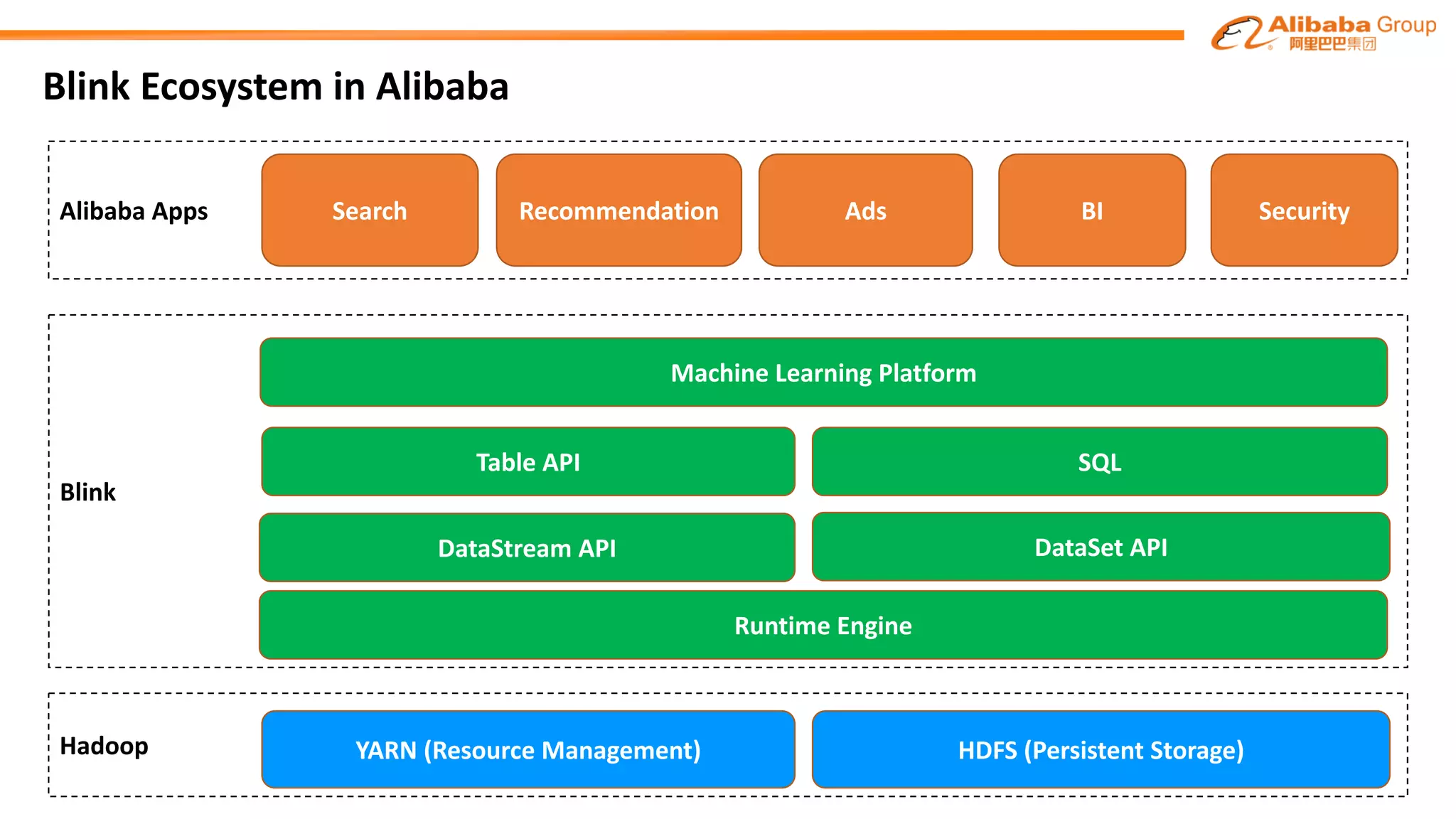
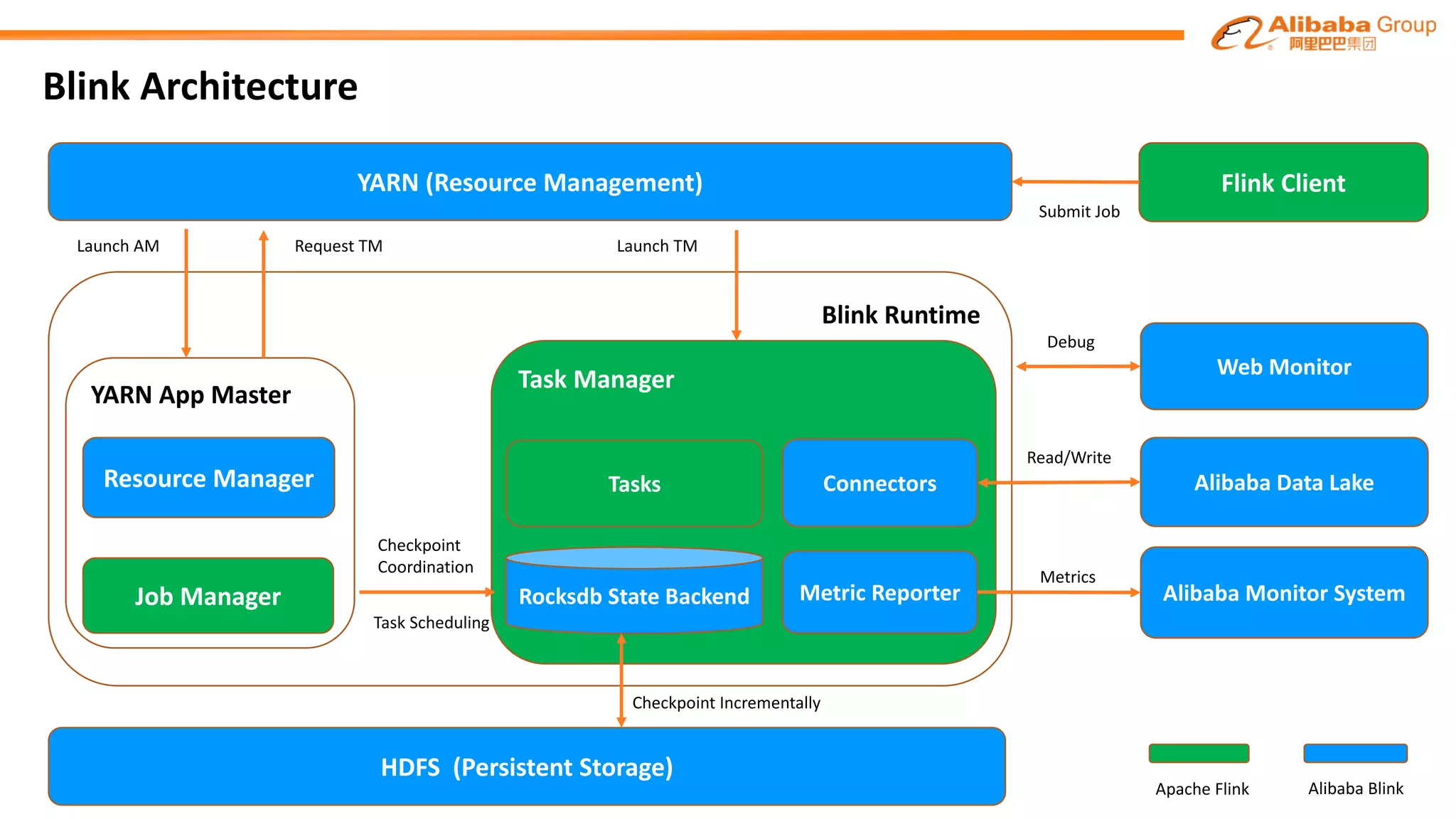
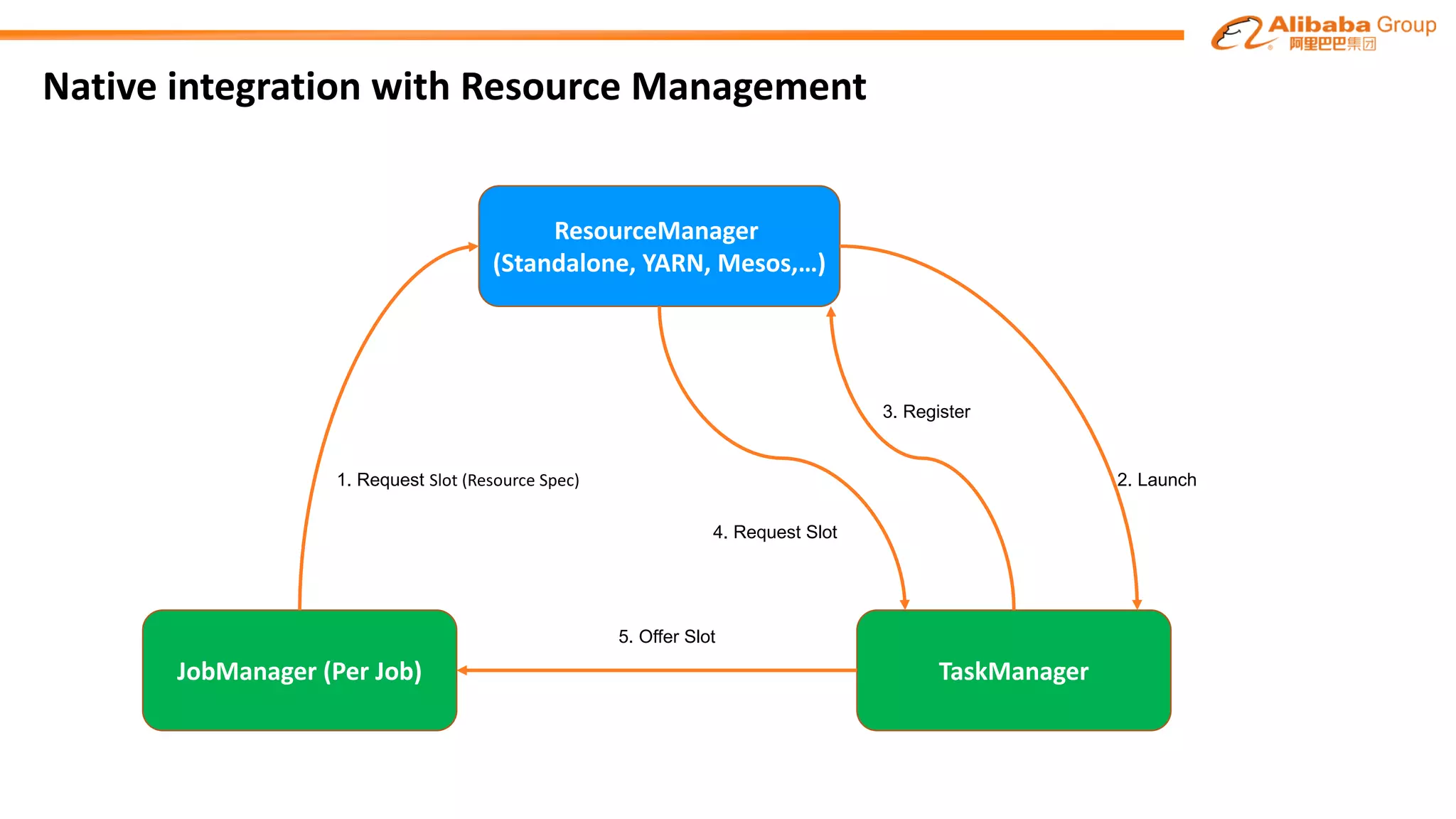
The document outlines improvements made to Alibaba's Blink, a version of the Flink streaming framework, aimed at enhancing its reliability and efficiency for large-scale applications. Key enhancements include incremental checkpointing, failover optimizations, and asynchronous operators, which collectively contribute to better performance in resource management and task recovery. Blink has been successfully deployed in production, notably during major events like China's Single's Day, significantly increasing performance and operational efficiency.




































































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
